AITech 학습정리-[DAY 18] seq2seq with attention, Beam search and BLEU score
===================================
학습내용
(5강) Sequence to Sequence with Attention
seq2seq model
문장받는 encoder, 문장 생성하는 decoder
서로 간섭없이 생성하는. LSTM을 채용한 걸 알 수 있음.
encoder의 마지막 hidden state가 decoder의 처음 시작 hidden state로 쓰임.
decoder 시작 <SoS> start of sequence. 마지막 <EoS>.
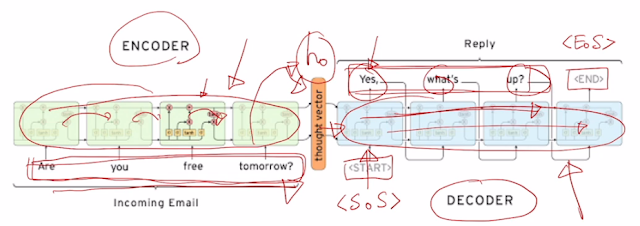
이 모델에 Attention 추가 활용 가능. 얘는 encoder dimension 에 맞춰 모든 정보들을 압축하여 넣어야 하는 문제점. 첫 단어가 잘못되서 전체적으로 잘못된다.. 그래서 아얘 거꾸로 해보는 방법도 고안되긴 했었음.. 또 훨씬 이전에 나타난 정보는 변질이나 소실가능.
attention은 encoder 과정에만 의지하는게 아니다. 입력 될 때 입력된 단어의 hidden state는 거기에 주로 집중됨. 이 각각의 time step 별 hidden state들을 저장해서 decoder에 다 넣는다. 알아서 선별함. 적절히 선택해서 예측한다.
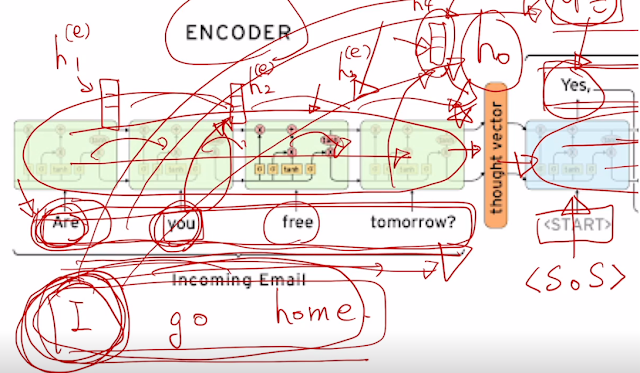
decoder 선별은 현재 가지고 있는 hidden state와 encoder hidden state 각각들과의 내적을 통해 결정하고 어디에 가중치를 둘지를 봐서 정보를 사용. 그래서 자기 다음 time step에 넣는것과 선별하는 것 두개를 한다.
가중 평균된 걸 context vector라고도 부름. 그래서 attention model을 정의하자면 input으로 decoder의 hidden state와 encoder에서 사용한 각각의 hidden state들 로 볼 수 있고 output 으로는 각각 가중치 평균 합으로 구한 context vector 라고 정의 가능.

attention output은 결과와 concat 되서 함께 사용됨.
backpropagation도 attention distribution을 거치며 진행됨.
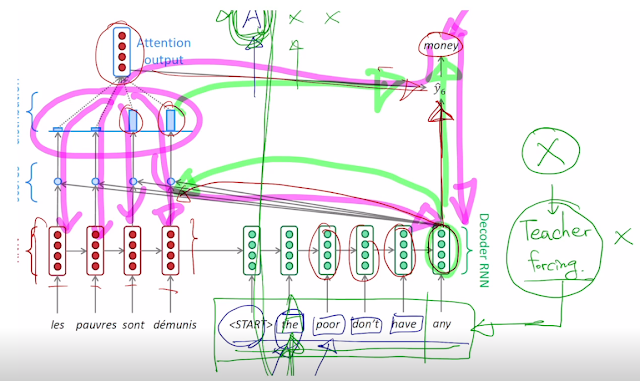
실제 훈련할 때는 실전처럼 decoder의 output을 다음 input으로 넣고 하는게 아니라 output에 상관없이 다음 입력에 ground truth를 넣어준다. 그래야 output이 엉터리로 나와도 제대로 학습 할 수 있기 때문. 이거를 Teacher forcing 이라고 함. 실제 테스트 할 때는 안이러니까 괴리감이 느껴지긴 한다..
근데 현재 decoder hidden state와 encoder의 hidden state 들과의 내적을 통해 점수를 계산했잖아? 여기에서도 다양하게 확장, 변형을 했다.

