3.0 개요
gcc c 컴파일러는 기계어 커드를 문자로 표시히는 어셈블리 코드의 형태로 출력을 만들어 프로그램의 각인스터럭션을 만들어낸다. 그러고 나서, gcc는 어셈블러와 링커를 호출하여 어셈블리 코드로부터 실행 가능한 기계어 코드와 기계어 코드의 읽기 쉬운 형태인 어셈블러 코드에 대해 자세히 살펴본다.
자바를 포함한 c언어는 고급 언어로써 컴파일하면 잘 훈련된 컴파일러 개발자만큼의 코드를 만들어준다. 거기다 기계에 의존적이라 재활용이 힘든 어셈블러와 달리 고급 언어는 다른 많은 컴퓨터에서도 실행이 가능하다(즉, 추상화가 잘 되어있다). 또한 타입 체크 등 프로그램 에러에서도 도움을 준다.
그런데도 왜 기계어를 배워야 하는가? 이는 프로그램 최적화와 동작 방식을 이해하는 데 있다. 고급 언어의 컴파일러로 어셈블리 코드를 만드는데, 이 코드를 이해하면 컴파일러의 최적화 성능을 알 수 있고, 비효율성을 분석할 수 있다. 또 고급 언어에서 제공하는 추상화 계층 때문에 이해가 필요한 프로그램의 런타임 동작이 감춰지는 경우도 있는데, 예를 들면 쓰레드 패키지를 사용해서 동시성 프로그램을 작성ㅇ할 때 어떻게 프로그램의 데이터가 공유되고, 쓰레드들이 이들을 사적으로 어떻게 유지하고, 공유된 데이터가 정확히 어디서, 어떻게 접근되는지 아는 것이 중요하다. 이러한 정보는 기계어 코드 수준에서 알 수 있다. 또 다른 예는 프로그램을 공격하는 방식 중 상당수가 프로그램이 런타임 제어 정보를 저장하는 방식의 미묘한 차이와 관련이 있는데, 시스템 제어권을 획득하기 위해 시스템 프로그램의 약점을 활용하고 있다. 이러한 취약성이 어떻게 발생회는지, 어떻게 막을 수 있는지를 이해하려면 프로그램의 기계수준 표현에 대한 지식이 필요하다. 예전엔 작성을 위해 어셈블리 코드를 알아야 했다면, 이젠 읽고 이해해야 하는 방향으로 성격이 바뀌었다.
x86-64에 기초하여 작성되는데 1978년 인텔사 최초의 16비트에서 진화를 거쳐 64비트까지 나오고, AMD도 가세했다. 이 과정 중 역사적인 관점에서 볼 때만 납득이 가는 다소 기형적인 설계를 가지게 되었다.
3.1 역사적 관점
개요에서 얘기했듯, 역사적 관점에서 봐야 이해한다과 했으니 인텔 프로세서 모델 리스트를 기계수준 프로그래밍에 영향을 어떻게 주는지를 살펴보며 리스트를 나열하겠다.
8086 (1978): IBM과 마이크로소프트의 MS-DOS 운영체제 개발 계약 체결.
80286 (1982): 주소지정 모드 추가(지금은 거의 안 사용함)
i386 (1985): 구조를 32비트로 확장. 유닉스 운영체제를 완벽하게 지원할 수 있는 최초의 컴퓨터
i486 (1989): 인스트럭션 집합은 거의 안 바꾸고 성능 개선
펜티엄 (1993): 성능개선
펜티엄 프로 (1995): 급진적인 새로운 프로세서 설계인 P6 마이크로 구조 도입. "조건형 move" 인스트럭션 클래스 추가
펜티엄/MMX (1997): 정수 벡터를 다루는 새로운 종류의 인스트럭션들을 펜티엄 프로세서에 추가. 각 데이터는 1,2,4바이트 길이. 각 벡터는 총 64비트
