
https://fullstackdeeplearning.com/spring2021/lecture-6/
Full Stack Deep Learning
Hands-on program for software developers familiar with the basics of deep learning seeking to expand their skills.
fullstackdeeplearning.com
딥러닝 외의 그 주변 환경등을 다루고 있음. 어느 컴퓨터에서 돌릴거냐, 어떻게 돌릴거냐 등
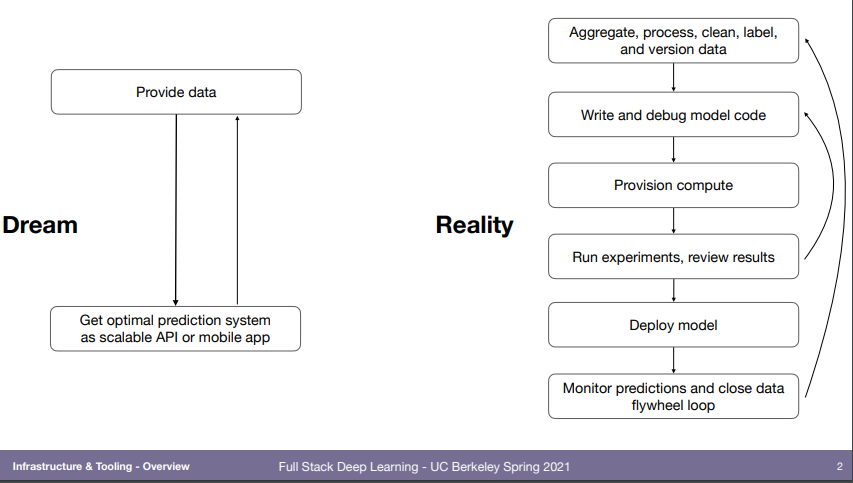
이상과는 다르다.. 반복함.

mlops 강의 찾아보면 맨날 보는 그림. 여기 논문에서 나왔다고 함.
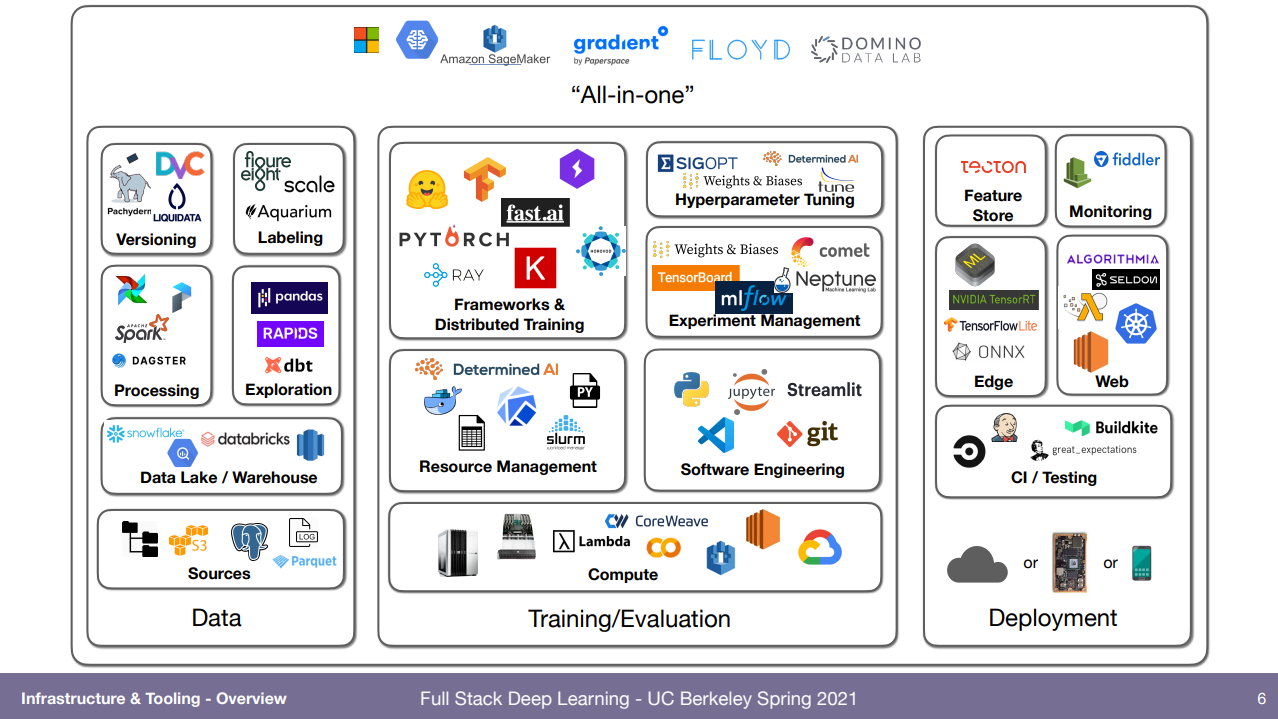
여기 그림처럼 아주 많은데, 이번 강의는 Training/Evaluation 부분과 All-in-one 부분을 볼거다.
