AITech 학습정리-[Day 32] Image Classification 2, Semantic segmentation
=====================================
학습내용
(3강) Image classification 2
1. Problems with deeper layers
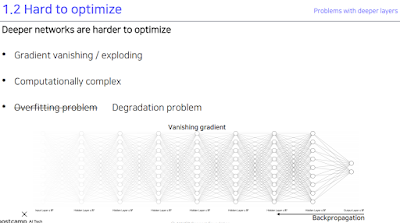
너무 깊게 쌓으면 무슨 문제가 있느냐. 그레디언트가 사라지는 문제가 발생. 어떻게 해결하지?
2. CNN architectures for image classification 2
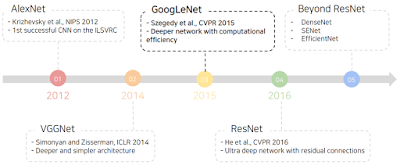
전시간에 보던거 계속 이어보자.
2.1 GoogLeNet
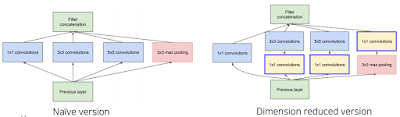
GoogLeNet 같은 경우 깊게 쌓으면 안되니까 옆으로 쌓으면 되지 않을까? 라는 발상. 1*1 conv가 들어간건 파라미터 수 줄일라고.
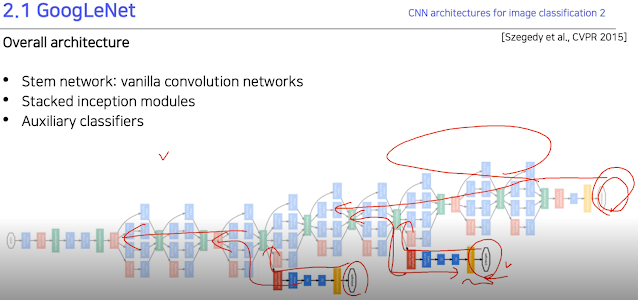
그래서 실제로 구조를 보면 처음에만 전과 비슷하다가 위에처럼 수평으로 쌓은 레이어들이 반복되서 나타나는걸 볼 수 있다. 거기다 또 vanishing gradient 생기지 말라고 중간중간에 측정 결과값들을 다시한번 넣고있음.
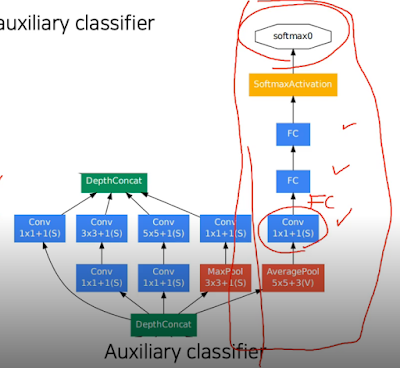
그래서 이 중간중간에 있는 저 결과값 도출 부분은 훈련할때만 사용하고 실제 실험할때는 안사용한다.
2.2 ResNet
AlexNet 은 8레이어, VGGNet은 19레이어, ResNet은 최대 152 레이어다. 그냥 많이 쌓았다.
| [Heetal.,CVPR2016] |
그런데 많이 쌓았더니 성능이 더 안나오더라. 원래 깊게 쌓으면 overfitting 되는거 아냐? 하고 걱정했었지만 vanishing gradient가 문제였음.

이것은 아마 레이어가 너무 깊어서 원래 입력값이 출력값으로 나가면서 많은 정보가 사라지는 것이라고 추정하고 그럼 마지막에 지름길로 입력값을 다시 넣어주자. 라고 생각해서 그렇게 만들었다. 이걸 Residual block 이라고 함.
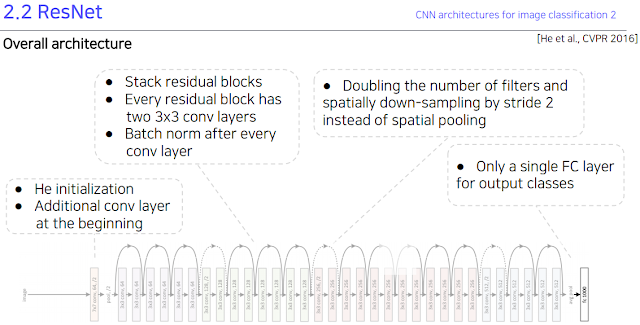
그래서 실제 구조도 그렇게 만들었다.