펜티엄2 (1997): P6 구조를 지속적으로 사용
펜티엄3 (1999): 정수나 부동소수점 데이터의 벡터 처리를 위한 SSE 인스트럭션 클래스 추가. 1,2,4바이트의 데이터가 128비트의 벡터를 형성. 이후 버전에서는 레벨 2 캐시를 칩 내에 장착함에 따라 24M개의 트랜지스터를 사용
펜티엄4 (2000): SSE를 SSE2로 확장. 114개의 새로운 인스트럭션과 함께(이중 정밀도 부동소수점을 포함하여) 새로운 자료형을 추가. 이러한 확장으로 컴파일러가 x87 인스트럭션이 아닌 SSE 인스트럭션을 부동소수점 코드 컴파일시에 사용할 수 있다.
펜티엄4E (2004): 두 개의 프로그램을 하나의 프로세서에서 동시에 실해할 수 있는 하이퍼쓰레딩(hyperthreading) 기법의 추가와 AMD사에서 개발한 IA32의 64비트 확장 구현인 EM64T도 추가되었으며, 이를 x86-64라고도 함
Core2 (2006): P6와 유사한 마이크로 구조로 복귀. 한 개의 칩 내에 멀티 프로세서를 구현한 최초의 멀티코어 인텔 마이크로프로세서. 하이퍼쓰레딩을 지원하지 않음.
Core i7, Nehalem (2008): 하이퍼쓰레딩과 멀티코어를 함께 지원하여 초기 버전은 각 코어당 두 개의 프로그램 실행을 지원하며, 각 칩당 최대 네 개의 코어까지 지원
Core i7, Sandy Bridge (2011): 256비트 벡터에 사용되는 데이터를 지원하기 위해 SSE를 확장한 AVX를 도입
core i7, Haswell (2013): 인스트럭션들과 인스트럭션 형식을 추가해서 AVX를 AVX2로 확장
대부분 x86 프로세서의 복잡성은 gcc 컴파일러가 만드는 리눅스 운영체제상의 프로그램에 관심을 가진 사람들에게는 별 문제가 되지 않는다.
3.2 프로그램의 인코딩
c 프로그램 p1.c, p2.c 작성 후 다음 gcc로 컴파일 한다.
gcc -og -o p p1.c p2.c
-g 인자는 최적화 정도인데, -og는 본래 C 코드의 전체 구조를 따르는 기계어 코드를 생성하는 최적화 수준을 적용한다. 옵션을 -o1, -o2 등으로 올리면 컴파일하는 데는 조금 더 걸리지만 최적화가 더 잘된다. 하지만 그만큼 원래 작성 코드보다 알아보기 힘들게 되고 디버그에도 어려움을 겪을 수 있다.
gcc 명령은 소스 코드를 실행 코드로 변환하기 위해 일련의 프로그램들을 호출한다. 먼저, C 전처리기가 #include로 명시된 파일들을 불러오고 #define으로 정의된 매크로를 확장한다. 그 후, 각각의 어셈블리 파일인 p1.s, p2.s를 만든다. 다음으로 이 어셈블리 코드들을 바이너리 목적코드인 p1.o와 p2.o로 변환한다 (바이너리 목적코드는 기계어의 한 유형). 마지막으로 링커는 두 개의 목적코드 파일을 라이브러리 함수들을 구현한 코드와 함께 합쳐서 최종 실행파일인 p를 생성한다(명령줄 디렉티브 -op로 명시하여). 자세한 링크 과정은 7장에서 다룬다.