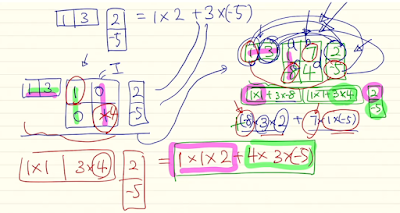
general은 확장해서 가중치를 부여. 근데 중간에 matrix를 넣어 가중치를 부여하는데 이렇게 하면 hidden cell 간의 서로간의 영향도 고려 가능하다.
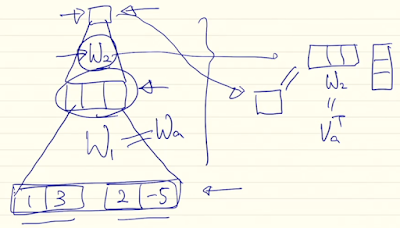
concat은 작은 neural networks.
이렇게 하면 기존에 score에서 내적으로만 구해서 score를 구하는건 학습이 안됬는데 이것 조차 backpropagation 과정에서 학습 가능.
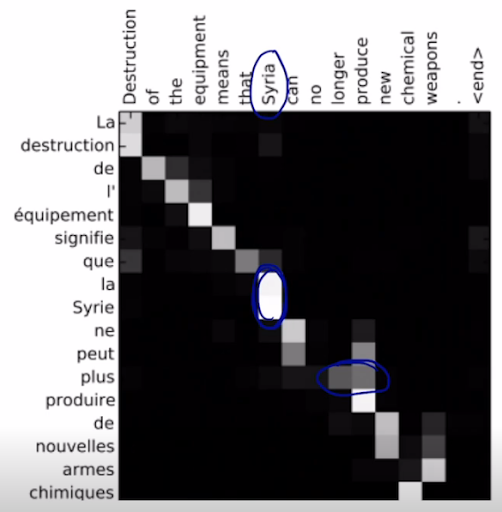
이렇게 attention을 사용하면 그냥 잘 되고, 긴 문장일 때 encoder의 초기문장이 사라지는 등의 문제 해결, backpropagation에서 gradient 학습할 때도 원래 마지막부터 encoder의 처음 hidden state 까지 거쳐가며 학습해서 사라지는 문제도 해결, 적절하게 학습되고 언제 어느 단어를 주요해서 봐야할 지(alignment)를 스스로 배운다. 즉 어순 및 주변 단어와의 관계도 배운다..

(6강) Beam Search and BLEU
현재 time step 에서 가장 좋아보이는 걸 그때그때 선택하는게 Greedy decoding. 중간에 만약 잘못 해석했다면? 못돌아가네.. 어케 해결하지?
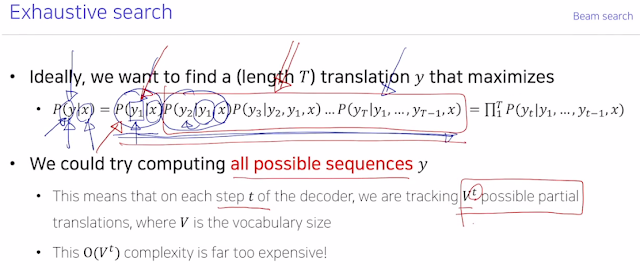
그래서 모든 확률 경우의 수를 고려하는 무식하지만 원초적이고 확실한 방법이 있다. 사실 이게 이상적인 방식임. 그러나 V^t의 복잡도를 가지기 때문에 전에 RNN 에서 했던 2^n 을 앞뒤만 dependency 하다고 고려해서 파라미터 수를 줄였던 것처럼 여기서도 비슷한 방법을 이용한다. 그때그때만 고려하는 greedy 와 이상적인 Exhaustive search 사이의 적절한 방법을 사용한게 Beam search.

