수업내용
도매인 특화 task의 경우, 도메인 특화된 학습 데이터만 사용하는 것이 더 좋다. NLP 특징인듯.

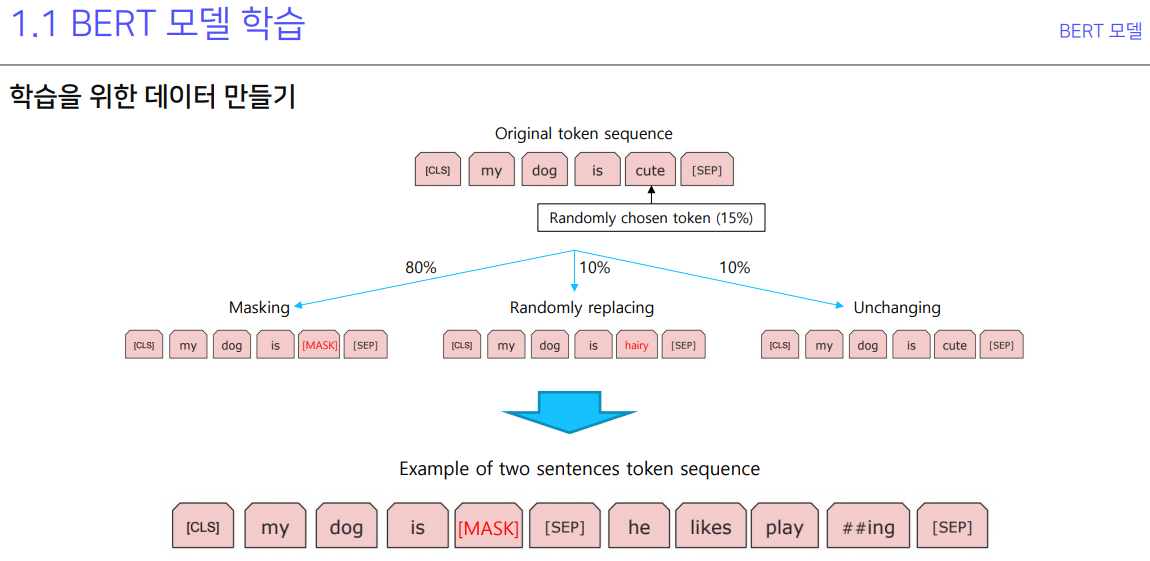
데이터로 넣을 때 데이터셋 만드는것과 데이터로더 만드는것을 확실하게 구분해서 생각하자. 데이터셋은 밥을 만드는거고 데이터로더는 모델한테 밥을 어떻게 먹일거냐.. 적절한 비유인듯. 위 사진은 다음 문장 예측 모델
실습
Day4_실습자료0BERT_MASK_Attack.ipynb의 사본
transformers에 내장되어 있는 fill-mask로 mask 채워서 개인정보 유출하기.
Day4_실습자료1한국어_BERT_pre_training.ipynb의 사본
데이터 만들고 데이터셋 만들고 로더 만들고 Bert넣고 config 설정하고 학습하는 모든 과정들이 담겨있다. 이해가 잘 안가서 계속 봐야 할듯.
피어세션
다같이 실습내용 봤었음. 다시 보자.
원래 bert config라고해서 그 모델 config에 해당하는거 있는데 autoconfig를 불러와서 사용하면 오히려 안된다.
day3 실습에서 pooler랑 hidden state 0 layer 랑 같아야 한다. 강의에서 그렇게 말해줬다 함.
electra 어쩌구, kobert 보다 bert multi (링거?)가 잘나왔다. ko-electra가 잘나왔다.
행동
낮에 실습한거 보고 저녁에 프로그래머스 월간코드 챌린지 했음.
'과거의 것들 > AI Tech boostcamp' 카테고리의 다른 글
| P-stage2 [Day6] autoML로 인한 최적화된 환경 너무좋다. (0) | 2021.11.30 |
|---|---|
| P-stage2 [Day5] (0) | 2021.11.30 |
| P-stage2 [Day3] (0) | 2021.11.30 |
| P-stage2 [Day2] (0) | 2021.11.30 |
| P-stage2 [Day1] (0) | 2021.11.29 |