이제 sql문을 자동으로 해주는 ORM인 JPA를 사용할 건데 내용이 엄청 방대에서 왜 필요한지랑 큰 그림만 볼거다. 정말정말 많이 쓰인다. 그 전에 ORM이 뭔지부터 알아보자. 대충 적을거.
ORM은 Object-Relational Mapping의 줄임말인데 자기가 사용하는 언어의 객체(여기선 자바)로 정의하면 ORM이 알아서 sql문을 짜줘서 db에 명령한다. 이 역할을 자바 진영에서 수행하는게 JPA(Java Persistence API)이고 JPA가 자바 진영의 ORM 표준이다. 표준이 중요한 이유는 스프링에서 보장해준다는거.

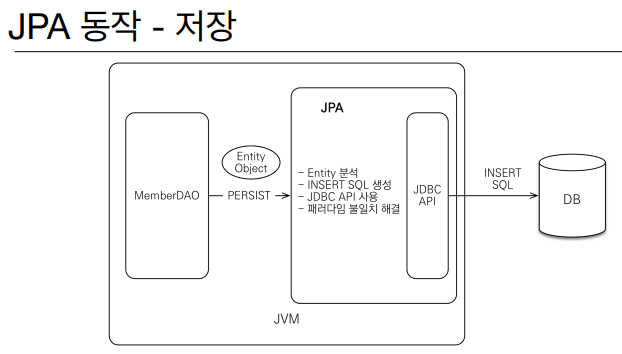

이게 정말 좋은 이유는 기존에 개발자들은 무슨 객체를 만들고 정의하려고 해도 db의 sql문까지 고려하면서 만들어야 되기 때문에 불편한것도 있지만 객체지향적으로 생각을 못하게 방해한다. 그래서 DB에 관해 아무것도 모르는 상태로 그저 자바 객체를 정의하고 만들고 자바로만 하고있을 뿐인데 DB에는 알아서 저장하고 꺼내고 수정하고 하도록 해서 진짜 자바 객체로만 생각하면 된다는 것.
더 좋은건 이미 최적화 및 진짜 객체처럼 다룰 수 있게끔 되어있다. 처음에 불러올 땐 db에 불러오지만 캐시에 저장해놔서 2번째로 같은걸 불러오면 캐시에서 불러오던가, 그냥 막 리스트에 저장할 수 있고 같은 걸 불러오면 같은 트랜잭션 내에선 같은 인스턴스로 정의되고, 트랜잭션 시작점 밑 끝점도 두 줄이면 되고 lazy하게 불러올지 바로 불러와 조인 하면서 최적화 성능을 높일지 선택할 수 있고 등등.. 정말 좋다.
하지만 ORM을 사용했을 때 대부분의 오류는 DB에서 나오는 것도 있어서 객체와 RDB 두 개를 정말 깊이있게 다 알아야 비로소 모든 성능을 끌어올려 사용할 수 있다. 그래서 다 아는것이 정말 중요하다.
설치방법은 dependency에 추가해주면 됨.
//JPA, 스프링 데이터 JPA 추가
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
사용법도 DB에 넣고자 하는 객체를 @Entity로 해주면 된다.

