수업내용
실습
GPT-2 생성옵션들. 생성모델의 경우 어떤 규칙을 가지고 생성하느냐에 따라 자연어 성능이 천차만별임
Day9_실습자료0자연어_생성법.ipynb의 사본
Day9_실습자료1Few_shot_learning.ipynb의 사본
ko-GPT 가지고 zero-shot, one-shot, few-shot 해보기. GPT에 비해 많은 데이터로 학습을 한게 아니다보니 잘 작동하지 않는다.
fine-tuning해서 우리의 목적에 맞게 해보자.
Day9_실습자료2KoGPT_2_기반의_챗봇.ipynb의 사본
챗봇 만들어보기.
다음 수업 이론
1. BERT 이후의 다양한 LM
1.1 XLNet
1.2 RoBERTa
1.3 BART
1.4 T5
1.5 Meena
1.6 ControllableLM
엄청 많으니까 걍 PPT 봐라.
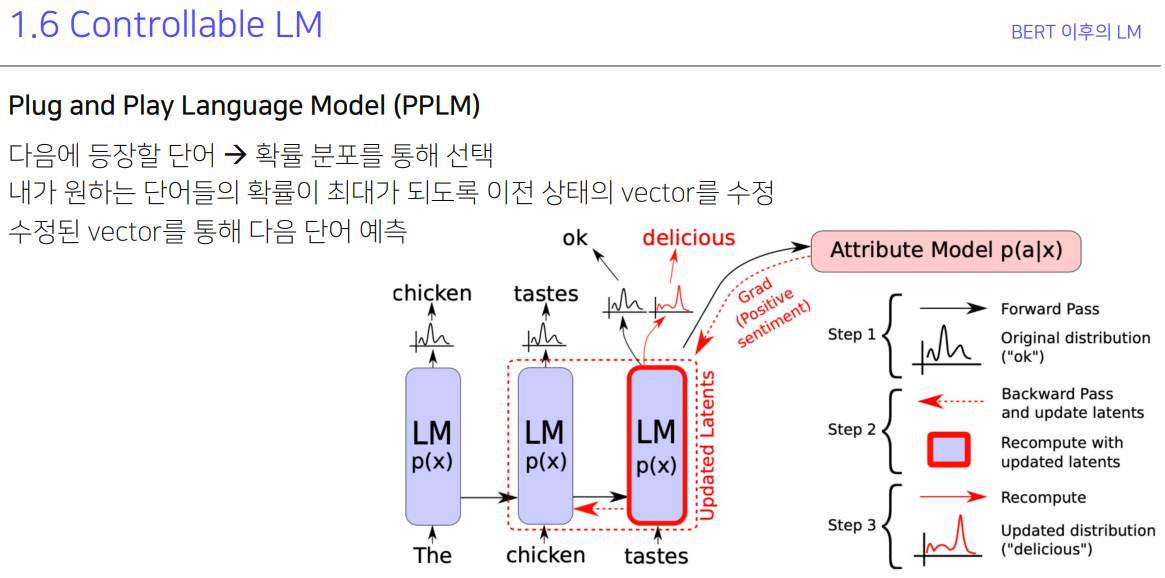
chicken tastes ok가 나왔을 때 LM의 경우 얘를 delicious로 나오도록 파라미터를 조정하는게 아니라 단어와의 관계성을 통해 chicken을 넣었을 때 delicious가 나오도록 임베딩을 조절함. 그래서 임베딩이기 때문에 복합적인 감정 등의 정보가 가능해진다.
모델이 학습할 때 윤리적 문제에 대해서 말하자면 좋은말만 가지고 학습한거랑 나쁜말만 가지고 학습한게 있을 때 좋은말만 가지고 학습한다고 윤리적으로 올바른게 아님. 예를들아 좋은말만 가르친 애한테 '난 마약이 좋아' 하니까 덩달아 '나도 마약이 좋아' 라고 대답했다고 함. 그래서 현재 언어모델 학습은 좋은말, 나쁜말 모두 가르친 후에 나중에 윤리용 필터링을 만드는 방식으로 발전하고 있다.
2. Multi-modal Language Model
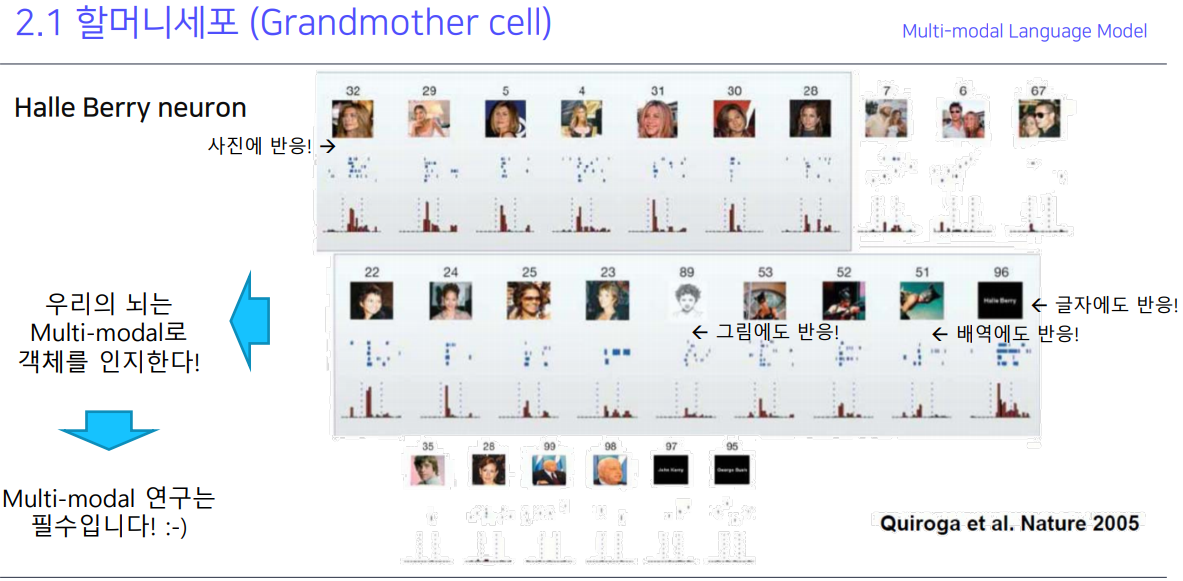
우리는 하나의 개념이 있으면 그 개념을 글자로 봐도 떠오르고, 사진을 봐도 떠오르고, 비슷한 걸 봐도 떠오름.