3.2.1. 기계수준 코드
1.9.3절에서 기술한 것처럼 컴퓨터 시스템은 간단한 추상화 모델을 이용해 세부 내용은 감추면서 추상화의 여러가지 다른 형태를 사용한다. 이 중 2가지가 중요한데, 첫째는 기계수준 프로그램의 형식과 동작은 인스트럭션 집합구조(instruction set architecture) ISA에 의해 정의된다. 이 .ISA는 프로세서의 상태, 인스트럭션의 형식, 프로세서 상태에 대한 각 인스트럭션들의 영향을 정의한다. 대부분읜 ISA는 마치 하나의 인스트럭션이 다음 인스트럭션의 실행 전에 완료되는 순차적인 실행을 하는 것 처럼 프로그램 동작을 설명한다. 사실 프로세서는 여러 인스트럭션을 동시에 실행하지만, ISA에 의한 순차적 동작과 일치하는 전체 동작을 보이도록 해주는 안전장치를 사용한다. 둘째는 기계수준 프로그램이 사용하는 주소는 가상주소이며, 메모리가 매우 큰 바이트 배열인 것 처럼 보이게 하는 메모리 모델을 제공한다. 실제 메모리 시스템은 9장에서 설명할 것 처럼 여러 개의 메모리 하드웨어와 운영체제 소프트웨어로 구현되어 있다.
컴파일러는 C에서 제공된 코드를 프로세서가 수행하는 매우 기초적인 인스트럭션들로 변환하는 일을 대부분 수행한다. 어셈블리 코드는 바이너리로 이루어진 기계에 텍스트를 씌운 정도의 차이. 어셈블리 코드를 이해 할 수 있고, 어떻게 그들이 본래의 C 코드와 연관되었는지 이해할 수 있는 것이 컴퓨터가 어떻게 프로그램을 실행하는지 이해하는 데 중요한 단계이다.
기계어 코드는 본래의 C와 상당히 다르다.
- 프로그램 카운터 (PC, x86-64에서는 %rip)는 메모리 주소값을 가리킨다 (가상 메모리 주소)
- 정수 레지스터 파이릉ㄴ 64비트 값을 저장하기 위한 16개의 이름을 붙인 위치를 갖는다. 주소나 정수 데이터를 저장한다.
- 조건코드 레지스터들은 가장 최근에 시랳ㅇ한 산술 똔ㄴ 놀리 인스트럭션에 관한 상태 정보를 저장한다.
- 벡터 레지스터들의 집합은 하나 이상의 정수나 부동소수점 값들을 각각 저장할 수 있다.
프로그램 메모리는 언제나 가상 메모리에 접근한다. 예를 들면, ㅌ86-64 가상 주소들은 64비트 워드들로 표현된다. 이들 기계들의 현재 구현된 상태에서 상위 16비트는 0으로 지정되어야 하고, 따라서 주소는 2의 28승(64-16 이므로), 즉 256테라 바이트 범위를 넘어가는 바이트를 잠재적으로 명시할 수 있다(위에서 말한 읽는 비트가 늘어났으니 충분한 메모리 주소값 어쩌구가 이거임). 운영체제가 이 가상 주소공간을 관리해서 가상주소를 실제 프로세서 메모리 상의 물리적 주소 값으로 번역해 준다.
3.2.2. 코드 예제
다음 코드 mstore.c를
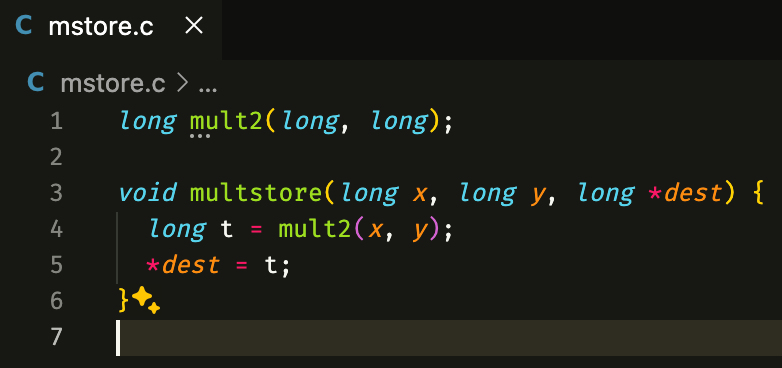
gcc -Og -S mstore.c를 사용하여 어셈블리 파일 mstore.s를 만들면 다음 내용을 포함한 다양항 선언을 포함하고 있다(이 어셈블리를 기계어 코드로 변환하여 실행하는 것).