에디터는.. 다 아니까 안적음.
다만 streamlit은 안써봤는데, 일반 파이썬 코드처럼 적으면서 notebook도 되는 그런거인듯.
가상환경 설정은 conda와 pip. pip의 경우 numpy를 예로 들자면 자기가 현재 사용하는 컴퓨터 운영체제 등도 고려해서 버전을 받아야 되는데 그런걸 알아서 찾아준다.. 이건 linux쓰다가 windows로 바꿀 때 직접 겪어보면 얼마나 짜증나는

무슨 컴퓨터를 쓸거냐의 문제인데, 내가 재밌었던 것만 적어봄.
모델이 점점 커지고 (GPT-3등) 그에 다라 VRAM이 큰, 좋은 GPU로 돌려야되는데 그럴수록 가격은 올라가고, 환경은 로컬, 서버, cloud등이 있는데 뭘 할거냐는 문제임.
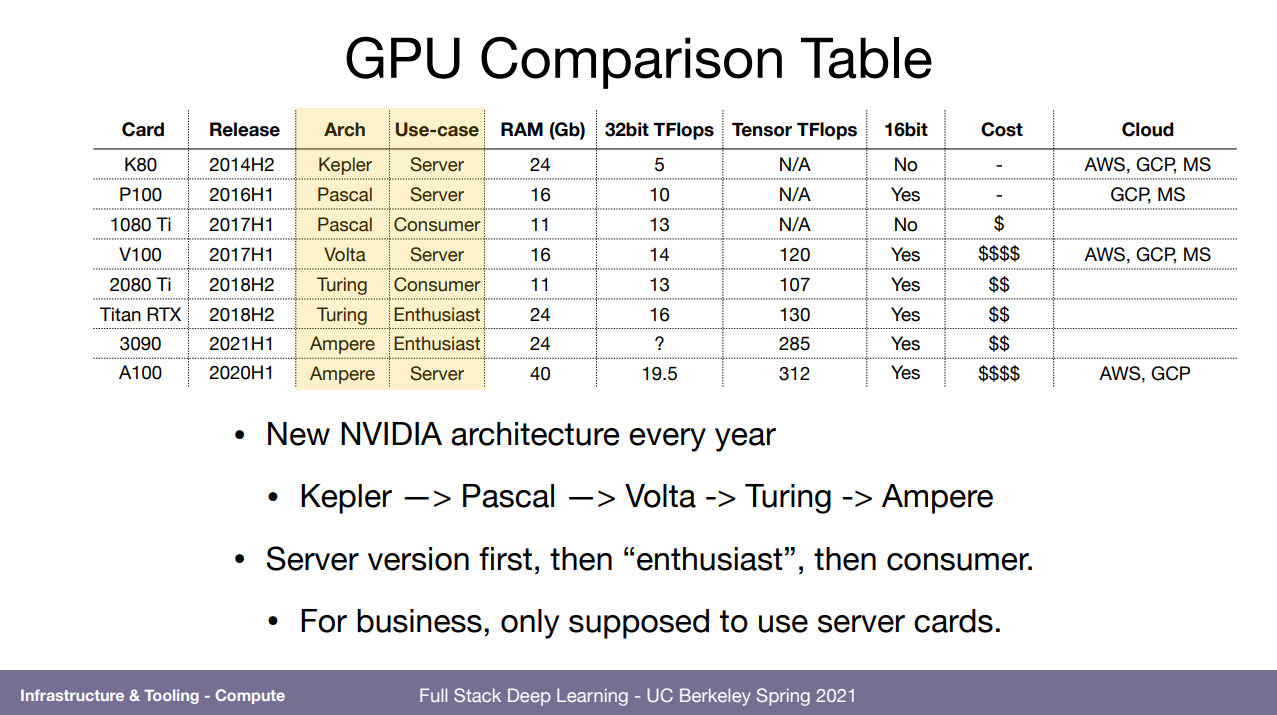
글카 순위 및 정보 표. 16bit는 이제 mixed-precision라고 32bit로 돌리는걸 16bit로 바꿔서 돌리는건데 그걸 더 빨리 할 수 있다.
