https://dacon.io/competitions/official/235746/overview/description
카메라 이미지 품질 향상 AI 경진대회 - DACON
dacon.io
이 대회 베이스라인 코드들을 분석했지만 정작 다른것들 하느라 시간이 없어 분석만 하고 못써먹었다.
그래서 가만히 두면 잊어버릴것 같고 그러기엔 유용해서 적어둠.
중구난방으로 쓸 거라 나중에 다른 글로 분리해야 할 수도 있다.
1. albumentations 라이브러리로 label image도 augment
https://dacon.io/competitions/official/235746/codeshare/2909?page=2&dtype=recent
from torch.utils.data import Dataset
from PIL import Image
import cv2
class CustomTensorDataset(Dataset):
"""TensorDataset with support of transforms.
"""
def __init__(self, imagex, imagey=None, transform=None, mode="test"):
self.mode = mode
if mode == "train" or mode == "val":
self.imagex = imagex
self.imagey = imagey
self.transform = transform
elif mode == "test":
self.imagex = imagex
self.transform = transform
def __getitem__(self, index):
if self.mode == "train" or self.mode == "val":
x = np.array(Image.open(self.imagex[index]))
y = np.array(Image.open(self.imagey[index]))
transformed = self.transform(image=x, target_image=y)
return transformed['image'].type(torch.FloatTensor)/255, transformed['target_image'].type(torch.FloatTensor)/255
elif self.mode == "test":
x = np.array(Image.open(self.imagex[index]))
transformed = self.transform(image=x)
return transformed['image'].type(torch.FloatTensor)/255
def __len__(self):
return len(self.imagex)import albumentations.pytorch
train_transforms = A.Compose([
A.Rotate(limit=(-30,30), p=1.0),
A.HorizontalFlip(),
A.VerticalFlip(),
# A.Normalize(mean=(0.548, 0.504, 0.479), std=(0.237, 0.247, 0.246)),
A.pytorch.ToTensorV2(),
],
additional_targets={'target_image':'image'})
val_transforms = A.Compose([A.pytorch.ToTensorV2(),
],
additional_targets={'target_image':'image'})
2. 미리 이미지를 잘라 저장함으로써 cutout augmentation 시간 단축
https://dacon.io/competitions/official/235746/codeshare/2913?page=2&dtype=recent
import concurrent.futures
import functools
IMG_SIZE = img_size
STRIDE = 128
SAVE_TRAIN_PATH = './data/train_input_img_'
SAVE_LABEL_PATH = './data/train_label_img_'def cut_img(save_path, img_path):
os.makedirs(f'{save_path}{IMG_SIZE}', exist_ok=True)
img = cv2.imread(img_path)
img_name = os.path.basename(img_path)
num = 0
for top in range(0, img.shape[0], STRIDE):
for left in range(0, img.shape[1], STRIDE):
piece = np.zeros([IMG_SIZE, IMG_SIZE, 3], np.uint8)
temp = img[top:top+IMG_SIZE, left:left+IMG_SIZE, :]
piece[:temp.shape[0], :temp.shape[1], :] = temp
cv2.imwrite(f'{save_path}{IMG_SIZE}/{num}_{img_name}', piece)
# np.save(f'{save_path}{img_size}/{num}.npy', piece)
num+=1
returnwith concurrent.futures.ProcessPoolExecutor() as executor: # windows local 환경시 max_workers=os.cpu_count()//2
list(tqdm(
executor.map(functools.partial(cut_img, "./data/train_input_img_"), train_input_files),
desc='train_input_files cut',
total=len(train_input_files)
))
list(tqdm(
executor.map(functools.partial(cut_img, './data/train_label_img_'), train_label_files),
desc='train_label_files cut',
total=len(train_label_files)
))
list(tqdm(
executor.map(functools.partial(cut_img, './data/val_input_img_'), val_input_files),
desc='val_input_files cut',
total=len(val_input_files)
))
list(tqdm(
executor.map(functools.partial(cut_img, './data/val_label_img_'), val_label_files),
desc='val_label_files cut',
total=len(val_label_files)
))
3. Unet
이 대회 베이스라인 코드는 resnetv2 101에 tensorflow를 사용하고 있어서 Unet 논문이랑 외부 코드 보고 pytorch로 변환해봤다. 스스로 논문보고 구현한 첫 시도가 아닐까 생각한다.