mult2를 call하여 return 값을 담고있을 %rax에 결과값이 있을 것이므로, 이를 %rbx에 담음.

(실제로 해보면 이렇게 나온다. 효율을 증대하느라고 마이크로프로세서에서 생상하는 가이드라인에 따라 계속 보완해서 달라지는 것.)
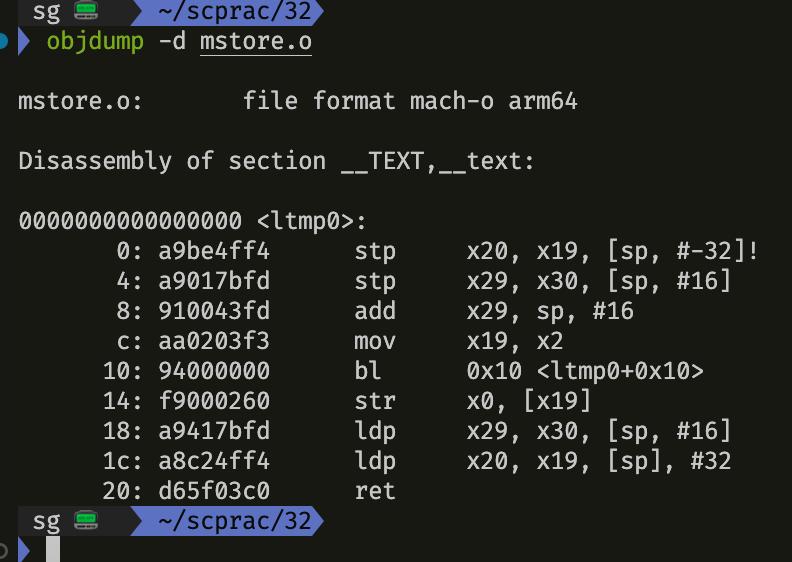
어셈블리 말고 목적코드를 바로 생성한 mstore.o 파일을 보면 다음과 같이 된다.
gcc -Og -c mstore.c53 48 89 d3 e8 00 00 00 00 48 89 03 5b c3이를 리눅스 시스템에서 프로그램 objdump에 -d 커멘트로 역어셈블러를 해볼 수 있다.
objdump -d mstore.o
이 기계어와 역어셈블된 표현에 주목해야 할 건
- x86-64 인스트럭션들은 1에서 15바이트 길이를 갖는다. 자주 쓰이는 인스트럭션들과 오퍼랜드가 적은 것들이 짧은 길이를 갖도록 하고, 반대의 경우는 좀 더 긴 인스트럭션 길이를 갖도록 함.
- 인스트럭션의 형식은 주어진 시작 위치에서부터 바이트들을 기계어 인스터럭션으로 유일하게 디코딩할 수 있도록 설계한다.
- 역어셈블러는 기계어 코드 파일의 바이트 순서에만 전적으로 의존해서 어셈블리 코드를 결정한다.
- 역어셈블러는 GCC가 생성한 어셈블리 코드와는 약간 다른 명명법을 인스트럭션에 사용한다.
(실제론 이럼. 현재 맥이라서 리눅스(인텔)에 맞는 %rbx 가 아닌 ARM에 맞게 x1.. 같은 형식으로 나온다. 위에서 말한 고급언어(C)로 작성함으로써 추상화하여 어디서든 실행하게끔 한다는 게 이런 말임.)



