![AITech 학습정리-[Day 37] 모델의 시공간 / 알뜰히](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FMyvBM%2Fbtrmg4gGjZV%2FAAAAAAAAAAAAAAAAAAAAALQiFWt9qKTM-y0tYBSn-m7V6KsAEl4pBvK0eUymfqex%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DQakxaK4u3yN1TFJdhCtfyb9IVzs%253D)
======================================
학습내용
(4강) 모델의 시공간
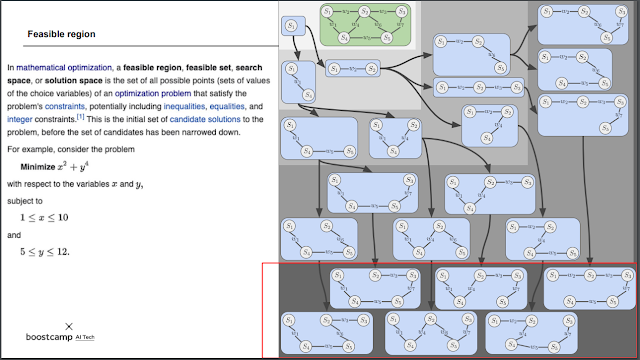
정답이 될 수 있을만한 구간을 feasible region이라고 부른다. feasible region에서 내가 원하는 조건의 답을 찾아서 구하는것. 모든 조건을 만족하는 곳.
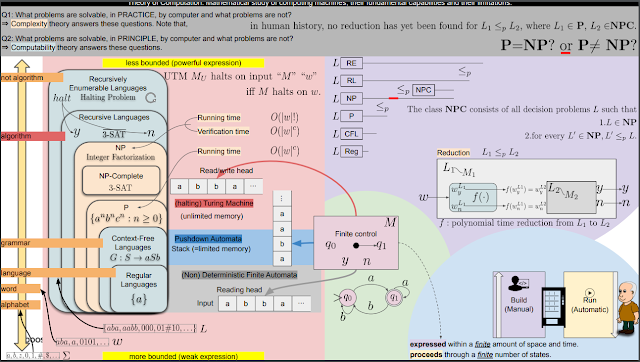
풀릴 수 있는 문제인가 아닌가의 기준점. algorithm으 넘어서면 풀 수 없거나 영원히 돌려야 하는 구간이다.
| http://news.khan.co.kr/kh_news/khan_art_view.html?art_id=201703082055005#csidx871276de9dbfc6eb1d464ad0c74a8e1 |
우리가 개 고양이 구분같은 딥러닝 알고리즘 문제를 푼다는 것은 시간을 과거로 되돌리는 것과 같다. 즉 시간이 이미 많이 지나서 둘이 섞여있는 엔트로피가 증가된 상태인 것을 과거로 돌려 다시 분리하는 것이다. 그래서 엔트로피를 거꾸로 돌리기 때문에 많은 에너지가 필요하다. 여기서 필요한건 사람의 지식 뿐 아니라 그걸 풀기위한 수식 등도 포함되어 있다.
자동화가 되면서 사람이 했던 일들을 점점 컴퓨터가 하도록 자동화됨.
| https://doi.org/10.1038/s41467-020-14578-5 |
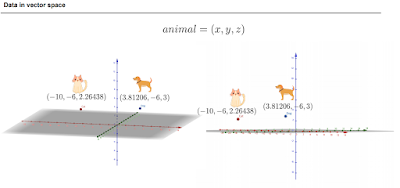
분류문제는 데이터를 좌표공간 위에 놓을 수 있기 때문에 가능한 것.
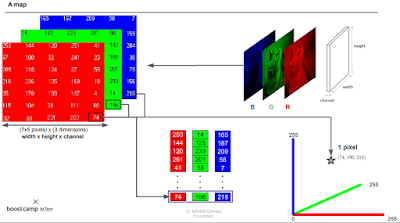
hidden dimension 들도 좌표에 올려놓는게 가능하긴 하다.
