AITech 학습정리-[DAY 14] Recurrent Neural Networks
====================
학습내용
[AI Math 10강] RNN 첫걸음
sequence 데이터를 학습한다. 시계열. 독립된 데이터가 아님. 왜 이렇게 설계하는지 이해하는게 중요하다.
소리, 문자열 주가 등..
시퀀스 데이터는 독립동등분포(i.i.d.) 가정을 잘 위배하기 때문에 순서를 바꾸거나 과거 정보에 손실이 발생하면 데이터의 확률분포도 바뀌게 된다.
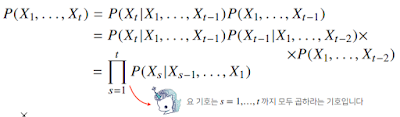
A와 B가 독립시행일 경우 P(A∩B) = P(A)*P(B)
앞의 조건가지고 뒤가 달라지기 때문에 조건부 확률을 사용할 수 있다. 베이즈 법칙으로 쪼갤 수 있음. (https://ko.wikipedia.org/wiki/%EB%B2%A0%EC%9D%B4%EC%A6%88_%EC%A0%95%EB%A6%AC)
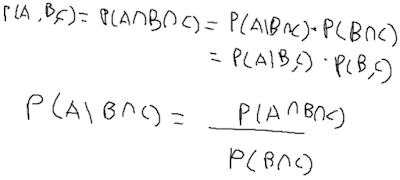
과거의 모든 데이터를 쓰는건 아니고 최근의 정보를 주로 다루는 것. 다 필요없는 경우가 많으니까. 어떻게 다룰지는 모델링에 다라 다를 수 있다.

고정된 길이 tau만큼의 시퀀스만 사용하는 경우 AR(tau)(Autoregressive Model) 자귀회귀모델이라고 부른다. 이런 방법도 있다. 이 경우 고정이기 때문에 어떨땐 가까운것만 필요하고 어떨땐 먼 과거가 필요할 때도 있다. 어떻게 모델링 할건가?

현재와 바로과거 직전 빼고 그 더 과거들을 묶어서 잠재변수 Ht라고 하고 인코딩한다. 이렇게 하면 바로 이전 직전의 정보랑 잠재변수 두 가지 데이터만 가지고 현재시점 미래시점 예측이 가능하기 때문에. 가변적이지 않고 고정된 길이의 모델링 할 수 있다. 과거의 모든 데이터를 가지고 훈련하고 가변적인 데이터 문제를 고정된 길이로 훈련할 수 있기 때문에 여러가지 장점이 가지고 있는 모델이다.

순환신경망.
가장 기본적인 RNN 모델은 MLP와 유사한 모양이라 과거 정보를 다룰 수 없다.
Xt -> Ht -> Ot
과거 정보가 안들어감.

W2와 Wx1, Wh1 이 3개 가중치 행렬은 t에 따라 변하지 않는 행렬이다. 즉 t에 따라 변하는 것은 입력데이터와 잠재변수.
t에 독립적인 가중치 행렬은 동일하게 작용된다. 각각의 t 시점에 활용된다.
RNN의 역전파도 거꾸로지만 잠재그래프의 연결에 따라서 순차적으로 진행된다. 맨 마지막 gradient가 타고 들어와서 과거까지 흐른다. Backpropagation Through Time BPTT. 미래 Ht+1와 결과 Ot+1 두개가 잠재변수 Ht에 들어온다. 이 Ht를 입력과 그 이전 Ht-1에 넣고 학습이 이루어 진다.

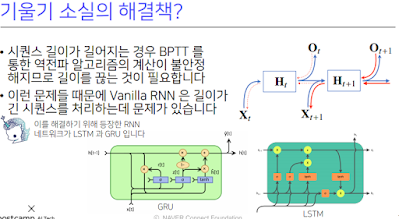
저 불안정한 부분이 길이에 따라 달라지는데 미분값이 엄청 커지거나 작아지거나 한다. 그래서 gradient를 모두 곱해주는 형태라 BPTT를 모든 t시점에서 학습하면 RNN 학습 network가 불안정해지기 쉽다.