각각의 step 마다 번역 가능한 후보개 k를 정한다. 또 exhaustive search 에서도 그렇고 확률을 곱해서 결정하지만 이 확률을 log를 써도 제일 높은건 제일 높다는 것을 이용해서 곱셈을 덧셈으로 바꿔줌. 그래서 이상적인 정답이라고 장담할 순 없지만 전체 다 하는 것보다는 빠르다. 그래서 k가 어쨋단건데? 는 밑의 예제를 보자.
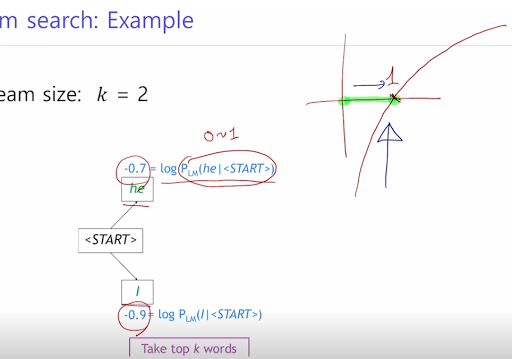
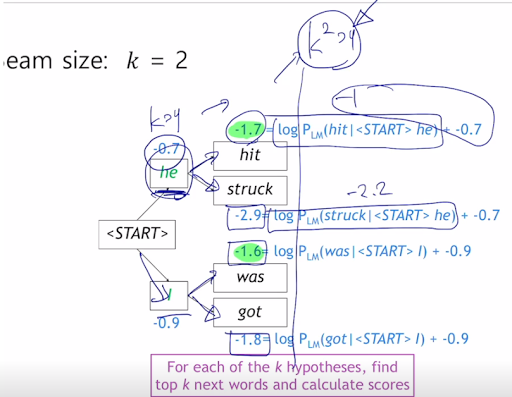
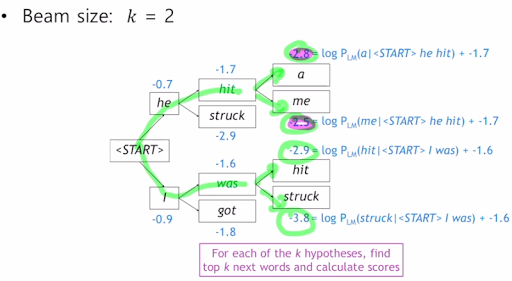
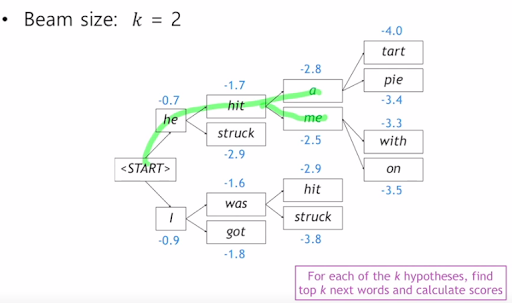
이런식으로 수치적으로 가능성이 제일 높은거를 k개를 선정하고 그것을 누적시켜가며 찾는다.
<END> 토큰을 만날때까지 수행하고 만나면 몌모리에 임시저장하고..를 계속한다.
이걸 언제까지 하는가? 우리가 T만큼만 최대로 중단해서 완료된 hyipotheses가 정해둔 n개만큼만 있다면.

그래서 선정한 candidate들 중 가장 높은걸 사용한다. 근데 계속 -를 더해서 누적하는거라 가장 짧은게 점수가 제일 높을것이기 때문에 단어의 수 t로 나눠서 정규화한다.
BLEU score
생성모델의 품질, 결과를 평가하는 BLEU score
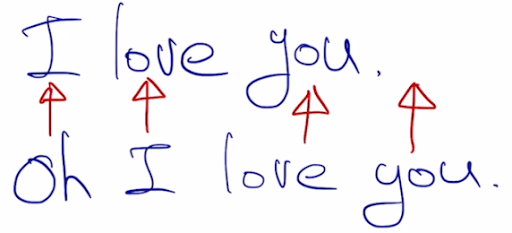
이렇게 단순히 위치로 하다보면 맞는데도 불구하고 0% 정답이라고 나올 수가 있다. 그래서 단순하게 이렇게 할 수 없으니까 필요한거.
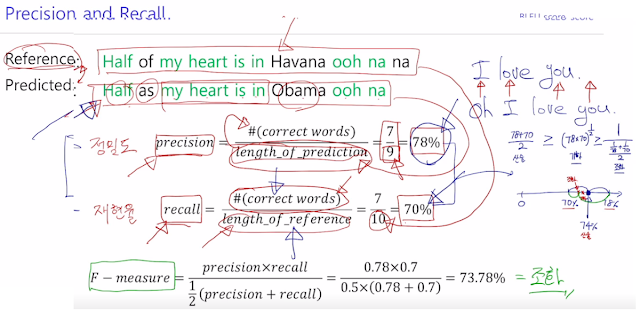
단어의 맞춘 개수, 길이로 정밀도 precision, 재현율 recall을 고려해 얼마나 맞았는지 체점함.
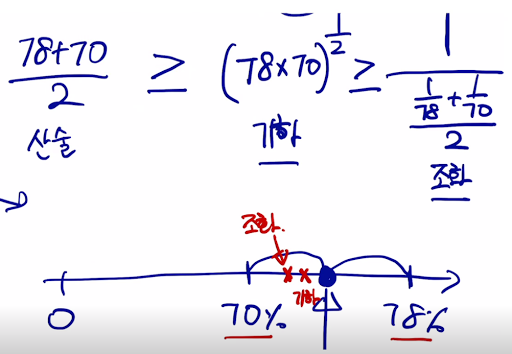
조화평균을 쓸 수록 조금 더 내분점에 가까워짐. 그래서 내분점에 가까워지는 평균으로 쓰고싶다 해서 쓰는듯.
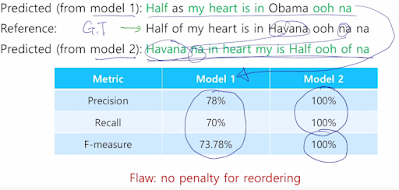
근데 엥? 문법 어순 다 틀려도 단어만 있으면 정답되니까 안된다.
그래서 BLEU score. 단어가 얼마나 겹치는지 뿐만 아니라 N-gram이라는, 1개, 2개, n개를 연속해서 봤을 때 얼마나 매칭되느냐로 평가하는 것이 특징. recall은 무시하고 precision만 사용. precision 특성 때문. 빠짐없이 번역했냐 보단 의미를 얼마나 잘 번역했는지.