근데 결과가 이상하게 나와서 과연 여기다 적어도 될지는 모르겠다..
baseline code
https://dacon.io/competitions/official/235746/codeshare/2874?page=2&dtype=recent
def convolution_block(x, filters, size, strides=(1,1), padding='same', activation=True):
x = tf.keras.layers.Conv2D(filters, size, strides=strides, padding=padding)(x)
x = tf.keras.layers.BatchNormalization()(x)
if activation == True:
x = tf.keras.layers.LeakyReLU(alpha=0.1)(x)
return x
def residual_block(blockInput, num_filters=16):
x = tf.keras.layers.LeakyReLU(alpha=0.1)(blockInput)
x = tf.keras.layers.BatchNormalization()(x)
blockInput = tf.keras.layers.BatchNormalization()(blockInput)
x = convolution_block(x, num_filters, (3,3) )
x = convolution_block(x, num_filters, (3,3), activation=False)
x = tf.keras.layers.Add()([x, blockInput])
return xdef ResUNet101V2(input_shape=(None, None, 3), dropout_rate=0.1, start_neurons = 16):
backbone = tf.keras.applications.ResNet101V2(weights=weights, include_top=False, input_shape=input_shape)
input_layer = backbone.input
conv4 = backbone.layers[122].output
conv4 = tf.keras.layers.LeakyReLU(alpha=0.1)(conv4)
pool4 = tf.keras.layers.MaxPooling2D((2, 2))(conv4)
pool4 = tf.keras.layers.Dropout(dropout_rate)(pool4)
convm = tf.keras.layers.Conv2D(start_neurons * 32, (3, 3), activation=None, padding="same")(pool4)
convm = residual_block(convm,start_neurons * 32)
convm = residual_block(convm,start_neurons * 32)
convm = tf.keras.layers.LeakyReLU(alpha=0.1)(convm)
deconv4 = tf.keras.layers.Conv2DTranspose(start_neurons * 16, (3, 3), strides=(2, 2), padding="same")(convm)
uconv4 = tf.keras.layers.concatenate([deconv4, conv4])
uconv4 = tf.keras.layers.Dropout(dropout_rate)(uconv4)
uconv4 = tf.keras.layers.Conv2D(start_neurons * 16, (3, 3), activation=None, padding="same")(uconv4)
uconv4 = residual_block(uconv4,start_neurons * 16)
uconv4 = residual_block(uconv4,start_neurons * 16)
uconv4 = tf.keras.layers.LeakyReLU(alpha=0.1)(uconv4)
deconv3 = tf.keras.layers.Conv2DTranspose(start_neurons * 8, (3, 3), strides=(2, 2), padding="same")(uconv4)
conv3 = backbone.layers[76].output
uconv3 = tf.keras.layers.concatenate([deconv3, conv3])
uconv3 = tf.keras.layers.Dropout(dropout_rate)(uconv3)
uconv3 = tf.keras.layers.Conv2D(start_neurons * 8, (3, 3), activation=None, padding="same")(uconv3)
uconv3 = residual_block(uconv3,start_neurons * 8)
uconv3 = residual_block(uconv3,start_neurons * 8)
uconv3 = tf.keras.layers.LeakyReLU(alpha=0.1)(uconv3)
deconv2 = tf.keras.layers.Conv2DTranspose(start_neurons * 4, (3, 3), strides=(2, 2), padding="same")(uconv3)
conv2 = backbone.layers[30].output
uconv2 = tf.keras.layers.concatenate([deconv2, conv2])
uconv2 = tf.keras.layers.Dropout(0.1)(uconv2)
uconv2 = tf.keras.layers.Conv2D(start_neurons * 4, (3, 3), activation=None, padding="same")(uconv2)
uconv2 = residual_block(uconv2,start_neurons * 4)
uconv2 = residual_block(uconv2,start_neurons * 4)
uconv2 = tf.keras.layers.LeakyReLU(alpha=0.1)(uconv2)
deconv1 = tf.keras.layers.Conv2DTranspose(start_neurons * 2, (3, 3), strides=(2, 2), padding="same")(uconv2)
conv1 = backbone.layers[2].output
uconv1 = tf.keras.layers.concatenate([deconv1, conv1])
uconv1 = tf.keras.layers.Dropout(0.1)(uconv1)
