JpaRepository를 사용하면 안의 실제 구현물은 어떤지 보는 시간


이런 findById니 findOne... 인 어쩌구 하는것들도 직접 EntityManager를 가져와 구현했듯이 다 똑같은 것들이다.


재밌는건 jpa에서 카운트 같은걸 자체 지원하지 않기 때문에 나름내로 알아서 sql문으로 구현한 모습
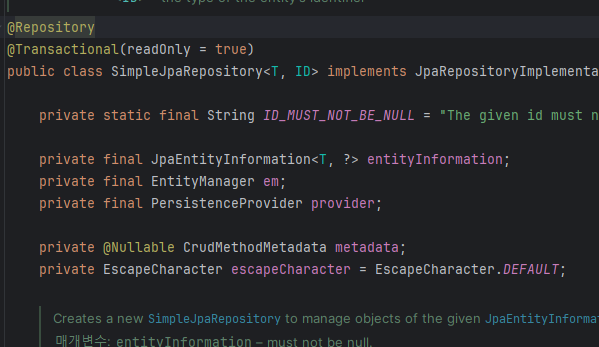
어노테이션이 @Repository와 @Transactional 두가지가 있는데 각각의 의미는 다음과 같다.
@Repository는 안에 @Component가 있기 때문에 스프링한테 이걸 bean에다가 넣으라는 의미도 있지만, repository는 각각의 db들이 서로 실제 명령어들도 다르고 에러도 다르게 뜰 텐데 @Repository가 이걸 받아 일정한 에러로 변환시켜준다.
@Transactional은 만약 내가 @Transactional을 하고 들어가면 그대로 이어서 받아 들어가겠지만 내가 하지 않더라도 안에서 얘가 해주고 들어간다는 것. 좋은건 readOnly를 해서 flush를 하지 않기 때문에 성능의 이점을 더 얻으려고 하는 모습. 그래서 save는 readOnly를 안사용하기 위해 덮어씌운다.



새로운거면 persist, 아니면 merge하는데 직접 merge를 하다가 잘못하면 row가 날라갈 수 있으므로 내가 commit하지 않고 영속성 컨텍스트가 알아서 판단하게끔 그냥 끝내는 것이 좋다.
save 함수에서 이 엔티티가 실제 db에 이미 들어있는지 아닌지를 id로 확인하는데, 이걸 이해할 필요가 있다.
즉, 밑의 isNew 과정이 어떻게 되는지 알아두어야 한다.

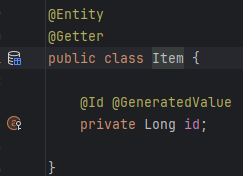

id에 아무런 값도 주지 않을경우 그냥 long이 아니라 null이 가능한 Long이므로, id는 null이 된다. isNew는 해당 엔티티의 id가 null일 경우나 일반 타입일 시 값이 0일 경우 db에 없는 row라고 판단해 persist를 한다.



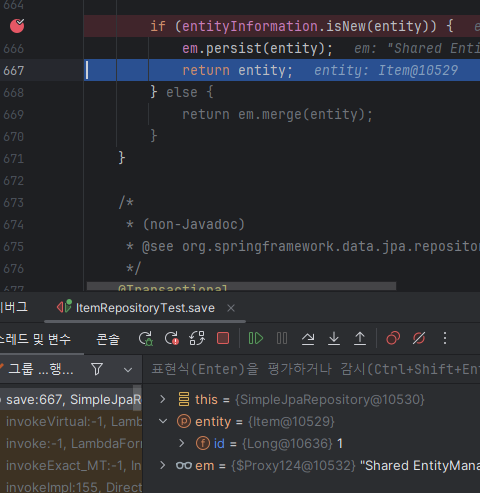
그래서 db에 넣는 persist 작업을 했을 때 @GeneratedValue이므로 id가 생성되고 해당 sql문이 잘 나가는걸 볼 수 있다.

되도록이면 그냥 @GeneratedValue를 사용하여 원래 설정 그대로 하는게 좋다. 그런데 난 id가 자동으로 증가되는게 싫고 원하는걸 직접 하고싶다거나 db를 쪼개서 관리해야 해 내가 직접 id를 관리해야 하는 상황이 올 수 있다.
그래서 일단 id를 내가 지정해서 하면 db에 없는데도 id가 null이 아니므로 이미 들어있다고 판단해 isNew에서 persist가 아닌 merge를 한다. 하지만 merge는 정말 들어있는지 아닌지 쿼리를 한번 더 날리기 때문에 비효율적이다.