@Id는 pk가 뭔지이고 @GenerateValue에서 strategy가 GenerateionType.IDENTITY면 db에서 생성해서 올려주는 id를 채택해서 받아오겠단 뜻임. @Table과 @Column으로 db에 들어갈 이름을 따로 지정해줄 수 있다. 안 지정하면 그대로 DB에 snake case로 바뀌어서 들어감.
레퍼지토리를 보자.
package hello.itemservice.repository.jpa;
import hello.itemservice.domain.Item;
import hello.itemservice.repository.ItemRepository;
import hello.itemservice.repository.ItemSearchCond;
import hello.itemservice.repository.ItemUpdateDto;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Repository;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.util.StringUtils;
import javax.persistence.EntityManager;
import javax.persistence.TypedQuery;
import java.util.List;
import java.util.Optional;
@Slf4j
@Repository
@Transactional
public class JpaItemRepositoryV1 implements ItemRepository {
private final EntityManager em;
public JpaItemRepositoryV1(EntityManager em) {
this.em = em;
}
@Override
public Item save(Item item) {
em.persist(item);
return item;
}
@Override
public void update(Long itemId, ItemUpdateDto updateParam) {
Item findItem = em.find(Item.class, itemId);
findItem.setItemName(updateParam.getItemName());
findItem.setPrice(updateParam.getPrice());
findItem.setQuantity(updateParam.getQuantity());
}
@Override
public Optional<Item> findById(Long id) {
Item item = em.find(Item.class, id);
return Optional.ofNullable(item);
}
@Override
public List<Item> findAll(ItemSearchCond cond) {
String jpql = "select i from Item i";
Integer maxPrice = cond.getMaxPrice();
String itemName = cond.getItemName();
if (StringUtils.hasText(itemName) || maxPrice != null) {
jpql += " where";
}
boolean andFlag = false;
if (StringUtils.hasText(itemName)) {
jpql += " i.itemName like concat('%',:itemName,'%')";
andFlag = true;
}
if (maxPrice != null) {
if (andFlag) {
jpql += " and";
}
jpql += " i.price <= :maxPrice";
}
log.info("jpql={}", jpql);
TypedQuery<Item> query = em.createQuery(jpql, Item.class);
if (StringUtils.hasText(itemName)) {
query.setParameter("itemName", itemName);
}
if (maxPrice != null) {
query.setParameter("maxPrice", maxPrice);
}
return query.getResultList();
}
// @Override
// public List<Item> findAll(ItemSearchCond cond) {
// String jpql = "select i from Item i";
//
// List<Item> result = em.createQuery(jpql, Item.class)
// .getResultList();
// return result;
// }
}JPA는 EntityManager를 주입받아야 해서 생성자에서 받게 해놓았다.
persist로 저장함. 또 upate() 함수를 보면 한줄 한줄 set을 하고 있는데 그럼 문제있는거 아니냐 싶겠지만 클래스 전체에 @Transactional을 걸어놨기 때문에 각 함수 모두에 @Transactional이 걸려있고, 이 뜻은 해당 함수가 시작하기 전 트랜잭션이 시작되고 해당 함수가 끝나면 트랜잭션이 그때 끝나서 괜찮다. 그리고 나중에 더 배우는데 내부에서 캐시가 뭐 어쩌구 한다 함. jpql은 sql문과 정말 유사한거인데 자바 객체를 가지고 하는거임. 여기서도 동적이 어렵긴 마찬가지.
이제 설정과 테스트를 해보면 된다.





로그를 보면 지가 sql문 짜서 저장하고 조회하고 하는걸 볼 수 있다. 근데 왜 update함수인데 update가 없냐??면 테스트는 끝나고 마지막 트랜잭션이 rollback하기 때문에 jpa sql은 update를 안한다. 만약 진짜 db에 넣으려고 @Commit을 하면 실제로 update를 하는걸 볼 수 있음.
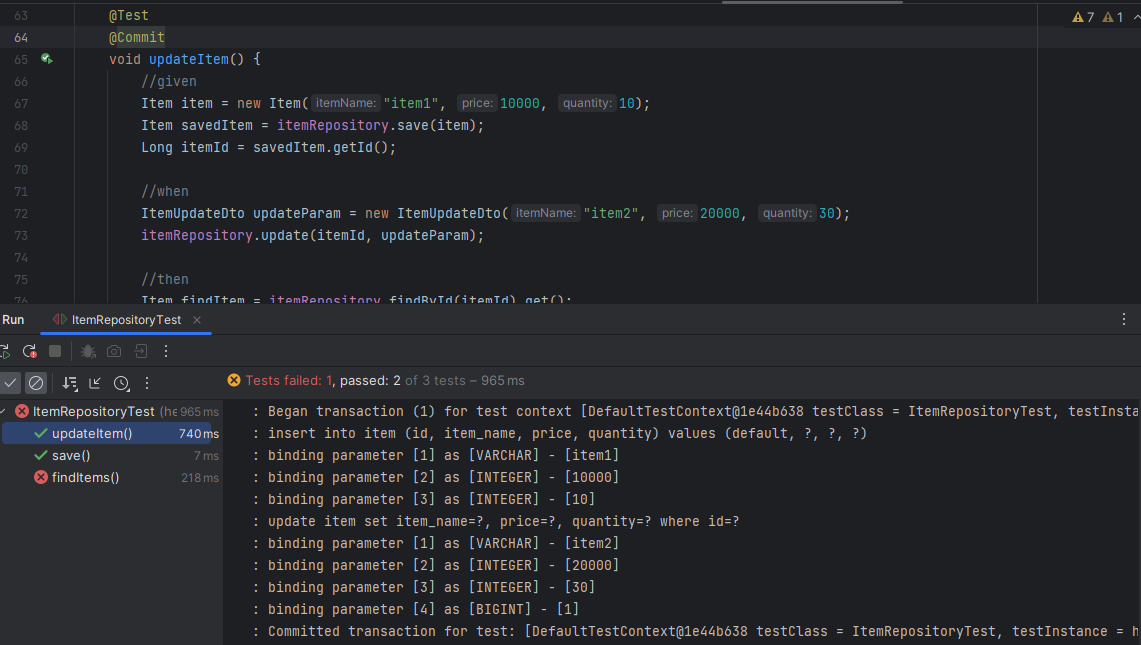
동작 설명을 좀 해보면


