![P-stage4 [day11] (8강) 모델 최적화 기법(3) : Quantization 이론](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbWPov9%2Fbtrm9D9caC1%2FAAAAAAAAAAAAAAAAAAAAAFJPC9qeVdfT0m3DGzJo9Ze4wsYhO52FgCFwOtcjhsUS%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1767193199%26allow_ip%3D%26allow_referer%3D%26signature%3DzP%252Fc61LPK2YVGdQTofV0rJDx3ls%253D)
수업 내용
(8강) 모델 최적화 기법(3) : Quantization 이론



탄생 배경.
Quantization을 하면 모델 사이즈도 줄고, 에너지 관점에서도 이득임. 정보 양이 작아지다 보니 메모리에도 더 많이 넣어서 효율적인 사용.

"우린 왜 Floating point를 사용해야 하는가"
What Every Computer Scientist Should Know About Floating-Point Arithmetic

float 일때의 최소, 최대는 quantization의 최소, 최대 일때랑 같아야 한다는 사실과 float에서 0은 int에서도 무조건 0 이어야 한다는 사실로 만들어진 식.
Quantization for Neural Networks
(여기서 다 가져오셨다고 함.)


Y 행렬의 한 원소를 구하는 데는 p번의 곱셈, p-1번의 덧셈이 필요함. 이걸 m,n만큼 해야하니 mpn번의 곱셈, m(p-1)n번의 덧셈.

위에서 정의한 Quantization 식으로 풀어낸 정의.


ReLU의 일반화 확장으로 만든 quantization에서의 relu 정의


Conv 뒤엔 어차피 batchnorm, relu 나오는데 두개를 합치는게 어떨까 해서 두 layer를 fuse하여 하나의 Conv layer로 표현.
그래서 합치는데 아까 quantization 한것도 affine transform이고 이것도 affine transform이니까 둘이 묶어 하나의 affine transform으로 만들어 사용.

애초에 batchnorm이란게 channel에서 동일한 픽셀 위치에서 그 값 하나만 변경하는 거니까 1x1 conv라고 볼 수 있다.
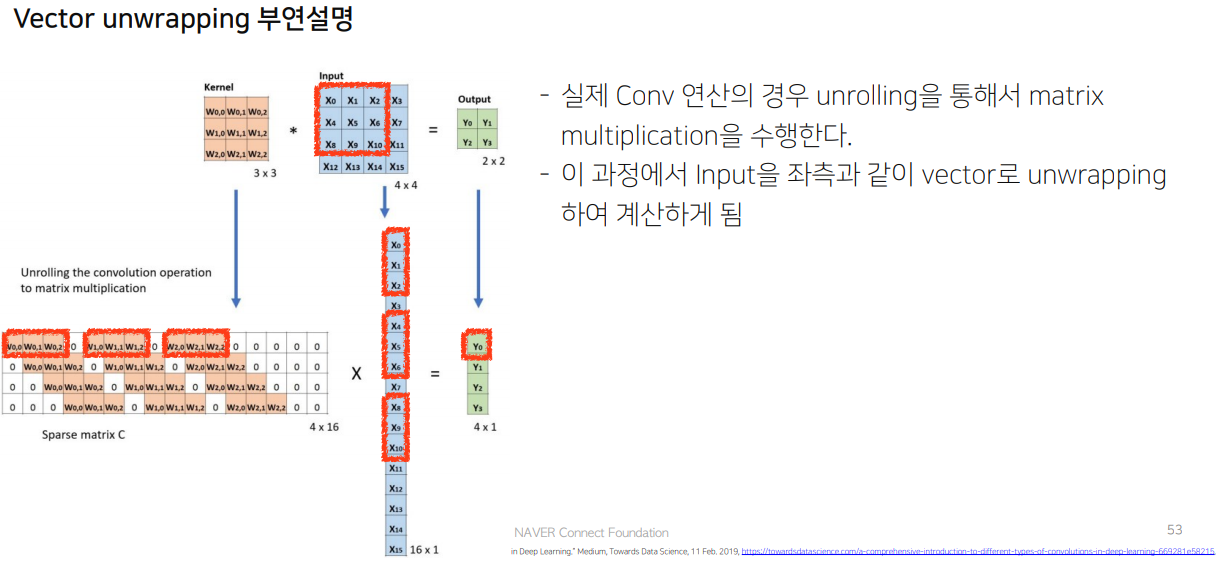

unwrapping을 하는 이유는 컴퓨터 계산 구조 문제임.



계산이 줄어서 속도가 빨라졌다.
'과거의 것들 > AI Tech boostcamp' 카테고리의 다른 글
| P-stage 4 [day13] (10강) Nvidia GPU를 위한 TensorRT, DALI (0) | 2021.12.05 |
|---|---|
| P-stage4 [day12] (9강) 모델최적화기법(3); Quantization 실습 (0) | 2021.12.05 |
| P-stage4 [day8] (0) | 2021.12.05 |
| P-stage4 [day7] (7강) 모델최적화기법(2); Tensor Decomposition 실습 (0) | 2021.12.05 |
| P-stage4 [day6] (6강) 모델최적화기법(2); Tensor Decomposition 이론 (0) | 2021.12.05 |