기울기가 0으로 vanishing 되는건 큰 문제가 된다. 과거로 갈 수록 gradient가 점점 0이 된다면 과거 정보가 유실되서 문맥같은 이전 정보가 필요한 곳에 문제가 될 수 있다. 문제 해결하려고 쓰는게 truncated BPTT. BPTT의 모든 시점을 계산하는게 아니라 미래의 정보들 중 몇개는 끊고 오로지 과거의 정보에 해당하는 몇 개의 block을 나눠서 backpropagation에 연산을 하는 과정이다. 잠재변수에 들어오는 gradient들을 쭉 받아올텐데 미래시점에서부터 t+1 시점까지 들어오게 되는 gradient는 같다가 여기서부터 들어오는 gradient를 H에 전달하지 않고 Ht는 오로지 출력에서 들어오는 gradient인 Ot에서만 gradient를 받아서 Ht에 전달을 하는 것이다. 그래서 이런식으로 gradient를 전달을 할 때 모든 t시점에서 전달하지 않고 특정 bolck에서 끊고 gradient를 나눠서 전달하는 방식이다. 이걸로 gradient vanshing을 해결할 수 있다.
사실 완벽한 해결책이 되는건 아니다. 오늘날엔 vanishing 문제때문에 기본적인 RNN 모델은 사용하지 않고 LSTM이나 GRU라는 발전된 neural network를 사용한다.
[DLBasic] Sequential Models - RNN
sequence 에서의 어려움은? 결국 원하는 건 하나의 label. sequencal data는 길이가 얼마인지 몰라서 차원을 결정하기 힘듬. 몇개의 단어, 이미지들이 들어올 지 어떻게 알아.
가장 기본적인 sequencial 모델은 다음에 어떤게 나올지 예측하는 거. 시간이 지날수록 고려해야 되는 정보량이 늘어나긴 한다. 이게 어려움. 가장 간단히 만들려면? 고정적으로 과거의 몇개만 보는것. tau가 5면 난 과거의 5개만 가지고 예측하겠어.
이런거의 제일 쉬운 방법이 Markov model(first-order autoregressive model). 나의 현재는 과거에만 dependent 하다는 가정.
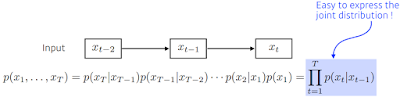
근데 별로겠지. 어제 공부한 양만 가지고 내일 수능 점수를 예측하는 꼴.. 과거의 많은 정보를 버릴 수 밖에 없게되지만 어쨌든 사용하게 되면 가장 큰 장점은 joint distribution을 하는게 쉬워짐 (나중에 배운다 함)
그래서 이렇게 하지말고 Latent autoregressive model. 사실 과거의 엄청 많은 정보를 고려해야 되는데 할 수 없어서 나온거. 중간에 hidden state가 들어가 있어서 과거의 정보를 summary 하고 다음의 time step은 이 h에 dependent 한 것.
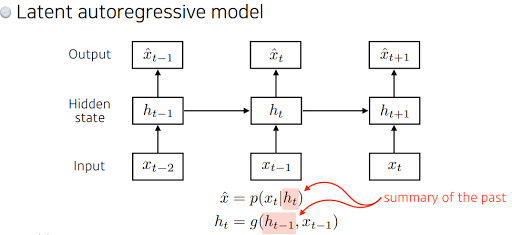
이런 개념들을 잘 쉽게 구현한 것이 Recurrent Neural Network. 자기 자신으로 돌아가는 구조가 하나 있는 것. 그래서 ht는 xt에만 dependent 한게 아니라 이전의 t-1 전에서 얻어진 어떤 cell state에 dependent 하게 되는 것.
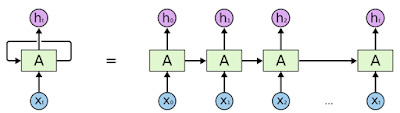
x와 A에서 나온 결과랑 합쳐줘서 h.
| 그림 출처들은 이 사람꺼 블로그다. |
단점은 과거에 얻어진 정보들이 summarize. 다 취합되서 미래에서 온거라. RNN 자체는 하나의 fixrule로 계속 취합한 거라 과거 정보가 미래에까지 살아남기 힘듬. 가까운건 고려가 잘 되는데 먼 과거는 잘 안됨. 영어 문장을 생각해보면 과거의 중요한 단어도 잘 기억했다가 결과내야 하는데 5초밖에 고려 못한다. 이게 가장 큰 단점. 이걸 극복하기 위해 나온게 LSTM.