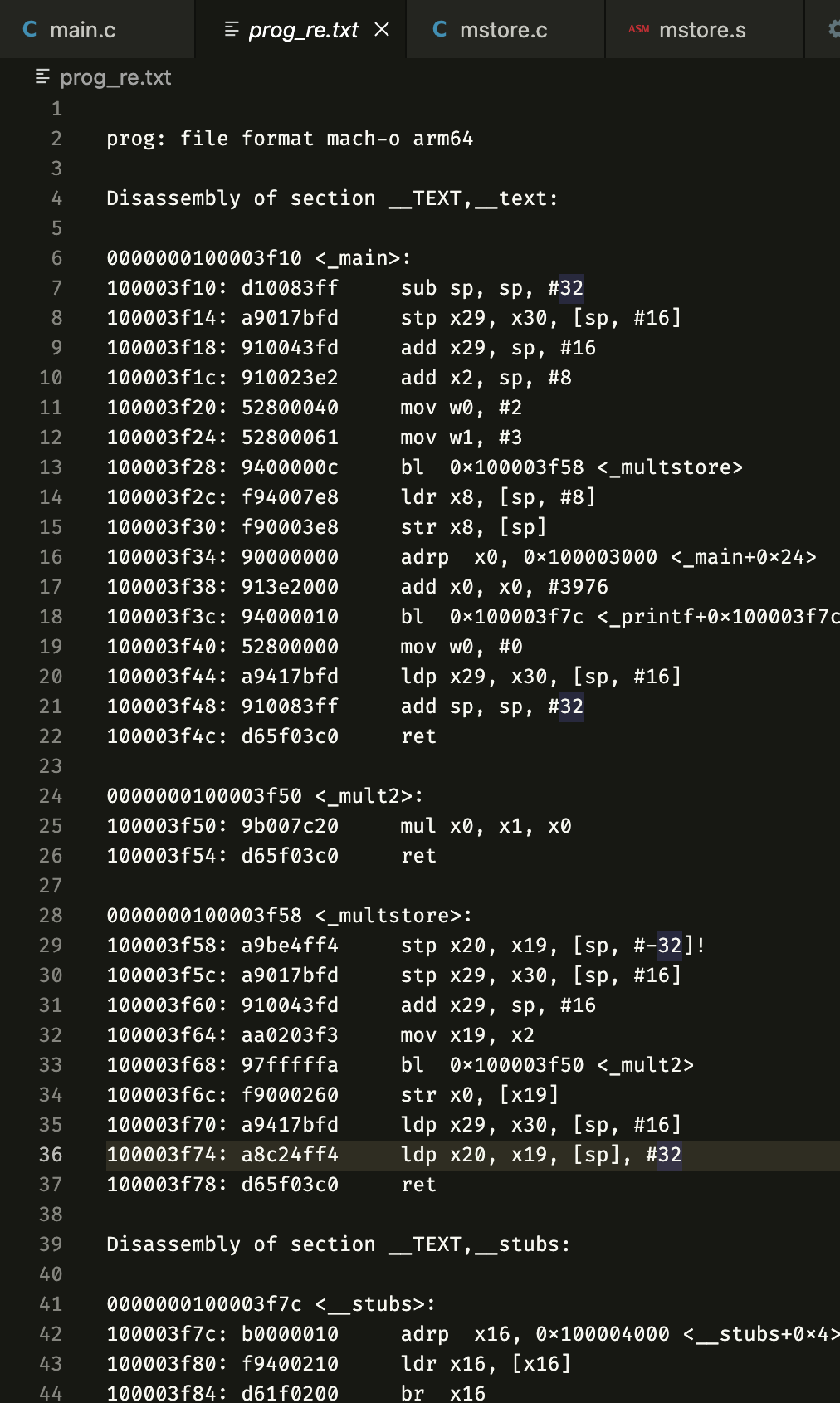
실제 실행 가능 코드를 생성하기 위해 main 함수를 포함한 main.c 파일을 만든 뒤, 링커로 연결해서 프로그램을 생성해보자.