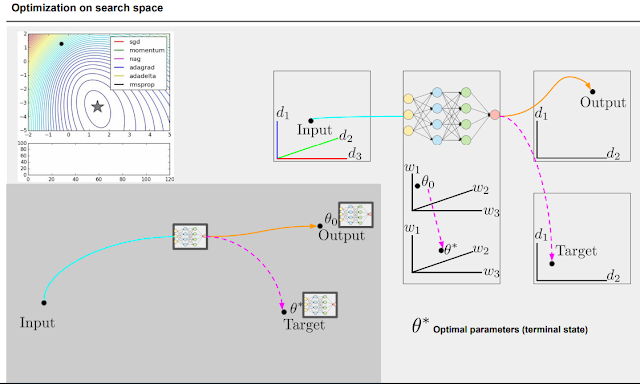
하이퍼 파라미터를 어떻게 설정하냐도 생각해 볼 수 있다. 근데 문제는 weight 같은 경우 그 값만 바꾸고 돌려보고 해도 되지만 하이퍼 파라미터는 조금 바꾸고 모델 전체를 다 돌려야 효과가 있는지 없는지를 알 수 있다. 그래서 그에 대한 방법론이 나오는 중.

https://arxiv.org/pdf/1012.2599.pdf?bcsi_scan_dd0fad490e5fad80=fwQqmV5CfHDAMm8dFLewPK+h1WGiAAAAkj1aUQ%3D%3D&bcsi_scan_filename=1012.2599.pdf&utm_content=buffered388&utm_medium=social&utm_source=plus.google.com&utm_campaign=buffer
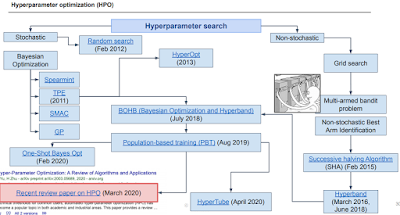
하이퍼 파라미터 정하는 것도 딥러닝으로 할 수 있지 않을까? 해서 나온게 Surrogate model. Gaussian으로 한다고 한다. 관심없어서 잘 모르겠음.
| https://arxiv.org/pdf/1611.01578.pdf |
모델 설계 자체도 기계한테 맡길 수 있다. 저렇게 사람이라면 생각하기 힘들게 설계하는데 성능은 잘 나오더라.
| https://arxiv.org/pdf/1807.11626.pdf |
search space. 정답이 될 수 있는 모델의 candidate.
모바일에 돌리라고 나온 MobileNet을 써봤는데 실제론 잘 안나오더라. 그래서 난 이렇게 하니까 잘 나왔다~ 라는 내용.
| https://arxiv.org/pdf/1812.00332.pdf%C3%AF%C2%BC%E2%80%B0 |
PROXY는 모바일에서 돌렸을 때를 가정해서 돌려주는 거다. 근데 써보니까 성능이 별로 안좋아서 그냥 PROXY 를 쓰지말자~ 하는게 취지.
| https://github.com/mit-han-lab/once-for-all |
one for all 은 모델을 설계한 뒤에 "재훈련 하지않고" 구조만 살짝 바꿔서 아무데나 넣을 수 있도록 하는 거.
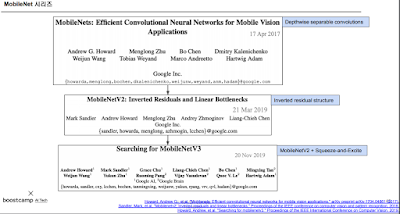
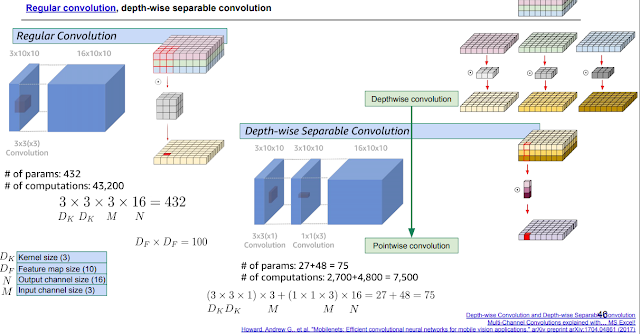
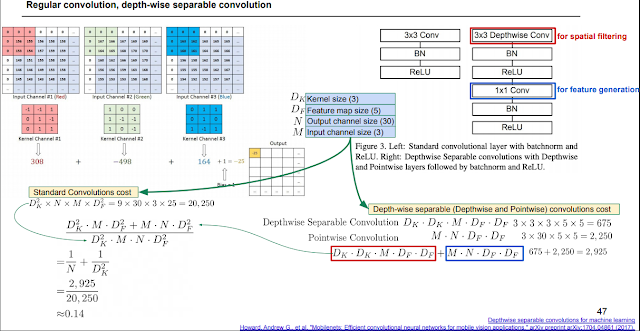
MobileNet 시리즈. 위 그림은 V1에서 한 방법을 나타내는데, 1*1conv를 사용하고 입력을 쪼개서 계산하는 방식으로 파라미터 수를 1/9로 줄였다.
toycode. 어디가 병목인가?
https://drive.google.com/file/d/112gqB8gfZt0QDaa-886h6gIm8sX7fuJw/view?usp=sharing
실행시간이 너무 오래 걸리는 부분을 찾아서 수정할 수 있을 것 같다. 지금 생각나는건 cnn의 경우 위 mobilenet처럼 1*1conv로 쪼개서 계산한다던지..