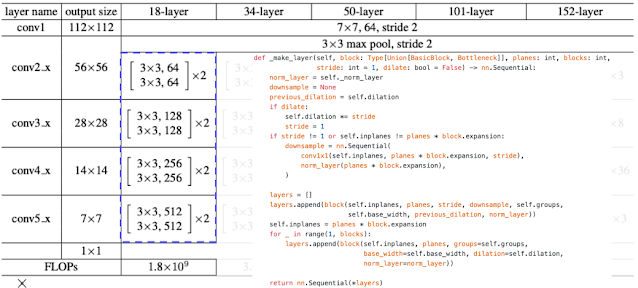
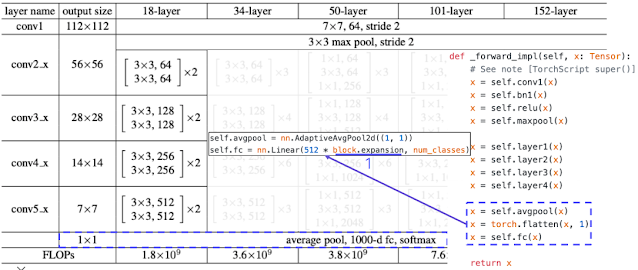
코드만 봐도 그럼.
정말 너무 좋은 ppt라 생략할 수가 없었따.
2.3 Beyond ResNets
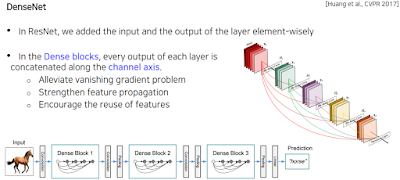
위에서 Residual block 한 것처럼 모든 블록 안에 시작 부분을 뒤에 그대로 넘겨주되, 더하지 말고 concat으로 해보자 한게 DenseNet.
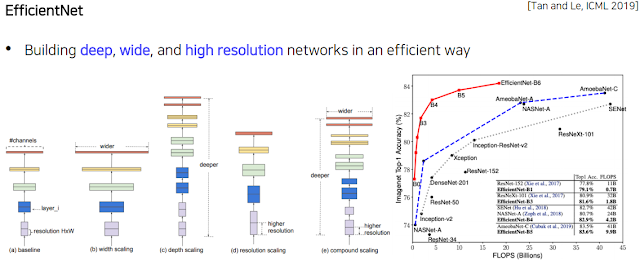
(a)는 기본. (b)는 GoogLeNet에서 햇던것처럼 옆으로 확장하기, (c)는 그냥 더 깊은 layer, (d)는 입력으로 받는 이미지를 크게. 이렇게 다양한 거를 적절하게 활용하면 어떨까 한게 (e). 근데 설명 들어보면 컴퓨터가 알아서 모델을 구현하게 만들었다고 한다. 어떻게 하는건지 찾아봐야 할듯.
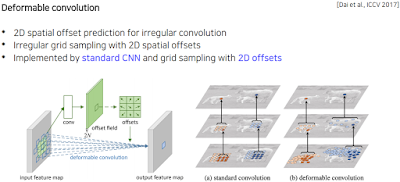
지금까지 입력받을 때 정사각형 형태로 받아왔으니까 물체 그대로의 모양으로 입력을 받아보자..
3. Summary of image classification
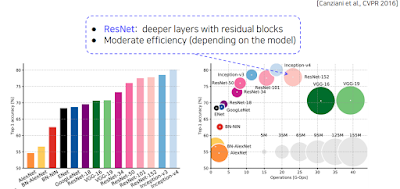
대충 파라미터 크기와 정확도의 상관관계. 이것도 16년도꺼로 옛날거라는걸 알아두고 참고하라.
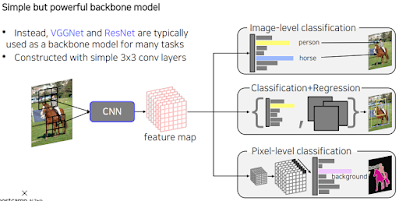
GoogLeNet이 제일 효과적이긴 하지만 사용하기 복잡하다. 대신 VGGNet 이나 ResNet을 쓴다. 우리가 한 CNN 부분으로 맵을 추출하고 한 부분이었단 것을 기억하세요.
(4강) Semantic segmentation
1. Semantic segmentation
이 뭔가. 전에 햇던 물체를 직사각형으로 표시하는게 아닌 픽셀 단위로 표시하는 것.
