P-stage3 [Day4]
수업내용
U-Net은 왜 나왔는가?
의료부분에서 사용할려니 데이터가 너무 적고 세포들도 막 밀집해있다보니 잘 안됨.
그래서 입력 이미지의 전반적인 특징 추출(Context 포장) 차원을 줄이는 Down-sampling과 Localization을 가능하게 함 차원을 늘리는 Up-sampling 작업 얕은 Layer의 Feature Map 결합 부분을 합쳐 U-Net을 만들었다.

같은 계층(level) 의 Encoder 출력물과 Up-Conv의 결과를 concat으로 붙여주는 것이 특징이다. 또 down sampling할 때 padding을 안줘서 이미지 사이즈가 계속 감소해서 encoder와 decoder가 같은 level이라도 사이즈가 달라지는 문제는 그냥 crop으로 해결함.
U-Net에 적용된 다른 Techniques들은 물체를 뭉게지게 하는 Random Elastic deformations을 통한 Augmentation, 겹치는 부분이 없게 한 Sliding Window가 있다. 또 신박했던게 인접부분을 분리하기 위해 거리에 다른 loss 가충치를 만든 부분인듯.

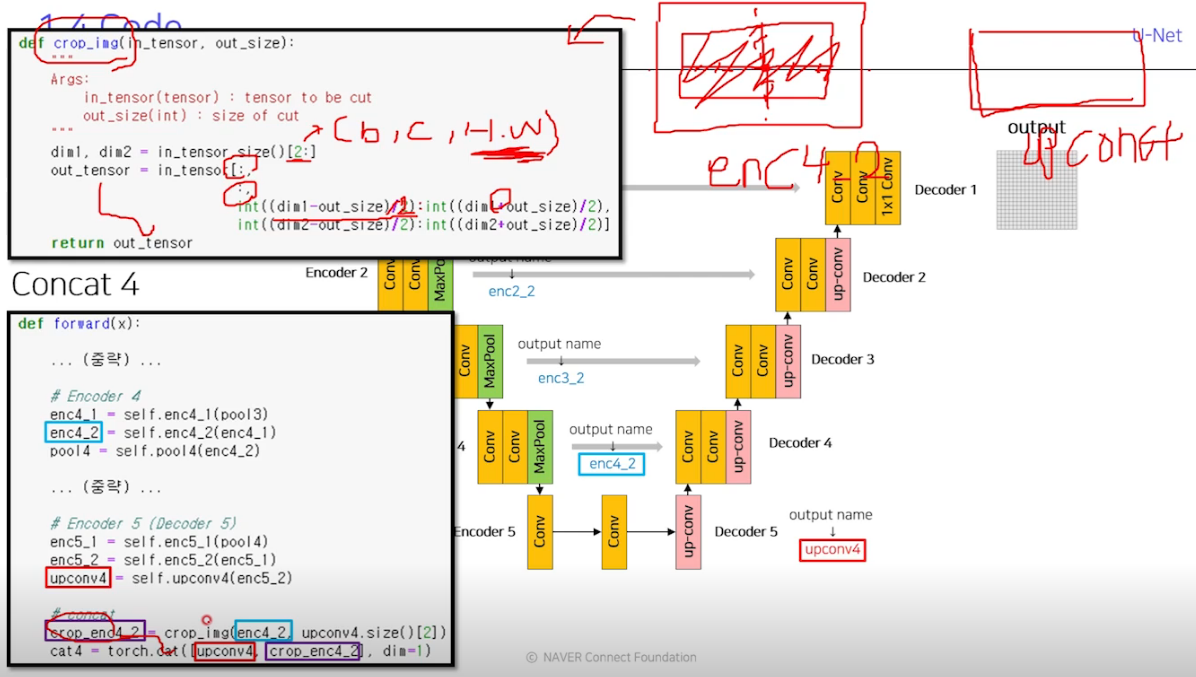
자세한 모델 코드 설명은 pdf
한계점으로는 level이 무조건 4로 고정이라 데이터셋 마다 최고 성능을 보장하지 못하고, skip connection을 단순한 concat로 했단 점임. 그래서 U-Net++가 나왔다.
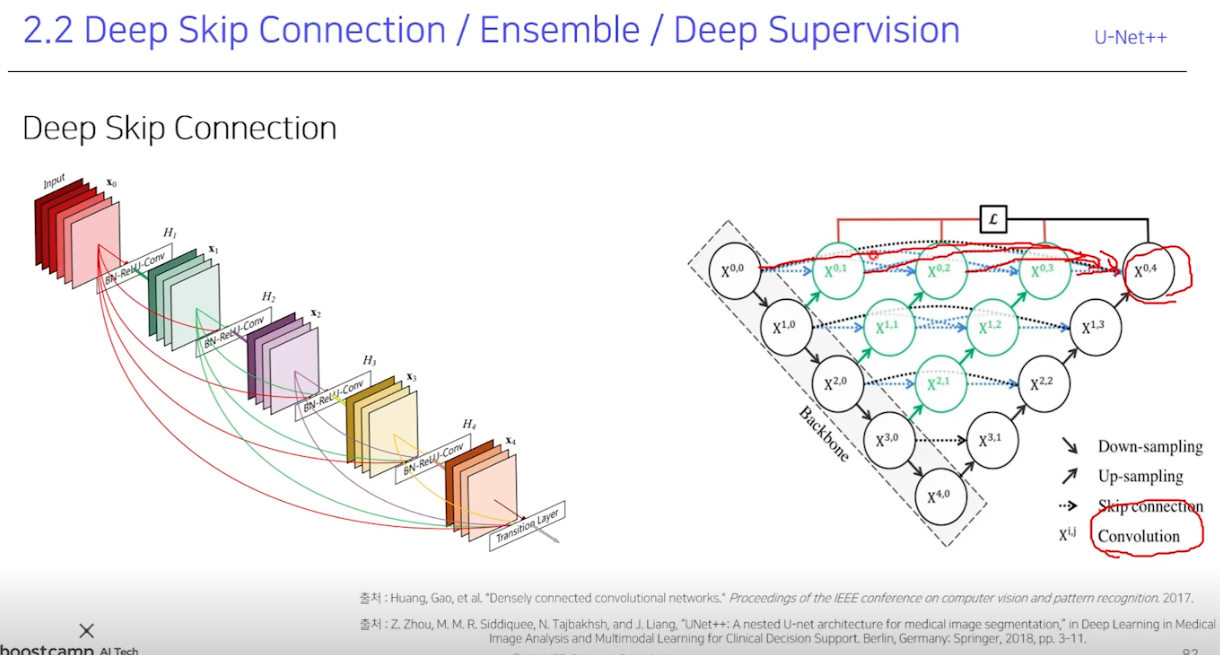
그냥 싹다 연결해준다. 같은 레벨은 이전것들까지 모두 concat으로 skip connection해주고 다른 level은 scale sampling을 해줘서 맞춰준다. 이렇게 하니까 level 1, 2, 3, 4간에 앙상블하는 효과도 생기고 성능도 그냥 U-Net에서 따로 해서 더하는 항상블보다도 향상. loss도 Deep Supervision이라는 신기한 loss를 쓴다.