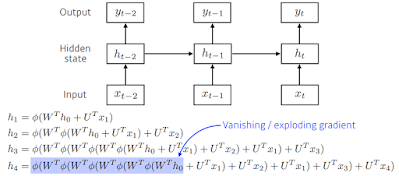
sigmoid 같은 activation function 을 계속 곱하면 작아져서 의미가 없어지게 되겠지. reLU도 어쩌다보니 양수가 나오면 엄청 크게 바껴서 중첩되 학습 network가 폭발된다.
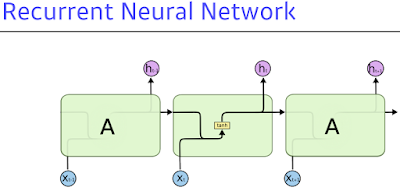
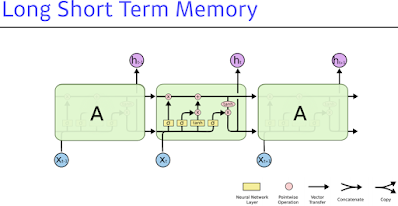
이 구조가 어떻게 Long Term 이 되는지 알아보자...
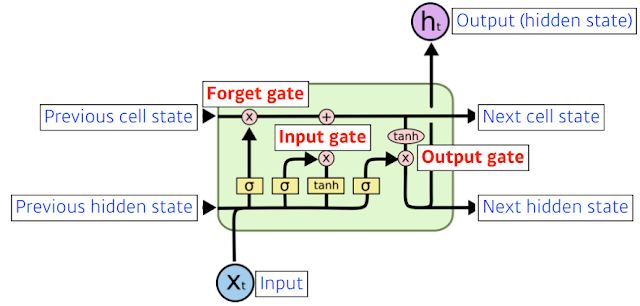
x는 입력. language model이라면 5만개 단어일 수 있고(사실 embedding vector로 들어가긴 할거지만). h는 output(hidden state).
위 쪽 라인의 Previous cell state 내부에서만 흘러가고 결과적으로는 지금까지 time step 0부터 t까지 들어왔던 t+1개의 정보를 다 취합해서 summarize 해주는 정보.
밑 라인은 Previous hidden state. output이 위로 나오기도 하지만 아래로 흘러간다. 아래로 흘러간 건 t+1번째 lstm에 previous hidden state로 들어가겠지. lstm이 입력으로 들어가는 건 이전의 출력값 (previous hidden state) 와 밖으로는 나가지 않는 previous cell state, 현재 time step t번째 입력 . 들어오는 입력 3개 나가는 입력 3개. 어쨋든 실제로 나가는건 hidden state 밖에 없음.
안을 자세히 보면 sigmoid가 3개. lstm은 gate 위주로 이해하면 좋은데 3개 gate.
lstm의 가장 큰 아이디어는 중간에 흘러가는 cell state. 어떤 컨베이어 벨트라고 보면 된다. 물건이 올라오면 컨베이어 벨트 조작공들이 이 정보를 잘 조작해서 어떤 정보가 유용하고 유용하지 않은 지를 가지고 다음번에 넘겨준다. 이 어떤걸 올리고 어떤걸 빼고 조작할지에 대한 정보가 gate.
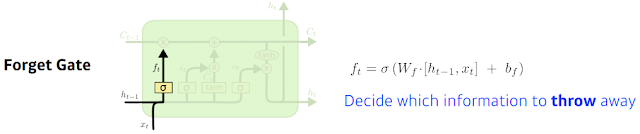
Forget Gate는 어떤 정보를 버릴지. 입력으로 들어가는건 현재입력 xt와 이전의 output ht-1 을 조합해서 ft를 얻게 됨. sigmoid를 통과하기 때문에 ft는 항상 0~1 값을 갖게 됨. 뒤에서 ft의 역할은 ft가 이전에 나온 cell state 정보중에 어떤거를 버리고 어떤걸 살릴지를 정해준다. 이걸 이전의 previous hidden state와 현재입력을 가지고 weight를 곱하고 activation을 통과시켜서 이전의 cell state에서 넘어오는 정보중에서 버릴거를 정한다.