이런 작업은 자연어 질문에 대한 이해와 사진으로 볼때도 CV에 대한 이해 두개 다 필요한데 잘 해내오 있다.


두개 같이 정보 줘서 했더니 더 잘 맞춘다.

생성도 한다. Dall-e. 한국어도 어느정도 되는거 확인 했음.
multi-modal이 미래다! 끝.
행동
훈련데이터 + 훈련데이터 0.7 비율의 외부데이터 로 해봤는데 그냥 훈련데이터의 best인 78.7% 에서 76.0%으로 떨어짐.
그냥 alpha, beta 붙이니까 PB 0.1% 내려감. 역시 제대로 할려면 ner로 해야하는 듯.
앙상블 하니까 성능이 오른것 같긴 한데 제출제한으로 직접적인 비교는 못했다. 아쉽다. 훈련비율 0.4로 섞은데 val acc은 제일 잘 나왔음.
내일 날짜로 wrap-up이랑 발표자료 올릴거임.
'과거의 것들 > AI Tech boostcamp' 카테고리의 다른 글
| P-stage3 [Day1] 역사, metric 등 (0) | 2021.11.30 |
|---|---|
| P-stage2 마지막 정리 (0) | 2021.11.30 |
| P-stage2 [Day8] 외부 데이터, smooth, ner (0) | 2021.11.30 |
| P-stage2 [Day7] focal loss, 다른 tokenizer들 (0) | 2021.11.30 |
| P-stage2 [Day6] autoML로 인한 최적화된 환경 너무좋다. (0) | 2021.11.30 |