==================================
학습내용
(6강) 빠르게
| https://leejaymin.github.io/papers/dc18.pdf |
밑으로 하드웨어쪽으로 내려가는걸 lowing. 근데 직접적으로 쫙 내려가는건 비효율 적이니 중간단계에 graph적으로 처리하는걸 만든다고 한다.

| https://towardsdatascience.com/how-fast-numpy-really-is-e9111df44347 |
파이썬에서 그냥 파이썬보다 numpy가 빠르다. 파이썬은 각 숫자도 object로 보지만 numpy는 비슷한 object는 하나의 object로 보기 때문이라고 한다. 그리고 병렬적으로 해결 가능하고, C로 되어있어서. 간단한 이유는 파이썬은 interpreter이기 때문.

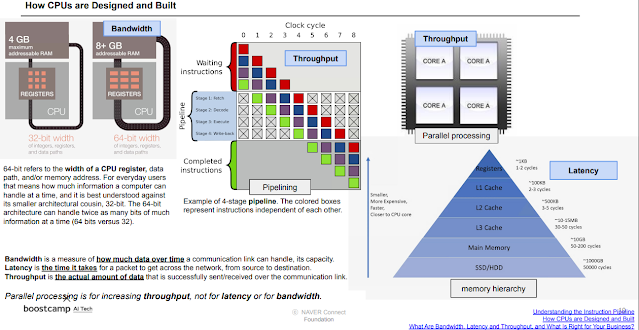
https://techdecoded.intel.io/resources/understanding-the-instruction-pipeline/#gs.qx06hk
https://www.techspot.com/article/1821-how-cpus-are-designed-and-built/
bandwith는 한번에 데이터가 갈 수 있는 양, latency는 가는데 걸리는 시간, throughput은 실제 데이터 양. 하나만 아무리 좋아도 다른게 안좋으면 병목현상이 생긴다.
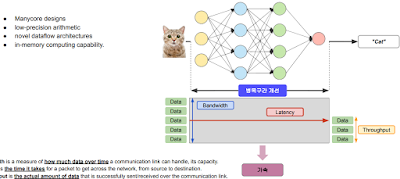
딥러닝 모델에서도 생각할 수 있다. 개선이 필요
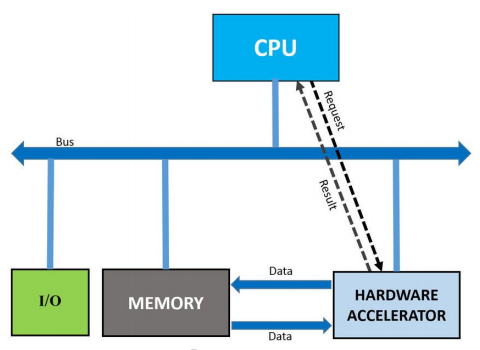
https://en.wikipedia.org/wiki/Hardware_acceleration
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8784190
| https://www10.mcadcafe.com/blogs/jeffrowe/2017/03/16/the-continuing-importance-of-gpus-for-more-than-just-pretty-pictures/ |
CPU는 단순 처리보단 좀 더 복잡한걸 처리하도록 만들어져서 병렬 처리가 잘 안됨. 그래서 GPU한테 맡긴다.

http://www.hellot.net/new_hellot/magazine/magazine_read.html?code=202&sub=002&idx=52620
https://dada.cs.washington.edu/research/tr/2017/12/UW-CSE-17-12-01.pdf
CPU, GPU 말고 다른것들 종류.
IPU라고 아얘 CPU랑 메모리랑 물리적으로 거리를 가까운 곳에 놓아서 속도 개선한 것도 있고, SoC(System on Chip) (apple m1 chip)처럼 작은 칩에 전부 박아넣은 것도 있다. FPGA는 CPU,GPU와 고정해서 사용하는 ASIC의 사이. 조립해서 사용한다. 아두이노 같은거라고 보면 된다고 함.

Compression은 software쪽으로, Acceleration은 hardware쪽으로 연관있다고 함.
| https://arxiv.org/pdf/2007.00864.pdf |
모델 압축할 때 그냥 tflite로 범용성있게 압축해서 하는 것 보단 실제 실행되는 hardware 환경 예를들어 CPU코어갯수라던가, GPU 병렬처리 가능 정도등을 고려해서 tflite로 압축하는 것이 더 좋을 수밖에 없다.
| https://arxiv.org/pdf/2002.03794.pdf |
| https://leejaymin.github.io/papers/dc18.pdf |
프레임워크가 많이도 있는데 기계어로 어떻게 번역을 하는가?
컴파일러 중에서도 C용, Fortran용, Haskell용 컴파일러가 다 따로 있어서 불편했는데 이걸 하나로 합쳐준 LLVM IR이란게 있다고 한다. 비슷하게 구글에서 MLIR를 만들고 있는 중이라고 한다.
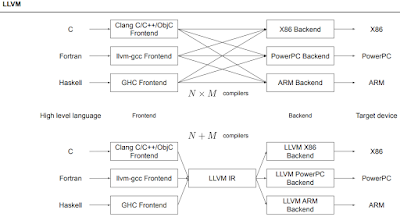
http://blog.naver.com/PostView.nhn?blogId=mesa_&logNo=221466719724&parentCategoryNo=&categoryNo=10&viewDate=&isShowPopularPosts=false&from=postView