2. Semantic segmentation architectures
| [Longetal.,CVPR2015] |
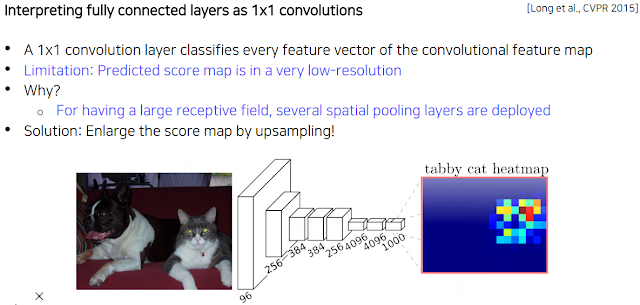
그냥 단순한 벡터정보르 출력하는 Fully connected layer와 달리 Fully convolutional layer(FCN)는 위치를 표현 가능. 일자로 쭉 펴질 않으니 가능한 듯.
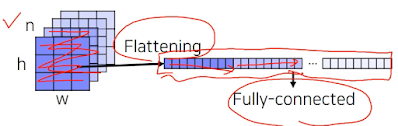
입력 이미지 크기가 항상 고정되었어야 했는데 이유는 사람이 손으로 코드를 작성할 때 이렇게 flattening 하는 과정에서 얼마로 쫙 펼쳐내야 할 지 정해야 하기 때문. 그리고 이렇게 하면 위치 정보도 잃어버리는 듯.
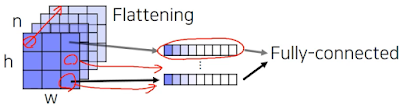
그래서 저렇게 지그재그로 index 하나하나 입력해서 연결하는 대신에 각 위치의 pixel 마다 channel을 기준으로 vector를 만들어 하나의 feature vector을 만들어 합친다고 한다. 그리고 이 과정은 1*1 conv랑 비슷한 과정임. 근데 conv는 일자로 펼치지 않고 그 픽셀 위치 그대로 있는다는 차이점이 있는듯.
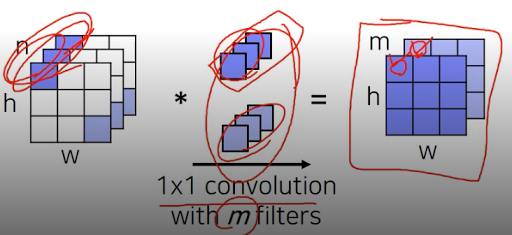
그래서 cnn으로만 한다고 치자. 마지막에 해야하는건 upsampling이다. 입력 이미지에서 픽셀단위로 물체 위치 표시하는 거니까.
그럼 애초에 down scaling을 안하면 되지 않느냐 생각할 수 있는데 그럼 주변의 정보를 못 얻는다(receptive filed가 적어짐). 이게 뭐냐면 conv랑 maxpool 로 주변의 정보들을 가지고와서 분석하는건데 이런 과정 자체가 없으면 하기가 힘들어짐. 실제로도 성능이 매우 떨어진다고 함. 그래서 미련해 보여도 제일 좋은 방법이다.
그래서 upsampling하는 방법이 여러가지가 있지만 대표적으로 쓰이는 2가지 Transposed convolution과 Upsample and convolution을 알아볼거다.
Transposed convolution

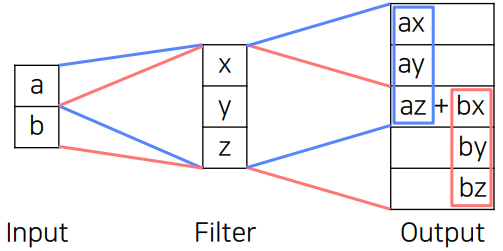
예상할 수 있다싶이 겹쳐져서 더해지는 문제가 발생할 수 있음. 그래서 upsampling 설정할 때 conv size와 stride 수치를 잘 결정해줘야 함.

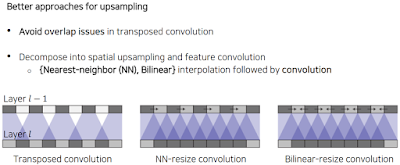
이걸 고치는 방식이 Nearest-neighbor(NN) 방식과 Bilinear 방식이 있다는데 이 방식들을 학습하는 weight로 만들기 위해 convolution으로 구현한다고 함.
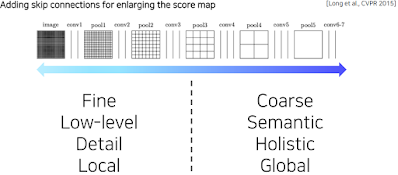
더 들어가기 전에 CNN에서 layer의 층 깊이에 따라 어떤 의미를 가지고 있는지 상기해보자. 각 layer 별로 activation map에 해상도와 의미를 살펴보면 다음과 같은 경향성이 있다.