(5강) 알뜰히
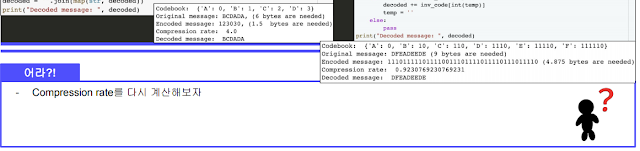
압축의 기본 방법.
| https://terms.naver.com/entry.nhn?cid=58885&docId=3570842&categoryId=58885 |
압축의 종류. 비손실은 원래 데이터로 회복 가능하지만 비손실은 다시 원래대로 못돌린다. 필요없는걸 아예 삭제시키는 방향이라.
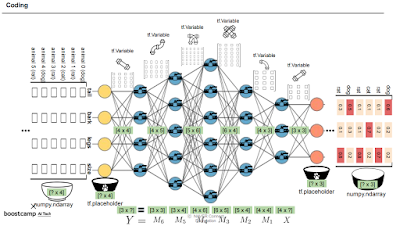
동물을 구분한다면 각 동물의 특징을 embedding vector로 나타난다. 이런것도 압축의 한 종류. 위에서 dict으로 문자를 숫자로 바꾼 것 처럼.
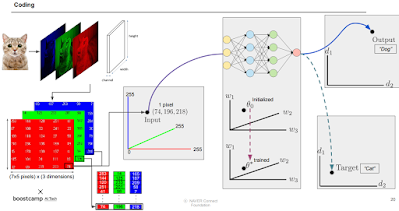
이렇게 압축된 걸로 학습을 하고 결과를 내놓는다. 나온 결과 embedding도 argmax등으로 복원해서 볼 수 있음.
뇌도 일종의 인코더. 저 3 그림을 보고 머리속에서 3이라고 label을 맞춰줌. 모델도 마찬가지.
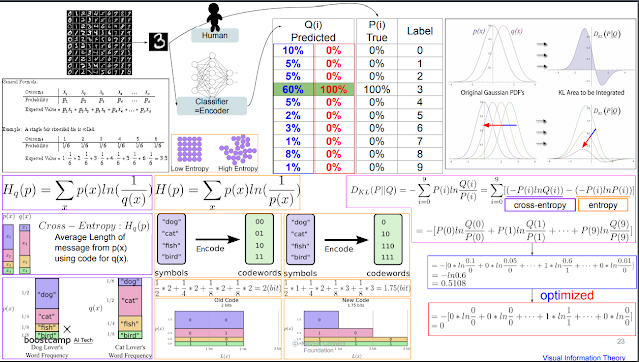
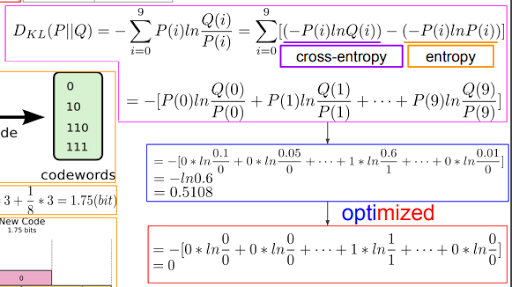
KL divergence. P와 Q와의 거리라고 하기엔 위치가 바뀌면 바뀌니까 애매한데 얼마나 가까운지. 거리가 아니지만 거리처럼 생각하고 계산.
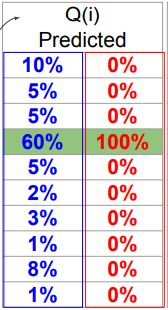
파란색끼리 무질서도 관계, 빨간색끼리 무질서도 관계. 무질서도가 0이라는 것은 확실하게 맞다 라는 확언. 無엔드로피. 이 두개 차이를 비교해보자 하는게 코딩하는 내용.