원래 mstore을 역어셈블한 것과 거의 동일하며, 새 함수를 실행하는 주소 링크가 연결되었다는 점이 다르다. 의미없는 nop은 코드 길이를 16바이트로 늘려서 코드의 다음 블록을 메모리 시스템 성능 면에서 더 잘 배치하기 위해 이들이 삽입되었다.
(실제론 이럼)

어셈블리 시 . 으로 시작하는 모든 라인은 어셈블러와 링커에 디시하기 위한 디렉티브들이라 일반적으로 무시해도 된다. 반면, 인스트럭션들이 무엇을 하고, 이들이 어떻게 소스 코드와 연관되는지에 대한 설명이 없는데, 주석으로 설명하면 다음과 같이 된다.

3.3 데이터의 형식
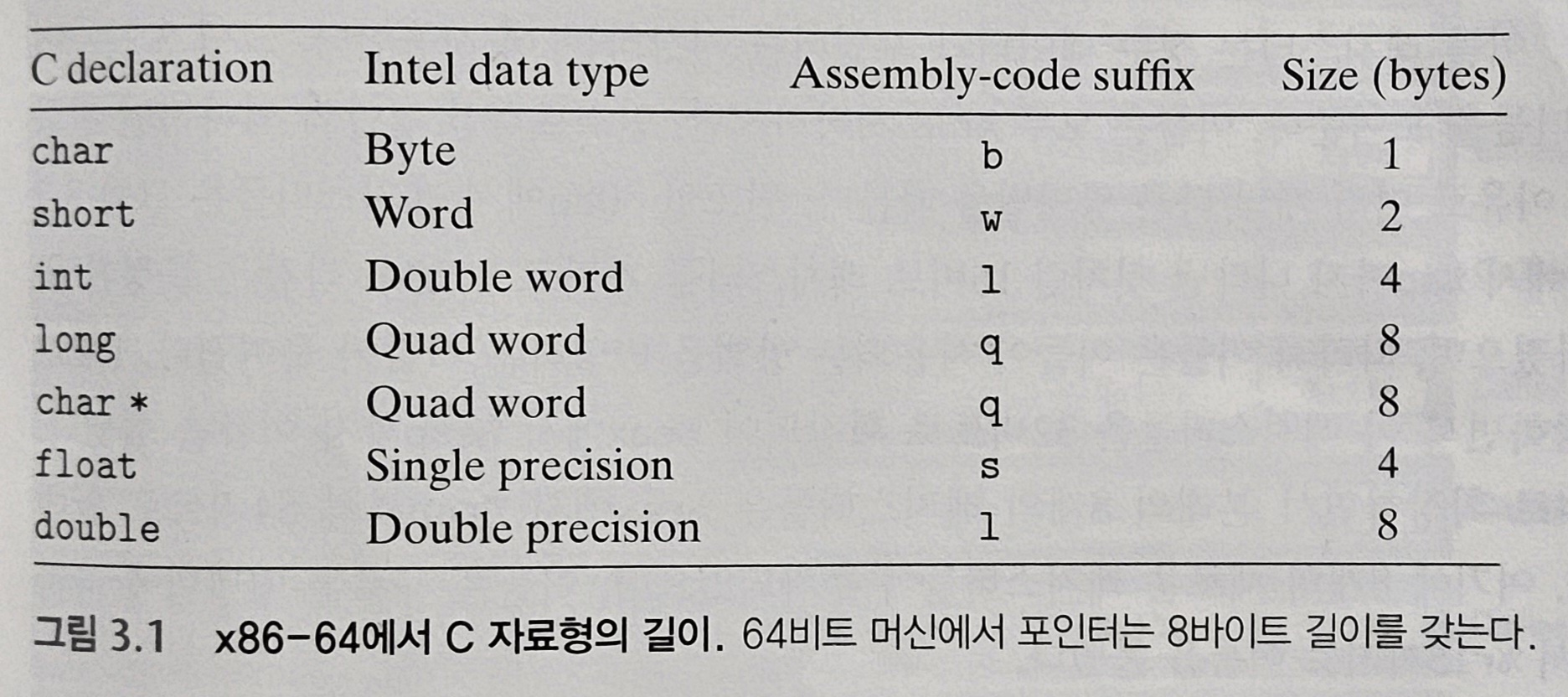
인텔 프로세서들은 근본적으로 16비트 구조를 사용하다가 확장한 형태라, 1워드를 16비트(2바이트)로 하여 이름을 붙여 32비트(4바이트)를 더블워드, 64비트를 쿼드워드라고 부른다.
※1장에서 말한, 시스템 내를 관통하는 전지적 배선군 버스를 1워드씩 타고 가는데, 요새 컴퓨터들은 4바이트 또는 8바이트를 워드 크기로 갖는다. 이 워드와 달리 명명 방식을 말하는 것.