낮은 레이어 쪽, 입력 이미지와 비교적 가까운 곳은 변화에 민감하고, 디테일하고, 지역적이다. 아직 주변의 정보를 모으지 못해서 생기는 현상이고, 입력 이미지에 가까운 만큼 해상도가 높을 테니까 자세한 것인듯 하다. 작은 차이에도 민감하다.
반면 높은 레이어쪽, 출력에 가까운 층은 해상도가 낮아지지만 전반적이고 의미론적인 정보들을 많이 포함하는 경향을 가지고 있다.
사실 이 둘 모두가 필요함. 각 픽셀별로 의미를 파악해야 하고 현재 픽셀이 물체의 경계선 안쪽인지 바깥쪽인지 디테일하게 파악도 해야 함.
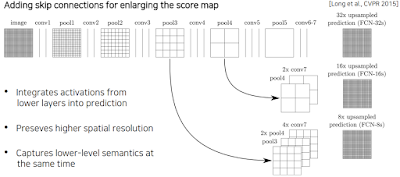
그래서 뭐다? 두개를 합친다. 말 그대로 각 층들의 activation map을 가져와 덧셈을 하든 concat을 하든 합치는 거임.
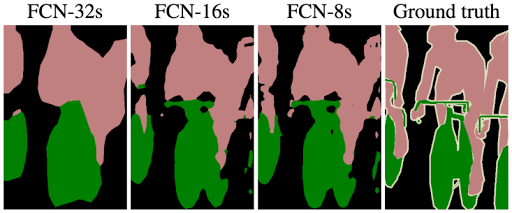
그래서 보면 낮은 레이어 쪽이랑 합칠수록 디테일이 증가하는걸 볼 수 있다.
Hypercolumns for object segmentation
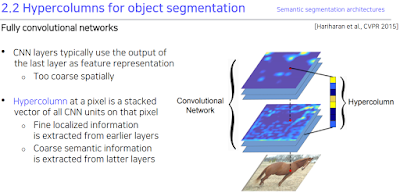
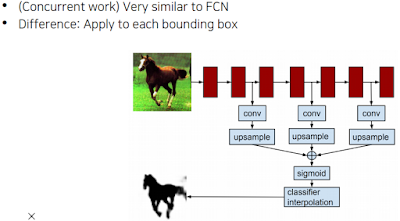
또 Hypercolumns 라는 방식이 있다는데 각 bounding box를 어떻게 결합해서 만든다고 함. 어차피 잘 안쓰고 FCN 쓴다고 해서 대충들음.
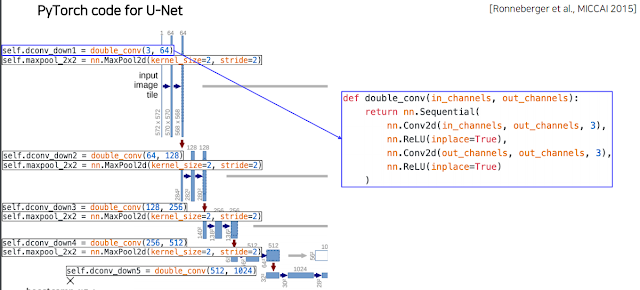
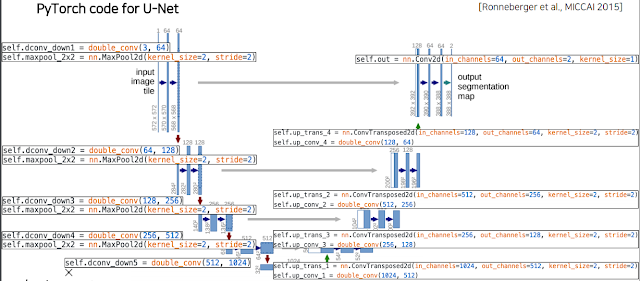
2.3 U-Net
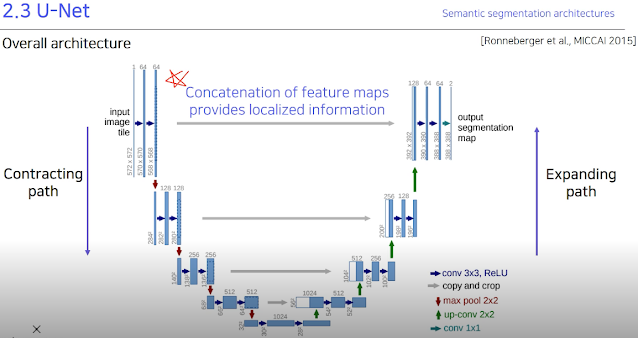
FCN의 skip connection과 유사한데, downscaling과 upscaling이 완전히 대칭되도록 만들어 Contracting path 에서의 정보가 Expanding path에 그대로 들어갈 수 있게 설계해 놓음. 그래서 정확하게 2배씩 내리고 올리고 conv도 2배씩 늘리고 줄이고 하는걸 볼 수 있다.