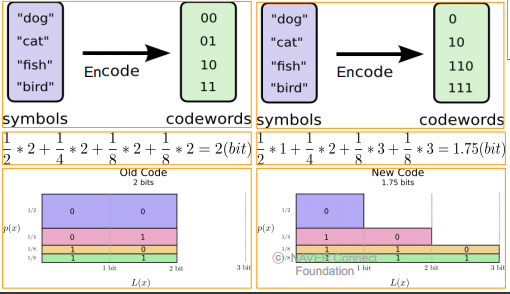
빈도수 많은건 작은수로, 빈도수 적은건 큰 수로 배치. 이렇게 해서 크기 줄이기. Huffman coding.
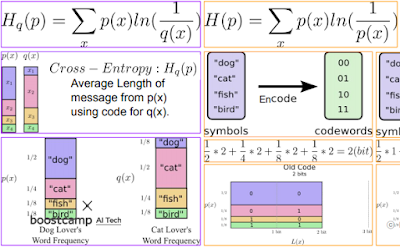
근데 P가 이상적이라고 한다. 그래서 이상적인 P코드북을 이용해 저장했을 때랑 압축하려고 만든 Q코드북을 이용해 압축했을 때의 차이를 메꾸기 위해 Cross - Entropy라는 개념을 도입했다고 한다. 왜 차이가 생기냐면 빈도수가 많으면 그만금 그 빈도수가 많은 것에 대해 가중치가 더 부여되는게 당연한건데 압축하면 이 빈도수 많은게 상대적으로 작아지니까.
Q는 모델이 내놓은 predict 값 분포. P는 원래 정답 분포.
DKL = Q라는 코드북을 가지고 P라는 메세지를 해독했을 때의 무질서도 - P라는 코드북을 가지고 P를 해석했을때의 무질서도. 그래서 두개의 딱 차이만큼만 남음.
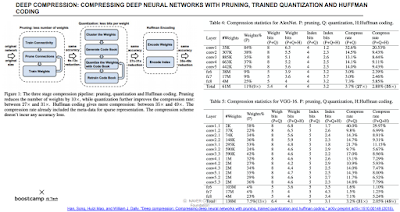
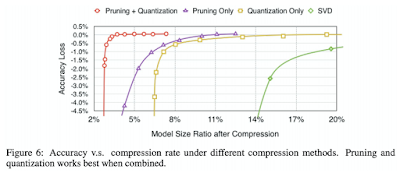
모델 압축. Pruning + Quantization이 제일 좋다. tflite가 이런 방법들을 모두 동원해서 엄청 작은 용량으로 바뀐다.
모델경량화 (좀 더 상세한 방법)
https://drive.google.com/file/d/16LHNU20PQ0ce1N_X-3xZrwRHqAOcvJ71/view?usp=sharing
=======================================
과제
https://colab.research.google.com/drive/1HItF2I_9o4mE7yzBoqWPPrqoCnPYZfye?usp=sharing
사람 성별 구분.
전체적인 코드 작성 방법 즉, 모델 구조 구성 방법, 훈련코드 작성 방법, 데이터 증식 방법 등 보기 좋게 작성되어서 두고두고 쓸만할듯.
=========================
피어세션
정보 엔트로피는 클수록 결과가 뭐가 나올지 모른다. 랜덤성.
https://www.youtube.com/watch?v=nxbufH4JnpA
https://wkdtjsgur100.github.io/P-NP/
P, NP 문제
https://karpathy.github.io/2019/04/25/recipe/
논문대로 안될때 디버깅 방법등..
===================
후기
관심생긴게 저번 시간에 했던 ㅇㅇ 이랑 여기서 MnasNet, PROXYLESSNAS, mobilenet 압축방식, model compression이다. 나중에 봐야지.
'과거의 것들 > AI Tech boostcamp' 카테고리의 다른 글
| AITech 학습정리-[Day 39] 양자화 / 지식 증류 (0) | 2021.11.27 |
|---|---|
| AITech 학습정리-[Day 38] 빠르게 / 가지치기 (0) | 2021.11.27 |
| AITech 학습정리-[Day 36] 가벼운 모델 / 팔리는 물건 / 가장 적당하게 (0) | 2021.11.27 |
| AITech 학습정리-[Day 35] Multimodal captioning and speaking, 3D understanding - 2 (0) | 2021.11.27 |
| AITech 학습정리-[Day 35] Multimodal captioning and speaking, 3D understanding - 1 (0) | 2021.11.27 |