조화평균은 너무 내분점으로 지나치게 가는것 같다.. 그래서 기하평균을 쓰는 숨은의도. 또 너무 짧은 문장엔 패널티 줘서 짧지 않도록.

실습
seq2seq
##5. Seq2seq 1. Encoder를 구현합니다. 2. Decoder를 구현합니다. 3. Seq2seq 모델을 구축하고 사용합니다.
필요 패키지 import
데이터 전처리
src_data를 trg_data로 바꾸는 task를 수행하기 위한 sample data입니다.
전체 단어 수는 100100개이고 다음과 같이 pad token, start token, end token의 id도 정의합니다.
각각의 데이터를 전처리합니다.
PackedSquence를 사용을 위해 source data를 기준으로 정렬합니다.
Encoder 구현
Bidirectional GRU를 이용한 Encoder입니다.
- self.embedding: word embedding layer.
- self.gru: encoder 역할을 하는 Bi-GRU.
- self.linear: 양/단방향 concat된 hidden state를 decoder의 hidden size에 맞게 linear transformation.
Decoder 구현
동일한 설정의 Bi-GRU로 만든 Decoder입니다.
- self.embedding: word embedding layer.
- self.gru: decoder 역할을 하는 Bi-GRU.
- self.output_layer: decoder에서 나온 hidden state를 vocab_size로 linear transformation하는 layer.
Seq2seq 모델 구축
생성한 encoder와 decoder를 합쳐 Seq2seq 모델을 구축합니다.
- self.encoder: encoder.
- self.decoder: decoder.
모델 사용해보기
학습 과정이라고 가정하고 모델에 input을 넣어봅니다.
Language Modeling에 대한 loss 계산을 위해 shift한 target과 비교합니다.
실제 inference에선 teacher forcing 없이 이전 결과만을 가지고 생성합니다.
[82,
63,
72,
98,
3,
53,
59,
8,
24,
24,
82,
57,
12,
12,
12,
12,
12,
12,
12,
12,
12]
seq2seq_attention
##6. Seq2seq + Attention 1. 여러 Attention 모듈을 구현합니다. 2. 기존 Seq2seq 모델과의 차이를 이해합니다.
필요 패키지 import
데이터 전처리
데이터 처리는 이전과 동일합니다.
Encoder 구현
Encoder 역시 기존 Seq2seq 모델과 동일합니다.
Dot-product Attention 구현
우선 대표적인 attention 형태 중 하나인 Dot-product Attention은 다음과 같이 구현할 수 있습니다.
이제 이 attention 모듈을 가지는 Decoder 클래스를 구현하겠습니다.
Seq2seq 모델 구축
최종적으로 seq2seq 모델을 다음과 같이 구성할 수 있습니다.
모델 사용해보기
만든 모델로 결과를 확인해보겠습니다.
[73,
73,
49,
37,
69,
44,
65,
66,
81,
61,
36,
35,
50,
50,
50,
50,
50,
50,
50,
50,
50]Concat Attention 구현
Bahdanau Attention이라고도 불리는 Concat Attention을 구현해보도록 하겠습니다.
- self.w: Concat한 query와 key 벡터를 1차적으로 linear transformation.
- self.v: Attention logit 값을 계산.
마찬가지로 decoder를 마저 구현하겠습니다.
====================================
과제 / 퀴즈
- 본 과제의 목적은 대표적인 pytorch library 중 하나인 fairseq을 이용해 번역 모델을 학습하는 방법을 배우는 것입니다.
====================================
피어세션
수업한거 분석. dacon 하는거 어떰?
내가 과거껄 굳이 시간들여가며 꼼꼼하게 볼 필요가 있나? 라고 질문했는데 틀린 생각이었다. 일단 실습코드 내용 하나도 이해 안되니까 이것들부터 이해하자..
===========================
후기
실습 코드랑 이론이랑 연결시켜서 꼼꼼히 확인하는 작업을 언제 하지? 주말에 할까..