제일 중요한게 Concatenation of feature maps provides localized information. 낮은 layer 및 해상도가 커질수록 주변의 환경 변화에 민감하게 되기 때문에 다른 어딘가를 거치지 않고 그대로 전달해주는게 중요하다고 한다.
참고로 2배씩 나누기 때문에 홀수 있으면 나누고 나온 값을 올려야할지 내려야할지 문제가 생김. 그래서 이런 문제가 생기지 않게끔 처음부터 잘 조정하자.
2.4 DeepLab
이것도 image segmentation 방법론인것 같은데 v1, v2, v3, v3+가 나와있다고 함.

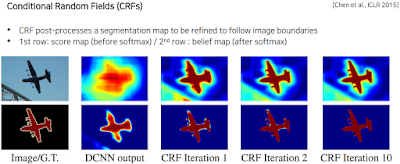
후처리로 사용되는 툴이라고 함. 그래프 모델링. 이 deeplab도 수많은 방법중에 하나이기 때문에 관심있으면 더 찾아보라고 함.
일단 저 개념은 처음 결과가 나왔을 때 굉장히 rough하게 나옴. 얘는 피드백하는 구조가 없기 때문에 input에서 edge같은걸 뽑아내서 expand 한다고 한다. 그걸 10정도 수행하면 저것처럼 잘 나옴.
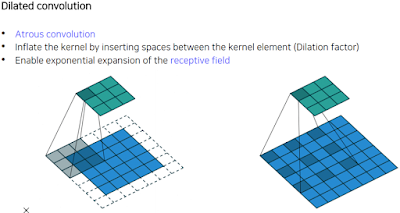
중요한 component는 Dilated convolution. 왼쪽처럼 한칸씩만 하는게 아니라 1픽셀을 띄워서 저장함. 단순하지만 이렇게 하면 receptive filed를 늘릴 수 있다.
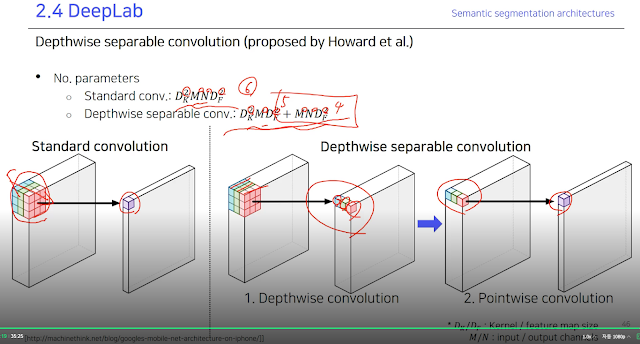
입력값이 워낙 크다보니 파라미터 수를 줄이는 방법론. depthwise separable convolution은 그냥 일반적인 conv를 둘로 나눔. 실제 수치로 대강 개산해 봐도 적은 수의 파라미터가 된다.
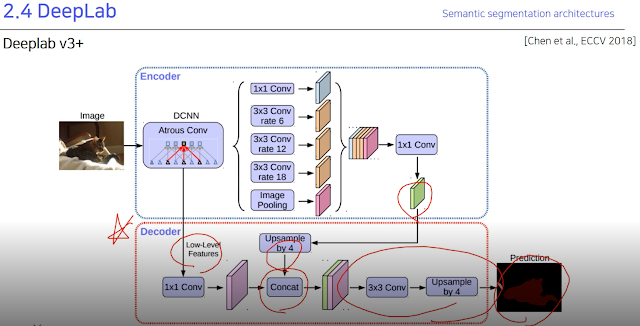
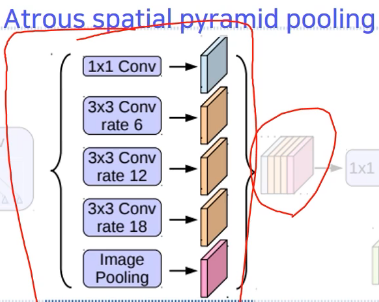
Atrous spatial pyramid pooling은 물체가 다양한 크기를 가질 수 있을텐데 이를 고려하기 위해 여러개를 만든다고 한다.
==================================
과제 / 퀴즈
몰라
=====================================
피어세션
수업복습함
=================================
후기
공부를 해야 한다..