
P-stage3 [day2]
수업내용
object detection을 위한 library가 Detection2와 mmdetection이 있지만 mmdetection이 더 많은듯.
Detection2
- Facebook AI Research
- pytorch
- 2 Stages
MMDetection
- OpenMMLab
- Pytorch
- 2 Stages & 1 Stages
- Pipelining
MMDetection은 pipelining에 중점을 둔 library라서 모델 구조를 바꿔끼는게 편리하게 구성되어 있음.

그런데 backbone에 보면 Neck이란게 있다. 이게 뭐고 왜 이걸 중간에 꼭 거쳐야만 하는가.
cnn을 너무 많이 거치면 큰 물체는 감지 잘하지만 detail한 작은 물체들은 잘 감지 못하는 문제가 발생해서 중간과정을 하나 만든거고, 이 Neck에 대해서도 여러 모델 방법론들이 있음. 우린 여기서 FPN, PANet, RFP, ASPP, BiFPN 에 대해 살펴볼거다.
FPN( Feature Pyramid Networks) 의 경우 bottom-up하면서 중간 중간의 cnn들의 정보를 top-dwon을 수행하며 집어넣고 있음. 즉 bottom에서 얕은 cnn은 작은 물체에 대한 정보도 가지고 있으니까 이걸 활용하고 싶어서 top-down을 만들어 넣는다.
그래서 여러 prediction을 이용해서 모든 부분에 대해 탐지함.
반면 PAN(Path Aggregation Network) 같은 경우 FPN에 문제가 있다고 들먹이며 마지막 cnn에선 작은 정보가 없다고 예측 결과를 얇은 층의 cnn에 다시 넣는다. 4장밖에 안된다고 함.
짚고 넘어가야 될건 FPN이 더 좋다, PAN이 더 좋다가 아니라 데이터나 모델, 상황에 따라 바뀔 수 있음.

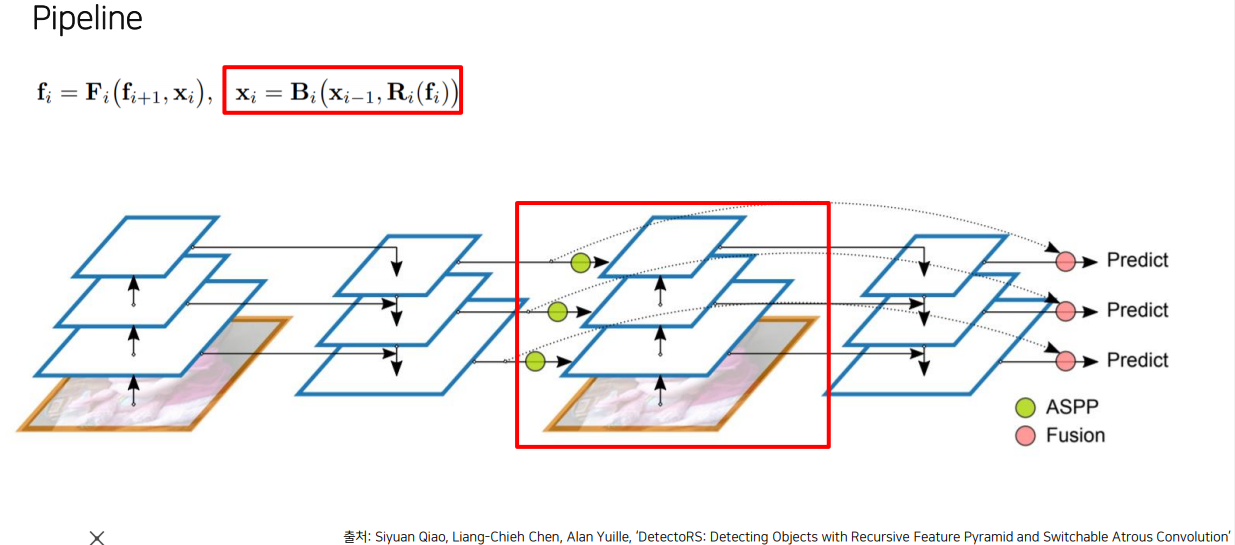
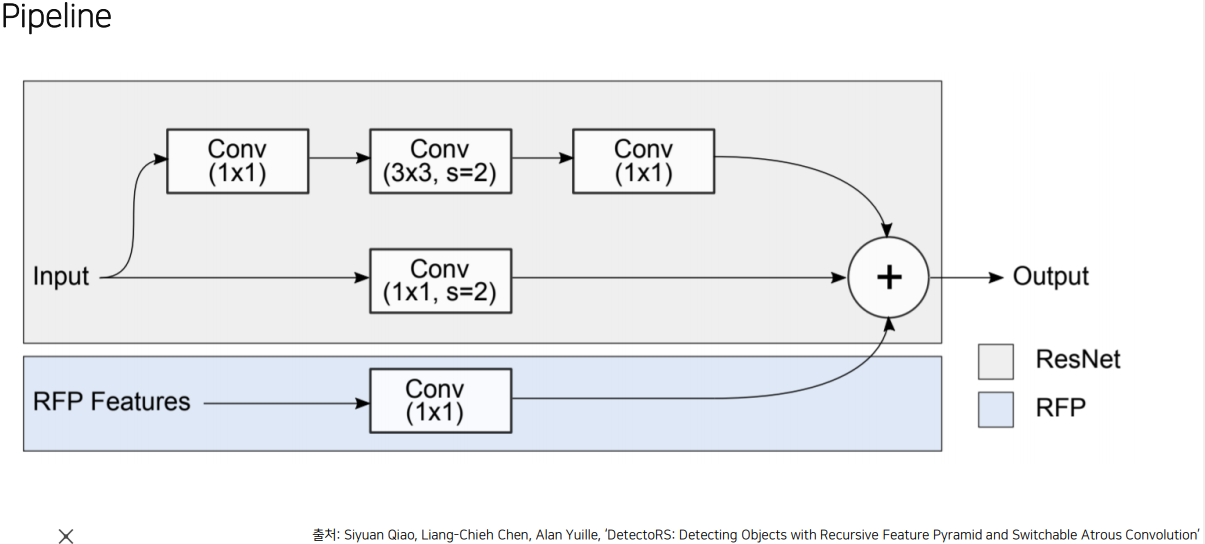