Input Gate는 현재 입력이 들어왔는데 얘를 무작정 cell state에다 올리는게 아니라 이 정보중에 어떤 정보를 올릴지 말지를 정함. it는 이전의 이전의 previous hidden state와 현재 입력을 가지고 it라는 정보를 만들게 됨. it는 말 그대로 어떤 정보를 cell state에 추가할지. 추가로 알아야 할 건 올릴 정보를 알아야 한다. cell state candidate. 이전의 cell state 와 현재 입력이 들어와서 따로 학습되는 다른 neural network 를 통해서 tanh를 통과해서 나오는 모든 값이 - + 로 정규화 되있는 Ctilda 라는걸 만든다. 궁극적으로는 Ctilda가 현재 정보와 이전 출력값을 가지고 만들어지는 Cell state 예비군. 그럼 이전까지 summarize 되었던 cell state와 현재 정보와 이전 output으로 얻어진 cell state candidate를 잘 섞어서 새로운 cell state에 업데이트 해줘야 한다.
어떤 값을 올릴지 Ctilda.
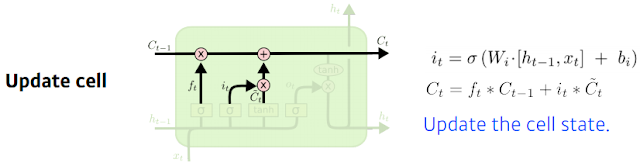
그래서 update cell 부분이 있는데 여기선 뭘 해주냐면 위에서 본 it가 나와서 ft에서 나온 것 만큼 이전 Ct-1 만큼 곱해서 버릴건 버리고 input gate에서 나왔던 Ctilda를 가지고 it만큼 곱해서 어느 값을 올릴지를 정해서 이 두 값을 combine 한 걸 새로운 cell state로 업데이트 한다. 버릴건 버리고 현재정보 기준으로 쓸건 쓰고, 합쳐서 새로운 cell state 를 update.
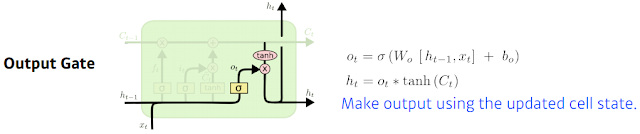
이제 출력값을 뽑아내야 겠지. 그대로 cell state out을 뽑아낼 수도 있고 그걸 GRU에서 하는거. LSTM에선 한번 더 조작한다. 어떤 값을 밖으로 내보낼 지에 해당하는 output gate를 만들고 그 output gate 만큼 곱해서 (element wise multiplication 해서) 현재 output이 나오고 얘가 next hidden state로 흘러가는 것.
이 네가지를 잘 조합한게 lstm. 이전까지 들어왔던 정보들을 현재 입력을 바탕으로 지울지, 현재 입력을 바탕으로 어떤 값을 새롭게 쓸지, 이 두 정보를 취합하는게 update cell이고 이 취합된 cell state를 한번 더 조작해서 어떤 값을 밖으로 빼낼지를 정하는게 output gate.
input, previous hidden state, previous cell state가 안으로 들어오게 되면 어떤 정보를 먼저 이전 cell state를 얼마나 지워버릴 지를 정하고 previous hidden state와 input을 가지고 어떤 값을 올릴지 Ctilda를 정하고 그 2두개 update 된 cell state와 현재 내가 올릴 candidate state를 다시 조합해서 새로운 cell state를 만들고 그 정보를 얼만큼 밖으로 빼낼지를 정해서 최종 출력값이 나오는 것.
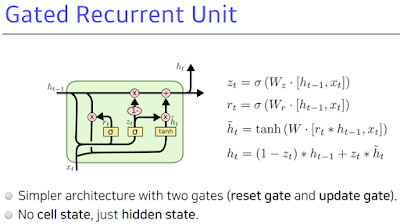
GRU. 일반적으로 rnn을 쓴다고 하면 3가지. 기본적인 바닐라 rnn과 lstm, gru. gate가 2개. cell state가 없다. hidden state가 곧 output이고 걔가 다음 번에 들어가게 됨. cell state가 없고 hidden state가 바로 있게 되서 output gate가 필요없어진거고 그 대신에 reset gate와 update gate. reset gate가 위에서 본 forget gate와 비슷한 것 같다. 이렇게 두 개의 gate 가지고 lstm과 비슷한 역할을 하게 된다. 그래서 lstm 쓸때보다 GRU를 사용할 때 성능이 올라가는 경우가 꽤 있다..