각 크기에 따라 어셈블리 인스트럭션 명명방식이 뒤에 다른게 붙는다. movb(바이트 이동), movw(워드 이동), movl(더블워드 이동), movq(쿼드워드 이동) 등.
3.4 정보 접근하기
인스트럭션 원조인 8086에서 레지스터들은 16비트 레지스터를 가지고 있었지만 64비트까지 확대되어 새로운 명명법도 붙혀졌다. 바이트 수준에 따라 덜 중요한 레지스터에 접근하는 한계점이 있지만 64비트 연산은 레지스터 전체에 접근하는 차이점이 생겼다.

3.4.1 오퍼랜드 식별자
대부분의 인스트럭션은 하나 이상의 오퍼랜드를 가지는데, 이 오퍼랜드 목적지를 3가지 종류 immediate(상수), register(레지스터 내용), 메모리 참조를 조합하여 작성한다.




3.4.2 데이터 이동 인스트럭션
8086때 썼던 전통에 따라 1word를 2byte로 한다. 그래서 현재 자주 쓰이는 64비트 컴퓨터는 1word가 4word가 되고 4word 단위로 다뤄짐.
mov 뒤에 바이트에 따라 붙는 명령어가 다르다.



위 추가 정보 그림을 보면, mov S, D로 Source에 따라 Destination쪽에 이동되는 정보가 달라진다. 근데 이동되지 않는 값은 그대로 남아있기 때문에 의도하지 않은 값이 들어가게 되어 movz와 movs 인스트럭션이 있다. movz는 채우지 못한 부분을 0으로 채우고, s (signed)는 부호에 맞게 나머지를 채워주는 것.









어셈블리 코드에서 두 가지 특징에 주목할 필요가 있는데, 젓째는 C언어에서 포인터라고 부르는 것이 어셈블리어에서는 단순히 주소이다. 포인터를 역참조하는 것은 포인터를 레지스터에 복사하고, 이 레지스터를 메모리 참조에 사용하는 과정으로 이루어진다. 둘째, x 같은 지역변수들은 메모리에 저장되기보다는 종종 레지스터에 저장된다는 점이다. 레지스터의 접근은 메모리보다 속도가 훨씬 빠르다.







3.4.4 스택 데이터의 저장과 추출


스택의 경우, 맨 상위부터 아래방향으로 추가되거나 제거된다. %rsp가 현재 가리키는 포인터고, word 단위로 메모리에 쓰이거나 꺼내지면서 스택으로 다뤄진다. 이 과정은 mov를 포함한 2개의 인스트럭션으로 만들 수 있는데, 쌓는 것과 꺼내는 것 각각 pushq과 popq 하나의 인스트럭션으로 다뤄진다.
과정은 천천히 따져보면 쉬운데, 스택은 아래 방향으로 성장한다 했으므로 추가하는 명령인 pushq 인스터럭션은 top 포인터를 한 단위인 -8byte(quad word)후 그 위에 바로 원하는 값을 쌓는다. 즉, peek을 하면 마지막에 방금 쌓은 값 (위 그림에선 0x100~0x108)을 가리키게 되는 것, popq는 반환 값을 레지스터에 저장 후 포인터만 한 단위인 +8bytes만큼 위로 올린다.


'CS > 컴퓨터 시스템' 카테고리의 다른 글
| 2. 정보의 표현과 정리 (0) | 2023.04.09 |
|---|---|
| 1. 컴퓨터 시스템으로의 여행 (0) | 2023.04.05 |
| 0. 무슨 게시판? (0) | 2023.04.05 |