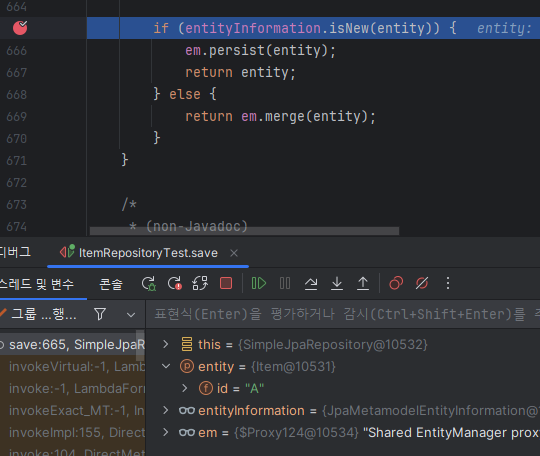
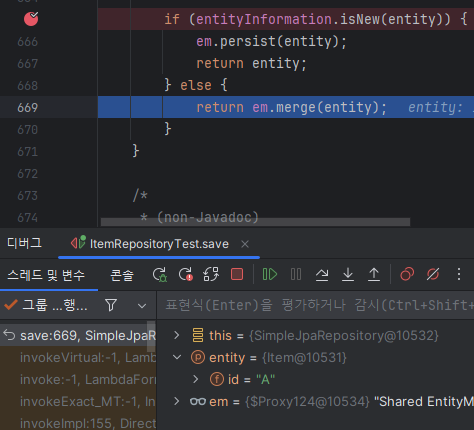

merge는 실제로 들어있는지 where를 한번 날려보고 없다는게 판단이 되어야 insert를 한다. 즉 2번 하는 것.
그래서 직접 지정하고 싶다면 @EntityListeners의 Audit를 사용하여 생성 날짜를 이용하는 방법을 추천한다. 이 엔티티가 새거인지 아닌지 판단을 id가 아니라 createdDate가 비어있으면 새거라고 판단하는 것이다.
방법은 Persistable을 상속하여 isNew를 override 해준다.
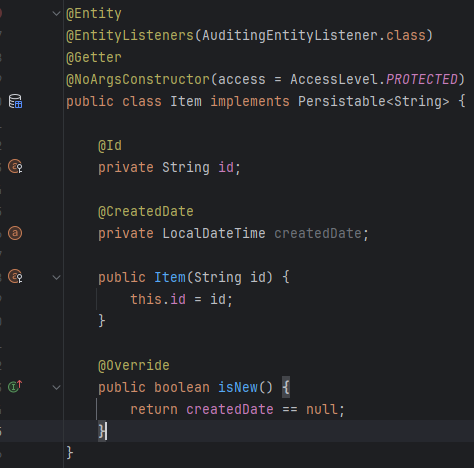


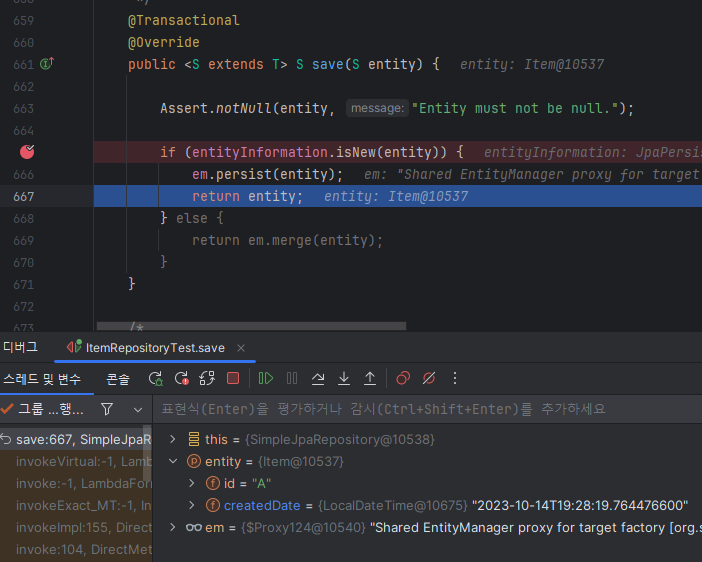
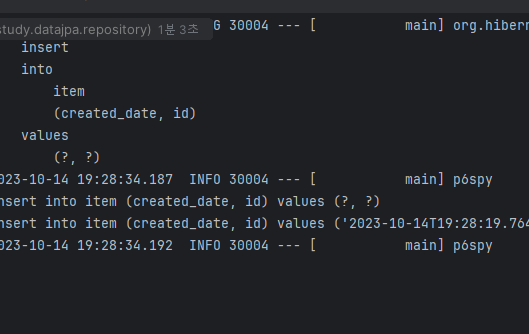
그럼 내가 원하는 대로 id를 지정할 수 있고, persist기 때문에 한번만 나간다.
'CS > 김영한 스프링 강의' 카테고리의 다른 글
| 실전! Querydsl - 섹션2. 예제 도메인 모델 (0) | 2023.10.17 |
|---|---|
| 실전! 스프링 데이터 JPA - 섹션7. 나머지 기능들 (0) | 2023.10.15 |
| 실전! 스프링 데이터 JPA - 섹션5. 확장 기능 (1) | 2023.10.14 |
| 실전! 스프링 데이터 JPA - 섹션4. 쿼리 메소드 기능 (1) | 2023.10.14 |
| 실전! 스프링 데이터 JPA - 섹션3. 공통 인터페이스 기능 (0) | 2023.10.11 |