RFP(Recursive Feature Pyramid)는 bottom-up, top-down 해서 나온 결과를 다시 bottom-up에 넣고.. 를 반복하다보면 더 좋아지지 않을까 하는 발상. 다시 넣어줄 땐 weight를 설정할 수 있도록 ASPP를 설정함. 그냥 일반 입력값에 RFP Features가 추가된다고 보면 된다.
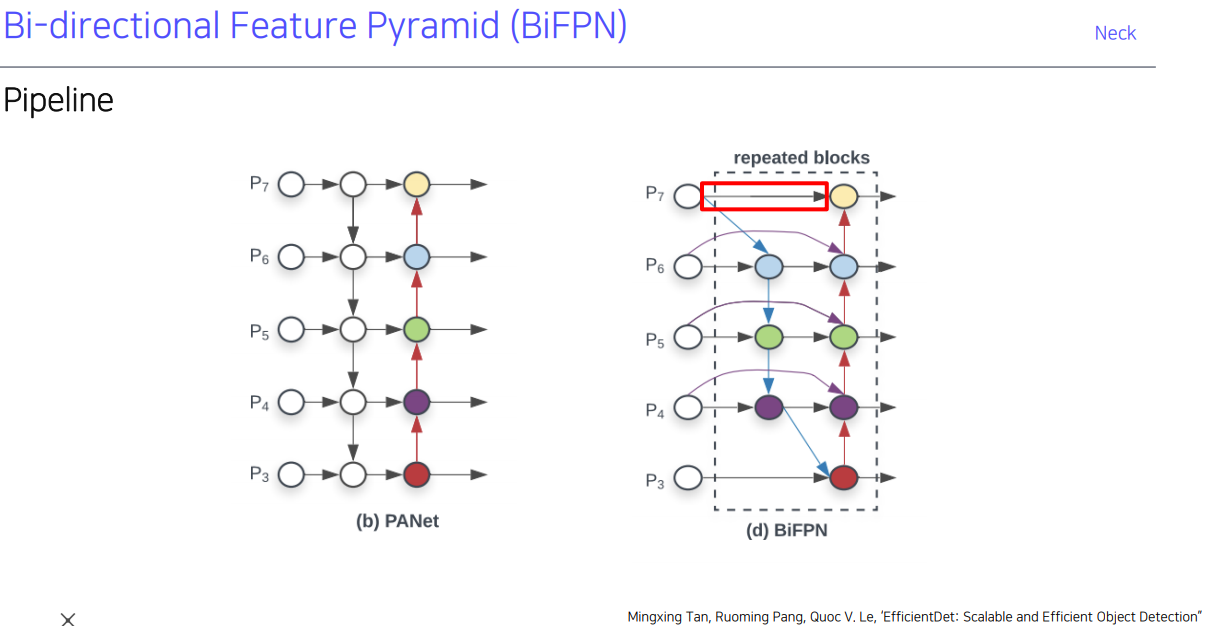
BiFPN(Bi-directional Feature Pyramid)의 경우 PAN을 쓰지만 좀 더 최적화 시켜보자는 의미에서 몇가지 안중요할 만한 feature는 없애고, 반복한다.

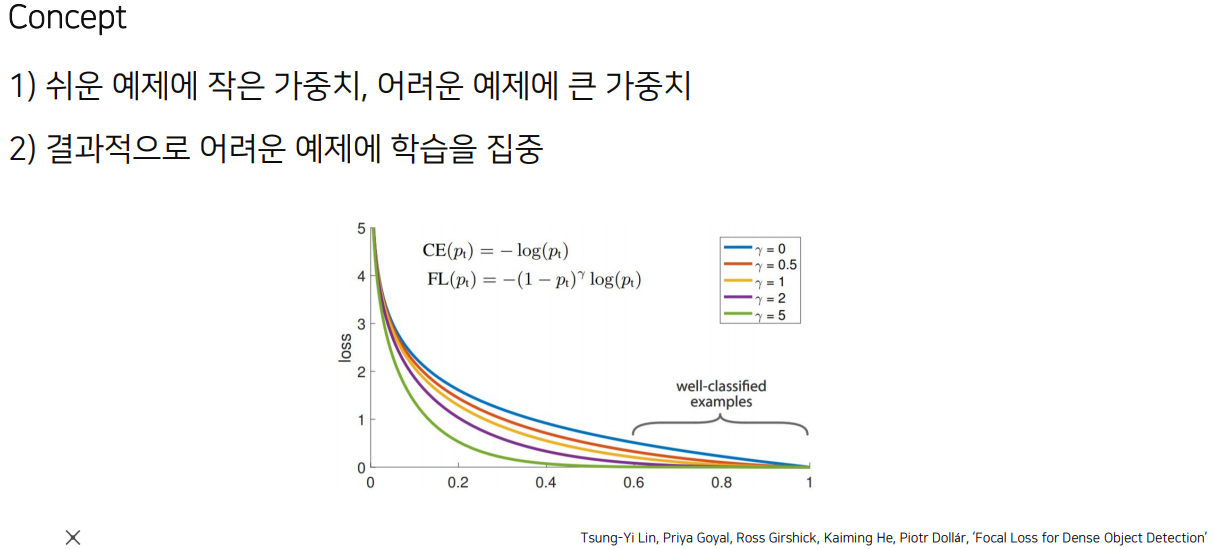
Focal loss는 데이터 불균형 해소하기 위해 만들어진 loss. 이번 프로젝트는 그래도 저번보단 나름 균형있어서 안쓸라고 했는데 background가 월등히 많은건 생각못했다. 써봐야 할듯.
mmdetection 사용법은 config만 잘 바꿔주면 된다.
멘토 및 기타 세션
현업 프로젝트: MLOps
논문: 한글로 되어있는걸 보자.