근데 현재는 transformer가 나오면서 이런것들이 잘 안쓰이고 바뀌고 있다.
실습
Classification with LSTM
Dataset and Loader
Define Model
Check How LSTM Works
- N: number of batches
- L: sequence lengh
- Q: input dim
- K: number of layers
- D: LSTM feature dimension
Y,(hn,cn) = LSTM(X)
Check parameters
Simple Forward Path
Evaluation Function
Initial Evaluation
Train
Test
[DLBasic] Sequential Models - Transformer
Further Reading
어렵다고 해서 강의 전에 링크 보고 왔다.. 대충 다 이해함. 그냥 링크보자.
self-attion은 자기 단어가 어느곳에 집중해서 해석을 해야 할지 알아내는 것 같다. 예를들면 it 은 여러 단어로 해석될 여지가 있는데 문장을 보고 it을 어디에 중점을 둬서 해석할지 등..
value vector 들의 weight를 구하는 과정이 각 단어에서 나오는 query 벡터와 key 벡터 사이에 내적. 그거를 normalize 하고 softmax를 취하고 attension을 value 벡터와 weighted sum을 한게 최종적으로 나오는 인코딩된 z.
학습 어려운 이유: 사람도 글쓰거나 말할때 빼먹고 한다. 이걸 해결하고자 transformer
얘는 재귀적인 모듈이 없고 atension을 활용했다.
다른 단어와 interaction을 보는게 중요함.
queries 벡터와 keys 벡터는 내적해야되기 때문에 차원이 같아야 하지만 values 벡터는 달라도 됨. value 벡터는 weight sum 하기만 하면 되니까.
왜 transformer 구조는 input order에 independent 하게 각 단어에 encoding이 될지 생각해보면 이해하는데 도움 될 것. -> 아마 각 단어의 연관성으로 해석을 하는거고 위치는 positional encoding으로 처리해서 그런듯.
최근들어선 이걸 이미지 도메인에서도 사용해보기 시작했다. 이미지 분류. 인코더를 활용하게 된다. 차이라면 원래 영어 문장들이 주어졌지만 그걸 이미지에 맞게 할려고 특정 영역으로 이미지를 나누고 넣어준다.
DALL-E. 알아서 GAN도 해주더라.
실습
주의깊에 봐야할 건 하나의 input word embedding vector가 query, key, value 벡터로 만들어지고 얘내들을 통해서 score가 나오고 submulmatrix를 통해서 value백터들의 weighted sum 으로 구해지는 과정이 두 줄로 다 된다.
인코더 디코더 attantion에서는 Q 벡터 입력갯수와 K 벡터 입력개수가 달라도 된다. K와 V는 인코더에서 온거고 디코더에 들어간 입력들에 대해서 Query 벡터들이 만들어졌다. K벡터와 V벡터 갯수가 Q 벡터 갯수랑 달라도 된다. 인코더 디코더 attantion에서는 다른 갯수가 있어도 서로 interaction 할 수 있다.
차원이 어떻게 돌아가는지 잘 이해하면 좋겠다( 진짜 너무 어려운데 이걸 어떻게 하냐 진짜 졸리고 피곤하고 하진짜)
n_batch 데이터들은 모두 independent 하게 동작을 하고 n_source와 d_feature 가 들어오면 원래 multi attention 이라고 블로그에 설명한건 K개의 output이 나왔다면 코드에선 dimention 나온걸 K개의 partition 하고 얘내들을 independent 하게 scale dotproduct attention을 한 다음에 그 결과들을 concatnate 시키고 걔를 한번 더 dense layer를 통과해서 나오는게 nh의 결과다. 이게 가장 기본이랜다.
엄청 중요하니까 다 따라서 쳐보면 큰 도움이 될 거다.
