
레이어 결과를 중간에 낚아채게 해주는거임
https://github.com/biubug6/Pytorch_Retinaface/blob/master/models/retinaface.py
GitHub - biubug6/Pytorch_Retinaface: Retinaface get 80.99% in widerface hard val using mobilenet0.25.
Retinaface get 80.99% in widerface hard val using mobilenet0.25. - GitHub - biubug6/Pytorch_Retinaface: Retinaface get 80.99% in widerface hard val using mobilenet0.25.
github.com
위에거 보다 알아냈다.
만약 원본 모델이 밑에인 경우
MobileNetV1(
(stage1): Sequential(
(0): Sequential(
(0): Conv2d(3, 8, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
)
(1): Sequential(
(0): Conv2d(8, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(8, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(2): Sequential(
(0): Conv2d(16, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=16, bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(16, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(3): Sequential(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(4): Sequential(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=32, bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(32, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(5): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
)
(stage2): Sequential(
(0): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=64, bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(1): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(3): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(4): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(5): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
)
(stage3): Sequential(
(0): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=128, bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(1): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256, bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
)
(avg): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=256, out_features=1000, bias=True)
)
body2 = _utils.IntermediateLayerGetter(mov1, {'stage1': 1, 'stage2': 2, 'stage3': 3})
를 해주면
IntermediateLayerGetter(
(stage1): Sequential(
(0): Sequential(
(0): Conv2d(3, 8, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
)
(1): Sequential(
(0): Conv2d(8, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(8, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(2): Sequential(
(0): Conv2d(16, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=16, bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(16, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(3): Sequential(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(4): Sequential(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=32, bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(32, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(5): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
)
(stage2): Sequential(
(0): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=64, bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(1): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(3): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(4): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(5): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
)
(stage3): Sequential(
(0): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=128, bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(1): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256, bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
)
)이렇게 맨 밑에 fc 부분 빼고 출력됨.
엥? 뭔 차이지 싶으면 모델 아웃풋을 보면 된다.
내가 정의한 레이어 {'stage1': 1, 'stage2': 2, 'stage3': 3}대로 나뉘어서 뽑아진 결과가 나옴.
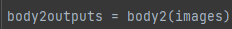


그래서 이 각각의 얘내들을 꺼내서 feature pyramid를 만드는데 쓰인다.
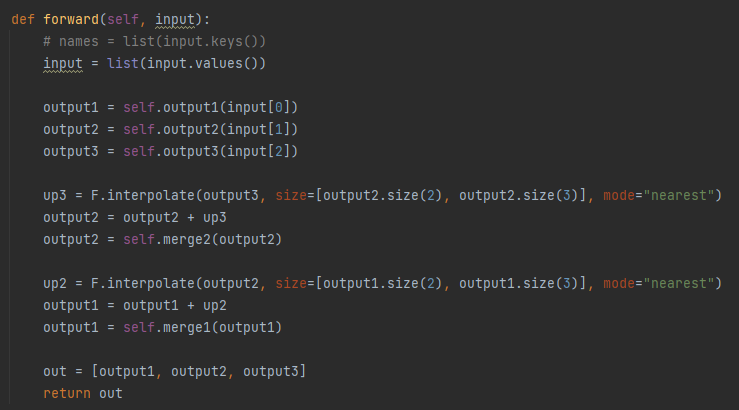
body3 = _utils.IntermediateLayerGetter(mov1, {'stage1': 1})
IntermediateLayerGetter(
(stage1): Sequential(
(0): Sequential(
(0): Conv2d(3, 8, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
)
(1): Sequential(
(0): Conv2d(8, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(8, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(2): Sequential(
(0): Conv2d(16, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=16, bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(16, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(3): Sequential(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(4): Sequential(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=32, bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(32, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
(5): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
(3): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.1, inplace=True)
)
)
)
'기술 > PyTorch' 카테고리의 다른 글
| nn.AdaptiveAvgPool1d (0) | 2022.02.10 |
|---|---|
| DistributedDataParallel 관련 링크 정리 (0) | 2021.12.27 |
| pbar 고급진 사용법 (0) | 2021.09.13 |
| nn.Sequential 에 OrderedDict 넣어줘도 됨 (0) | 2021.08.18 |
| 실제 torch weights 살펴보기 (0) | 2021.08.17 |