uconv1 = tf.keras.layers.Conv2D(start_neurons * 2, (3, 3), activation=None, padding="same")(uconv1)
uconv1 = residual_block(uconv1,start_neurons * 2)
uconv1 = residual_block(uconv1,start_neurons * 2)
uconv1 = tf.keras.layers.LeakyReLU(alpha=0.1)(uconv1)
uconv0 = tf.keras.layers.Conv2DTranspose(start_neurons * 1, (3, 3), strides=(2, 2), padding="same")(uconv1)
uconv0 = tf.keras.layers.Dropout(0.1)(uconv0)
uconv0 = tf.keras.layers.Conv2D(start_neurons * 1, (3, 3), activation=None, padding="same")(uconv0)
uconv0 = residual_block(uconv0,start_neurons * 1)
uconv0 = residual_block(uconv0,start_neurons * 1)
uconv0 = tf.keras.layers.LeakyReLU(alpha=0.1)(uconv0)
uconv0 = tf.keras.layers.Dropout(dropout_rate/2)(uconv0)
output_layer = tf.keras.layers.Conv2D(3, (1,1), padding="same", activation="sigmoid")(uconv0)
model = tf.keras.models.Model(input_layer, output_layer)
return modeloptimizer = tf.keras.optimizers.Adam(learning_rate)
model = ResUNet101V2(input_shape=(img_size, img_size, 3),dropout_rate=dropout_rate)
model.compile(loss='mae', optimizer=optimizer)
내가 pytorch로 변환한거
import torch.nn as nn
import torchvision.models
class Convolution_block(nn.Module):
def __init__(self, in_channels, out_channels, activation=True):
super().__init__()
if activation:
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=(3,3), padding=(1,1)),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(),
)
else: self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=(3,3), padding=(1,1)),
nn.BatchNorm2d(out_channels),
)
def forward(self, x):
return self.conv(x)
class Residual_block(nn.Module):
def __init__(self, out_channels):
super().__init__()
self.relu = nn.LeakyReLU()
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
self.cb1 = Convolution_block(out_channels,out_channels)
self.cb2 = Convolution_block(out_channels,out_channels, False)
def forward(self, blockinput):
x = self.relu(blockinput)
x = self.bn1(x)
blockinput = self.bn2(blockinput)
x = self.cb1(x)
x = self.cb2(x)
x = torch.add(x, blockinput)
return x
# https://github.com/zhoudaxia233/PyTorch-Unet/blob/master/resnet_unet.py
class DUnetResnet101(nn.Module):
def __init__(self):
super().__init__()
tchres101 = torchvision.models.resnet101(pretrained=True)
encoder_layer = list(tchres101.children())
self.encoder_block1 = nn.Sequential(*encoder_layer[:3])
self.encoder_block2 = nn.Sequential(*encoder_layer[3:5])
self.encoder_block3 = encoder_layer[5]
self.encoder_block4 = encoder_layer[6]
self.encoder_block5 = encoder_layer[7]
self.convm = nn.Conv2d(2048, 1024, kernel_size=(3,3), padding=(1,1))
self.residualm_1 = Residual_block(1024)
self.residualm_2 = Residual_block(1024)
self.relum = nn.LeakyReLU()
self.upconv6 = nn.ConvTranspose2d(1024, 512, kernel_size=(3,3), stride=(2,2), padding=(1,1), output_padding=(1,1))
self.dropout6 = nn.Dropout2d(0.1)
self.conv6 = nn.Conv2d(1024 + 512, 512, kernel_size=(3,3), padding=(1,1))
self.residual6_1 = Residual_block(512)
self.residual6_2 = Residual_block(512)
self.relu6 = nn.LeakyReLU()
self.upconv7 = nn.ConvTranspose2d(512,256, kernel_size=(3,3), stride=(2,2), padding=(1,1), output_padding=(1,1))
self.dropout7 = nn.Dropout2d(0.1)
self.conv7 = nn.Conv2d(512+256,256, kernel_size=(3,3), padding=(1,1))