Multi-Headed Attention
Scaled Dot-Product Attention (SDPA)
- Data X∈Rn×dX∈Rn×d where nn is the number data and dd is the data dimension
- Query and Key Q,K∈Rn×dKQ,K∈Rn×dK
- Value V∈Rn×dVV∈Rn×dV
Attention(Q,K,V)=softmax(QKT√dK)V∈Rn×dVAttention(Q,K,V)=softmax(QKTdK)V∈Rn×dV
Multi-Headed Attention (MHA)
headi=Attention(QWQi,KWKi,VWVi)headi=Attention(QWiQ,KWiK,VWiV)
===========================
퀴즈/과제
막힌거 없다.
===========================
피어세션
danse layer 차이가 많이 난게 신기햇음. deconvolution은 뭐 하나. 입력을 찾을려고 하는거니까 미분이랑 하는게 똑같음. 실제 뒤집어지더라.
conv 홀수개인 경우 딱 중앙이 되는데 짝수하면 중앙이 아니라 어딘가 하나로 치울치니까 잘 안쓴다.
최근 cnn. alexnet은 gpu 2개 썼다. googlenet inception block을 사용했다. 입력 들어오면 2갈래로 나눠서 한쪽에서 훈련시키고 후에 합친다. resnet이 56 26. 더 깊게했는데도 안되는 걸 x입력변수를 마지막에 한번 더 더해줘서 개선시켰다.
RNN은 연속적으로 흘러가는 데이터를 학습시키는 거다. sequence 데이터가 단순히 나열한 건줄 알았는데 앞이랑 연관이 되어있는 거더라. 사진과 달리 영상은 시간에 따라 이미지가 계속 변하는 형태니까 sequence 데이터에 대해 생각해봤고 이걸 다루는게 RNN이다. RNN 특이한 부분이 입력해서 출력으로 나온걸 다시 입력으로. 이미 출력한 건 과거가 된다. 기울기 소실. pi로 시작하는 항이 sequence 길이가 길어지면 불안정해진다는데 왜 불안정해지는지는 이게 1보다 크면 gradient 값이 커지게 되고 0이면 0으로 수렴 되니까 불안정해진다. 해결책이 BPTT. activation이 reLU로 쓰인 이유가 혹시 이거때문인지.
LSTM. gate들. 특이했다. 단순히 분별로 끝나는게 아니라 어떻게 할지 결정하는 거라. tranformer가 매우 어렵다고 해서 걱정이다.
segmentation 이 궁금하다 알고싶다. 경량화가 되고 파라미터 수 준거. 자꾸 rcnn 나오는거 보면 트렌드가 빨리 바뀐다. 최근에는 하드웨어 장비들이 좋아져서 속도보다 성능을 우선시한다. 하지만 경량화도 중요하구나. LSTM도 어렵게 말하는것 같아서 작년에 따로 배웠던 걸로 알아야 겠다.
강의가 너무 어려워서 예전에 배웠던 모두의 딥러닝에서 배운걸 바탕으로 이해했다. 파라미터 수를 줄이는게 큰 의미를 갖는구나. segmentation. 은 이해를 하겠는데 detection는 per box로 해서 box 내에 차지하는 걸 만들고 다른곳에선 grid로 만들어서 하는것 같더라. boundary 부분 설명 자세히 해줬었으면.. 엄청 큰거랑 미생물 등. 비행기도 멀리서 찍으면 작을거고 미생물도 가까이에선 클텐데 어떻게 박스 크기를 정하는건지. fully connected layer.
손실보단 이용한걸로 생각하면 될 것 같다. 압축이 정보를 좀 더 효율적으로 저장한다. 버려지는 정보들은 어차피 쓸모없는 거였다.
챗봇이라면 NLP 가 중요하다. 구조가 중요하고. 캠프 NLP수업이 부족하니까. cs224 수업 들으면서 천천히 구현해봐라. 자연어처리 데이터셋은 많으니까.
https://littlefoxdiary.tistory.com/42
SK 계열사마다 인재상이 다름. cnc는 실무였던듯.
롯데는 인재상 중요.
==========================
후기
막막하다.
transformer 가 이론으로 배운거랑 코드랑 너무 달라서 못따라가는게 거기다 차원 갯수를 이해하라고 한다. 어떻게 할지 모르겠다. 주말에 이것만 팔까.