한계점은 파라미터가 너무 많고 connection이 너무 많이 메모리를 많이 잡아먹는다. 또 Encoder-Decoder 사이에서 동일한 크기를 갖는 Feature map 에서만 connection이 일어남. 즉, Full Scale에서 충분한 정보를 탐색하지 못해 위치와
경계를 명시적으로 학습하지 못함.
그래서 또 나온게 U-Net 3+

그냥 싹다 직접 이어준다.
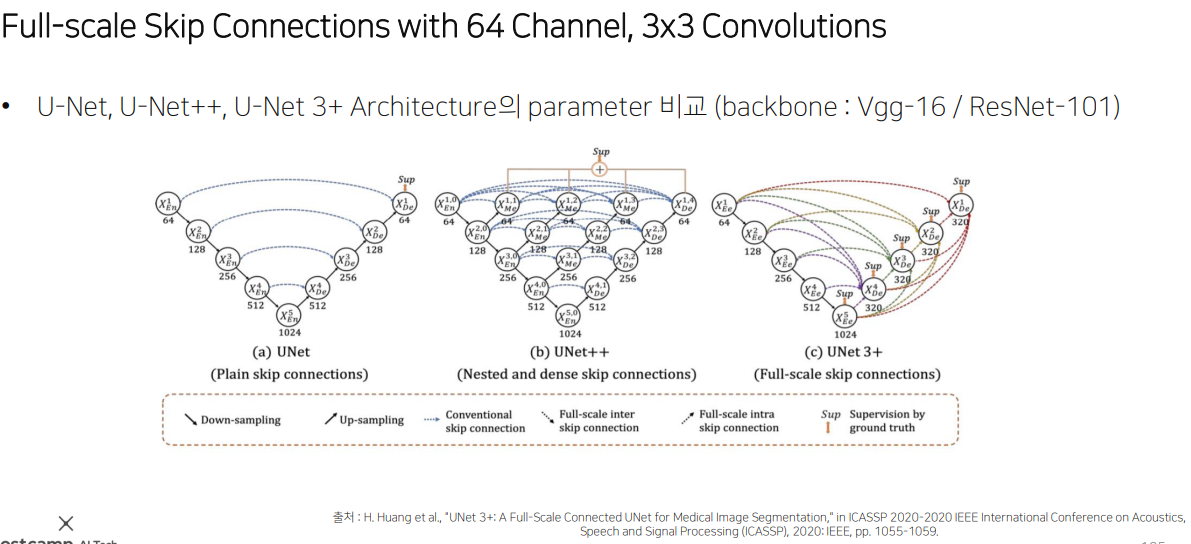

파라미터 수도 줄었는데 성능은 높아졌다. 차이가 느껴지십니까?
U-Net 3+에서 적용된 기술들도 있다. CGM이랑 Full-scale Deep Supervision(loss function)

GCM은 혼자 따로 떨어져서 노이즈처럼 점으로 물체라고 인식하는 건데 물체가 아니라고 확실히 못박을라고 아예 classification 하는 layer를 만듬.

Full-scale Deep Supervision (loss function)은 성능 잘 나온 3가지 loss function들을 결합한거. Focal Loss : 클래스의 불균형 해소, ms-ssim Loss : Boundary 인식 강화, IoU : 픽셀의 분류 정확도를 상승.
결론은 이게 현재 최신기술보다 좋은 성능을 내고 있다.
U-Net이 사전 학습된 모델을 backbone으로 해서 만든거니까 다른 backbone으로 redisualnet 붙인거, mobilenet 붙인거, efficientnet 붙인거 다 변형버전이 있다.
피어세션
https://pytorch.org/vision/stable/_modules/torchvision/models/segmentation/segmentation.html
deeplab v3 + resnet101. 0.51 나오는듯. epoch 15.
efficient unet. 0.34
이미지 불러올 때 float32로 변경하니까 깨지는 것 같다. 이미지 normalize 도 안한다. 확인해보기.
데이콘 우승한거 보니까 hrnet 좋은듯. 근데 pretrained 된게 image classification으로 한거라서 앞에꺼만 뜯어서 사용해야 할듯.
segmentation argument 할 때 mask는 보통 같이 되도록 만든것 같은데 bounding box는 좀 아닌듯. 다음 할때 조심해서 봐야할 듯
efficient unet b7. 0.45. unet++도 0.45. deeplab 써서 0.58.
smp에 있는 deeplab v3는 수정해서 사용해야 할듯.
Papers with Code - Semantic Segmentation
목표
수업 들어보니 내일 더 좋은 모델 알려주고 baseline code 주는듯. 그래서 augmentation과 외부 데이터를 활용하는 방법쪽으로 알아봐야겠다.
점프 투 장고.
행동
내가 모듈화해서 만든거에 소소한 에러들 (중복코드 등) 고침. val mIoU계산할 때 batch size 단위가 아닌 전체단위로 바꿈.
정규화 시키니까 epoch 1일 때 loss는 늘었는데 val mIoU는 0.1611 → 0.1672 로 상승. PB mIoU도 0.4023 → 0.4096 으로 늘었다. 근데 지금 val mIoU가 0.1가량 작게나오는 것 같다. val 계산하는걸 batch size가 아닌 전체로 바꾸는 과정에서 뭔가 잘못 짠듯.
뭘 추가하려고만 하면 오류가 계속 떠서 진행이 안된다.
회고
refresh가 필요하다.