self.residual7_1 = Residual_block(256)
self.residual7_2 = Residual_block(256)
self.relu7 = nn.LeakyReLU()
self.upconv8 = nn.ConvTranspose2d(256,128, kernel_size=(3,3), stride=(2,2), padding=(1,1), output_padding=(1,1))
self.dropout8 = nn.Dropout2d(0.1)
self.conv8 = nn.Conv2d(256+128,128, kernel_size=(3,3), padding=(1,1))
self.residual8_1 = Residual_block(128)
self.residual8_2 = Residual_block(128)
self.relu8 = nn.LeakyReLU()
self.upconv9 = nn.ConvTranspose2d(128,64, kernel_size=(3,3), stride=(2,2), padding=(1,1), output_padding=(1,1))
self.dropout9 = nn.Dropout2d(0.1)
self.conv9 = nn.Conv2d(64+64,64, kernel_size=(3,3), padding=(1,1))
self.residual9_1 = Residual_block(64)
self.residual9_2 = Residual_block(64)
self.relu9 = nn.LeakyReLU()
self.upconv10 = nn.ConvTranspose2d(64,32, kernel_size=(3,3), stride=(2,2), padding=(1,1), output_padding=(1,1))
self.dropout10 = nn.Dropout2d(0.1)
self.conv10 = nn.Conv2d(32,32, kernel_size=(3,3), padding=(1,1))
self.residual10_1 = Residual_block(32)
self.residual10_2 = Residual_block(32)
self.relu10 = nn.LeakyReLU()
self.dropout11 = nn.Dropout2d(0.05)
self.conv11 = nn.Conv2d(32,3, kernel_size=(1,1))
def forward(self,x):
block1 = self.encoder_block1(x)
block2 = self.encoder_block2(block1)
block3 = self.encoder_block3(block2)
block4 = self.encoder_block4(block3)
block5 = self.encoder_block5(block4)
x = self.convm(block5)
x = self.residualm_1(x)
x = self.residualm_2(x)
x = self.relum(x)
x = self.upconv6(x)
x = torch.cat([x, block4], dim=1)
x = self.dropout6(x)
x = self.conv6(x)
x = self.residual6_1(x)
x = self.residual6_2(x)
x = self.relu6(x)
x = self.upconv7(x)
x = torch.cat([x, block3], dim=1)
x = self.dropout7(x)
x = self.conv7(x)
x = self.residual7_1(x)
x = self.residual7_2(x)
x = self.relu7(x)
x = self.upconv8(x)
x = torch.cat([x, block2], dim=1)
x = self.dropout8(x)
x = self.conv8(x)
x = self.residual8_1(x)
x = self.residual8_2(x)
x = self.relu8(x)
x = self.upconv9(x)
x = torch.cat([x, block1], dim=1)
x = self.dropout9(x)
x = self.conv9(x)
x = self.residual9_1(x)
x = self.residual9_2(x)
x = self.relu9(x)
x = self.upconv10(x)
x = self.dropout10(x)
x = self.conv10(x)
x = self.residual10_1(x)
x = self.residual10_2(x)
x = self.relu10(x)
x = self.dropout11(x)
x = self.conv11(x)
return xmodel = DUnetResnet101()
optimizer = torch.optim.AdamW(model.parameters(), lr=0.001)
scheduler = torch.optim.lr_scheduler.OneCycleLR(
optimizer=optimizer,
max_lr=0.1,
steps_per_epoch=len(train_loader),
epochs=200,
pct_start=0.05,
)
criterion = nn.MSELoss()
fp16 = False
scaler = (
torch.cuda.amp.GradScaler() if fp16 and device != torch.device("cpu") else None
)근데 결과가 이렇게 나온다. loss도 똑같이 mse로 한것 같은데 원인을 모르겠다. 아마 분석 되면 글 수정할듯.
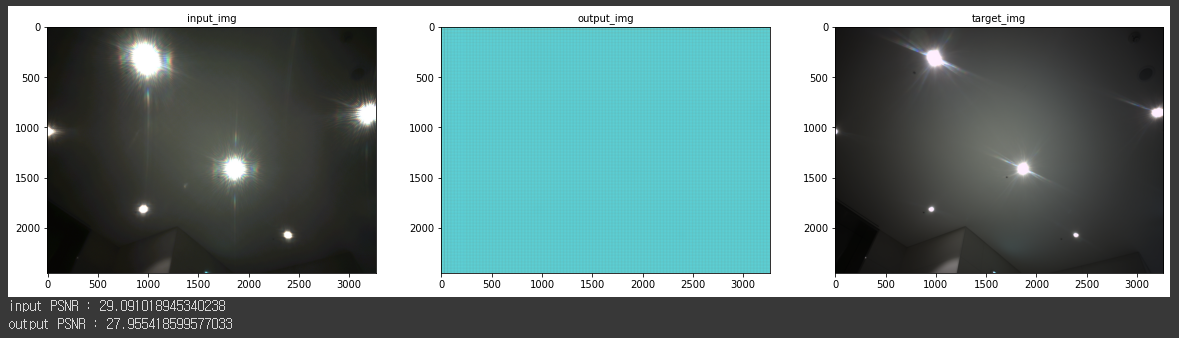
아님 다른 사람이 한거 보자. timm으로 모델 backbone만 불러와서 Unet으로 개조한 것 같다.
https://dacon.io/competitions/official/235746/codeshare/3006
모델공유
카메라 이미지 품질 향상 AI 경진대회
dacon.io
'기술 > Computer Vision' 카테고리의 다른 글
| self-supervised learning (0) | 2022.01.17 |
|---|---|
| conv1d, conv2d, conv3d (0) | 2021.11.01 |
| 랜덤 샘플 이미지 (0) | 2021.10.06 |
| image normalize, inverse normalize (0) | 2021.09.16 |
| tensor image to numpy image, numpy image to tensor image (0) | 2021.09.16 |