https://llvm.org/
| https://arxiv.org/pdf/2002.03794.pdf |
| https://arxiv.org/pdf/2002.03794.pdf |
위 표에서 컴파일러에 따른 다른 장단점들이다. 어디엔 되고 안된다던지.. 그래서 회사에서나 자신의 요구사항에 맞는 것들을 고려해서 알맞는 컴파일러를 선택하자.
| https://arxiv.org/pdf/2002.03794.pdf |
DL 컴파일러가 최적화하는 방법들. OS시간에 배운 page fault 대비용 같은 것들도 보인다. 신기한건 벙렬처리용으로 바꿔주는 것도 있다는거.
| https://openaccess.thecvf.com/content_CVPR_2019/papers/Wang_HAQ_Hardware-Aware_Automated_Quantization_With_Mixed_Precision_CVPR_2019_paper.pdf |
| https://arxiv.org/pdf/2007.00864.pdf |
하드웨어까지 고려해서 압축하면 더 빨라진다. 위에서 했던 얘기.
실습
https://drive.google.com/file/d/1C1xEQi1kv7nZ2b4ZQkfUp3Tg7q7ab_8Z/view?usp=sharing
파이썬에서 병렬로 계산했을때의 속도차이
(7강) 가지치기

mask 언제 쓰는게 유용한가?

https://arxiv.org/pdf/1705.08922.pdf
필요없거나 덜 중요한 가지들을 잘라낸다. 실제 뇌도 그런다.
| https://papers.nips.cc/paper/2015/file/ae0eb3eed39d2bcef4622b2499a05fe6-Paper.pdf |
불필요한 가지를 잘라냈을 때 weight의 분포도 모습. weight 갯수가 1/10로 줄었다.
dropout 과 비슷하다고 볼 수 있는데, 가지치기인 pruning은 neuron을 아얘 없애는거고 dropout은 generator train을 위해서 잠깐 비활성화 하는거라 테스트할땐 전부 살려서 테스트한다는 차이점이 있음.
이 가치지기는 보통 한번으로 끝나지 않고 iter를 반복(fine tuning 을 반복)하며 만족할 때 까지 한다.
| https://arxiv.org/pdf/2003.03033.pdf |
| https://arxiv.org/pdf/1506.02626.pdf |
pruning을 이론적으로 표현한 것. theta가 weight들이라고 한다. weight의 변화에도 loss가 별로 미동이 없을때 즉 weight들이 이미 다 변할대로 변해서 수렴할 때 가지치기를 할수록 weight들이 점점 (0,0)으로 변한다는 내용같다.
| https://arxiv.org/pdf/2003.03033.pdf |
그래서 가지치기를 하면 weight수가 줄고 정확도도 조금씩 줄게 되어있다. 이를 나타낸 그래프.
EfficientNet에 대한 pruned model은? (further question)

https://arxiv.org/pdf/2003.03033.pdf
https://towardsdatascience.com/the-lottery-ticket-hypothesis-a-survey-d1f0f62f8884
pruning에도 여러 방법론들이 제기되고 있다. 그냥 마구잡이로 없애보는게 unstructured고 나름 규칙을 정해서 하는게 structured.
| https://www.xilinx.com/html_docs/vitis_ai/1_2/pruning.html |
이게 pruning의 기본 형태. 한번에 너무 많은걸 잘라내면 돌아올 수 없다. 적당히만 쳐내고 다시 학습시키고 적당히 쳐내고 다시 학습시키고..

https://arxiv.org/pdf/1611.06440.pdf
http://proceedings.mlr.press/v119/tan20a/tan20a.pdf
두 논문 다 같은 얘기를 하지만 표현법만 다르게 하는 거임. 다른점은 오른쪽의 strategy 1,2가 4,5 순서가 바뀌어 있는데 훈련을 하고 가지치기를 했을때 훈련되고 남은 weight를 그대로 가지고 훈련할꺼냐 아니면 초기화시키고 훈련할거냐의 차이. 남은 weight를 가지고 lottery Ticket Hypothesis(가설) 이 나오게 된다.

https://arxiv.org/pdf/1803.03635.pdf
학습시키고 자른다. 근데 자른 구조에서 weight를 초기화시키고 다시 학습하는 것보다 아까 학습하고 나온 weight를 넣고 학습하는게 잘 나오더라. 왜그런진 몰라서 가설임.

Iterative Magnitude Pruning은 가지치기한 구조에서 weight를 초기화하고 학습, with Rewinding은 학습했을 때 중간에 있던 weight를 넣어서 학습.

실습
https://drive.google.com/file/d/1jnFth_9Wm2CA3nWcvV1hb778Ox3o3ULM/view?usp=sharing
mask 씌우는 방식으로 pruning하기
===========================
피어세션
SK 직무마다 문제가 다른것 같음. 데이터 엔지니어링은 파이썬으로 데이터 분류하는거 나왔다고 함. DBMS는 오라클, mysql로 본듯.
롯데정보통신 1,2차 하루만에 다봄.
https://clovaai.github.io/AdamP/
adamp
=========================
후기
pruning도 관심이 조금 생김.
'과거의 것들 > AI Tech boostcamp' 카테고리의 다른 글
| AITech 학습정리-[Day 40] 행렬 분해 / 돌아보기 (0) | 2021.11.27 |
|---|---|
| AITech 학습정리-[Day 39] 양자화 / 지식 증류 (0) | 2021.11.27 |
| AITech 학습정리-[Day 37] 모델의 시공간 / 알뜰히 (0) | 2021.11.27 |
| AITech 학습정리-[Day 36] 가벼운 모델 / 팔리는 물건 / 가장 적당하게 (0) | 2021.11.27 |
| AITech 학습정리-[Day 35] Multimodal captioning and speaking, 3D understanding - 2 (0) | 2021.11.27 |