save의 경우 아예 처음부터 만드는거라 id값이 비어있는데 이는 @Id하고 뒤에 @GeneratedValue를 db가 올리는 대로 받는걸로 했기 때문임.


update의 경우 별거 없는것 처럼 보이는데 이상한게 있다. save의 persist처럼 저장하는 함수가 없는데 알아서 업데이트 한다는 것.
이게 어떻게 된 거냐면 트랜잭션을 시작하고 객체를 가져올 때 스냅샷이라는걸 만들어서 그 객체를 따라다니다가 트랜잭션이 커밋되는 시점 즉, 정상 종료되는 시점에 해당 각체가 바뀌었나 확인한다. 만약 바뀌었으면 자동으로 update를 하는 것이다. 테스트의 경우는 롤백하기 때문에 안바뀌어서 update를 하지 않았던 것. 자세한건 jpa 강의에서 알려줌.
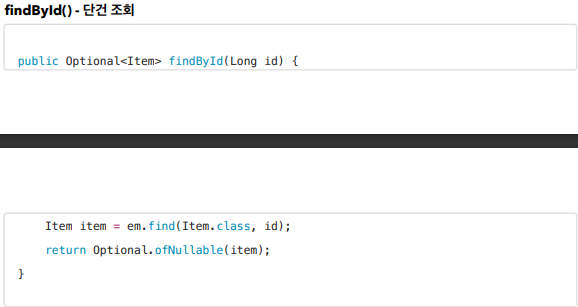

조회도 자기가 만들지만 뒤에 이상한게 붙는다. 이건 나중에 join같은거 할 때 안겹치도록 하기 위해 만드는거.




jpql은 자바 객체용 sql이라고 생각하면 되어서 자바 객체 이름이 들어간다.
하지만 얘도 동적쿼리는 피해갈 수 없어서 querydsl같은걸 거의 필수로 가지고 다닌다.
예외 변환을 알아보자.


만약 이런 repository단에서 에러가 터진다고 했을 때 이 클래스를 바로 실행시키는게 서비스니까 바로 서비스로 예외가 갈 것이다. 그럼 예외가 db용 에러를 알고 있어야 해서 서버스 계층의 순수성이 깨지는거 아니냐?
그건 @Repository를 사용하면 예외 처리용 프록시 클래스가 만들어지고 이걸 실행하는거라 서비스로 갈때는 예외를 바꿔서 돌려준다. 즉 @Repository 애노테이션만 있으면 스프링이 예외 변환을 처리하는 AOP를 만들어준다.


그래서 @Repository랑 원래 있던 @Transactional을 다 빼주면 그때야 그냥 클래스가 실행되는걸 알 수 있음.


더 자세한건 jpa ORM 강의를 듣도록..
'CS > 김영한 스프링 강의' 카테고리의 다른 글
| 스프링 DB 2편 - 데이터 접근 핵심 원리 - 섹션7. 데이터 접근 기술 - Querydsl (0) | 2023.08.25 |
|---|---|
| 스프링 DB 2편 - 데이터 접근 핵심 원리 - 섹션6. 데이터 접근 기술 - 스프링 데이터 JPA (0) | 2023.08.23 |
| 스프링 DB 2편 - 데이터 접근 핵심 원리 - 섹션4. 데이터 접근 기술 - MyBatis (0) | 2023.08.20 |
| 스프링 DB 2편 - 데이터 접근 핵심 원리 - 섹션3. 데이터 접근 기술 - 테스트 (0) | 2023.08.20 |
| 스프링 DB 2편 - 데이터 접근 핵심 원리 - 섹션2. 데이터 접근 기술 - 스프링 JdbcTemplate (0) | 2023.08.19 |