P-stage2 [Day3]
수업내용
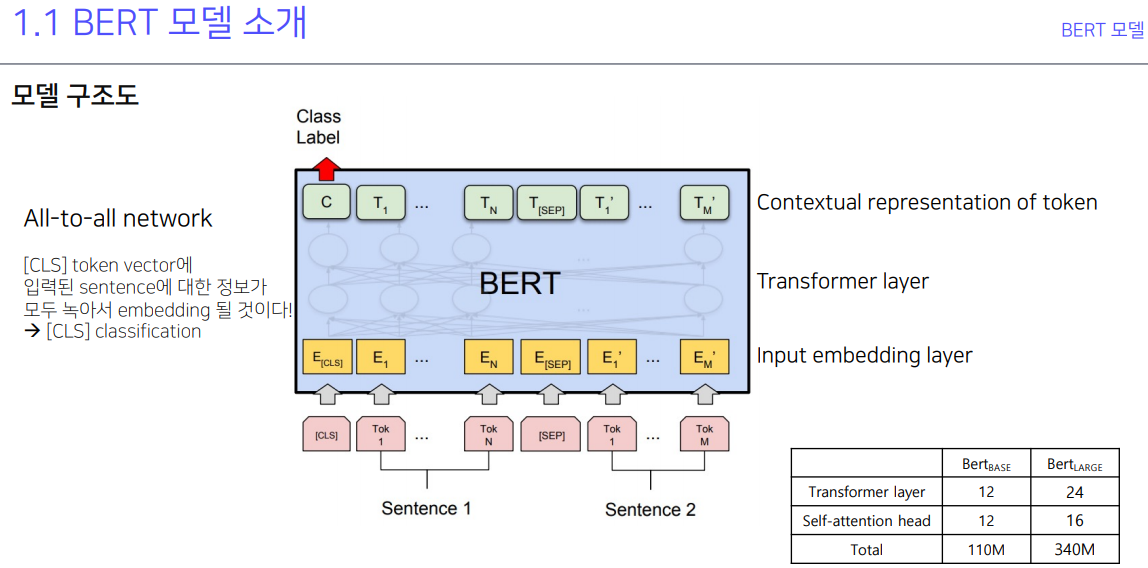
GPT-2는 다음문장 예측. BERT는 문장 사이에 mask가 씌워있을 때 맞추는 예측. 애초에 encoding과 decoding이 decoding은 encoding된 내용물을 완전히 원본으로 복구하는게 목적.
두 문장 두고 두 문장이 연관성이 있는가 없는가를 CLS에 넣어서 알려주고 그걸 학습함. 저게 기본이고 단일 문장 분류, 두 문장 관계 분류, 문장 토큰 분류, 기계 독해 정답 분류 등의 여러 NLP 실험들을 했다.. 하는데 질답이 가능한 이유는 질문을 입력, 답을 출력으로 놓고 계속 학습하다 보면 어디서부터 어디를 봐야할 지를 attention으로 알게되기 때문...
NLP의 성능을 측정하는데 대표적으로 쓰이는 데이터셋들 GLUE dataset과 SQuAD 등등..
한국어용 koBERT.
어절단위(형태소 단위), 음절단위로 tokenizing. '~는' 도 떼어내서 내놓을 수 있기 때문에 결과가 음절이 더 좋더라.
양이 너무 많은데 모두 다 중요하다. 그냥 pdf 열어서 정독하자.
실습
Day3_실습자료0Huggingface.ipynb의 사본
기본적인 사용방법.
Day3_실습자료1BERT_유사도_기반_챗봇.ipynb의 사본
코사인 유사도를 활용한 챗봇 만들기. 오.. 신기하다.
과제
Day3_[CLS] token의 embedding을 활용해서 챗봇을 만들어보겠습니다.ipynb
코사인 유사도를 활용하여 사전에 작성된 질답 데이터의 답변을 내놓는 방식.
피어세션
한국어로 pretrained된 모델을 쓰자.
electra 보다 koBERT가 제일 잘 나왔다.
데이터가 적어서 val이 있으면 안되는듯. 너무 심하다. 할거면 추가해야 됨. 데이터 늘려주는 에스모트? 도 안됨. 진짜 직접 데이터를 만들어야 할듯. 최적화 수치, 방법들 찾고 마지막에 앙상블 하는게 나을듯. teacher student 모델도..
config 로 설정되어있는건 fc를 사용하는건데 이거 말고 bertclassification을 사용함. koBERT말고 그냥 BERT도 사용해보고. config 안넣고
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
지금 있는건 한국어 3000개 밖에 안되는 bert-base-multilingual-cased.
영어로 된건 기본으로 있는 config 가 되는데 한국어로 되건 config로 하면 잘 안되는듯. autotokenizer로 하면 tokenizer알아서 잘 찾아준다. config 직접 가져와서 사용하는게 나은듯.
transformer보면 load best model이 있음. docs보자.
config는 말그대로 base라서. BERT에 기반으로 만들어진거라 koBERT엔 안맞을 수 있으니까 다르게 써야 하는듯.
이론에서 배운 표에 나온것만큼 나와야 세팅이 잘된 것.
from_pretrained(, num_classes=42)로 인자 안에 넣어야 한다. default는 아얘 fc가 없음. num_classes 해줘야 fc layer 만들어주는것 처럼 생각하면 됨.
stratifiedsufflesplit, stratifiedkfoldsplit
토론게시판에 외국어 번역해서 쓰겠다는 사람도 있음. augmentation인데 번역번역 과정을 거쳐 만들겠다는..
또 entity를 이용해서 새로운 문제를 만들어서 하는 사람도 있는듯.
행동
Django 공부 좀 하고 어제 하던 알고리즘 문제 다시 보고 있음. 근데 내일 또 봐야 할듯.