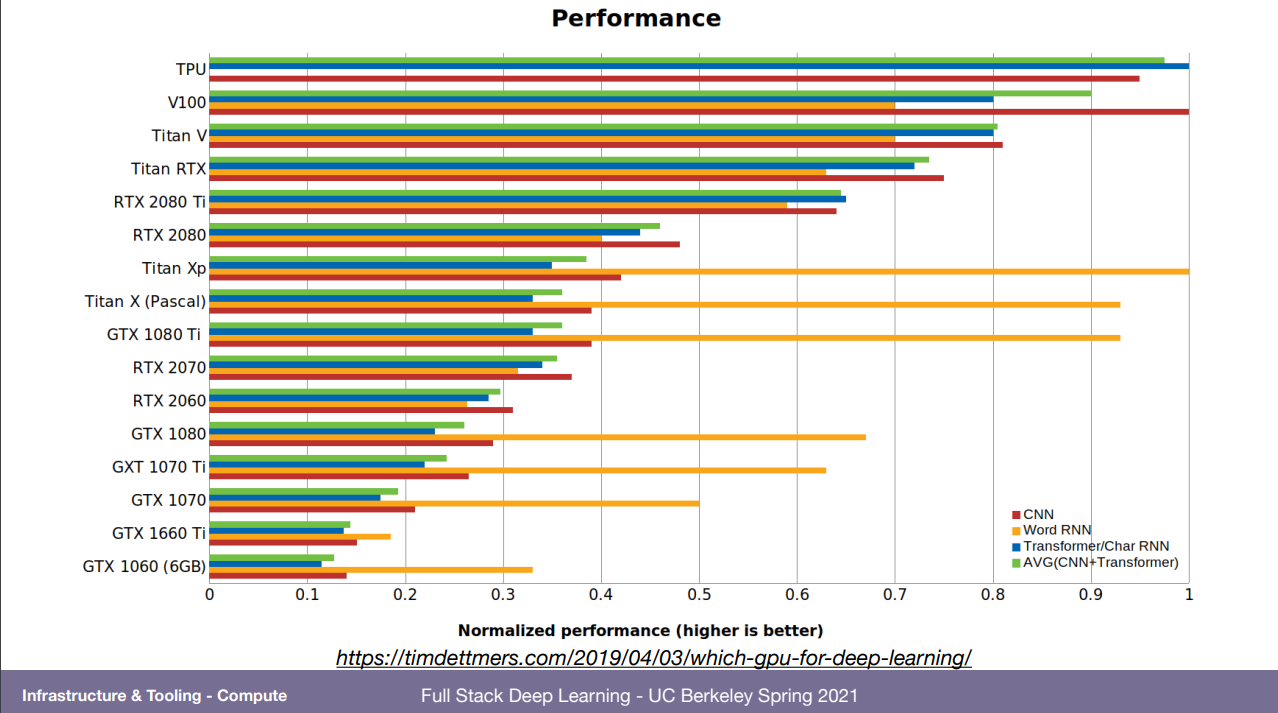

그 외에 재미있는 고려사항도 말해줌. 만약 rtx 30시리즈를 쓰겠다면 이게 전력과 열을 많이 잡아먹어서 개인으로는 2개가 최대일 거다. 반면 rtx 20은 4개까지 가능한데 그럼 뭘 돌릴거냐? 등.

cloud는 amazon aws, google cloud platform(GCP), Azure 외 여러 스타트업 기업들꺼가 있는데 amazon은 그냥 보통이고, GCP는 TPU때문에 쓰는건데 무지하게 빠르고, Azure는 싸긴한데 걍 별로..
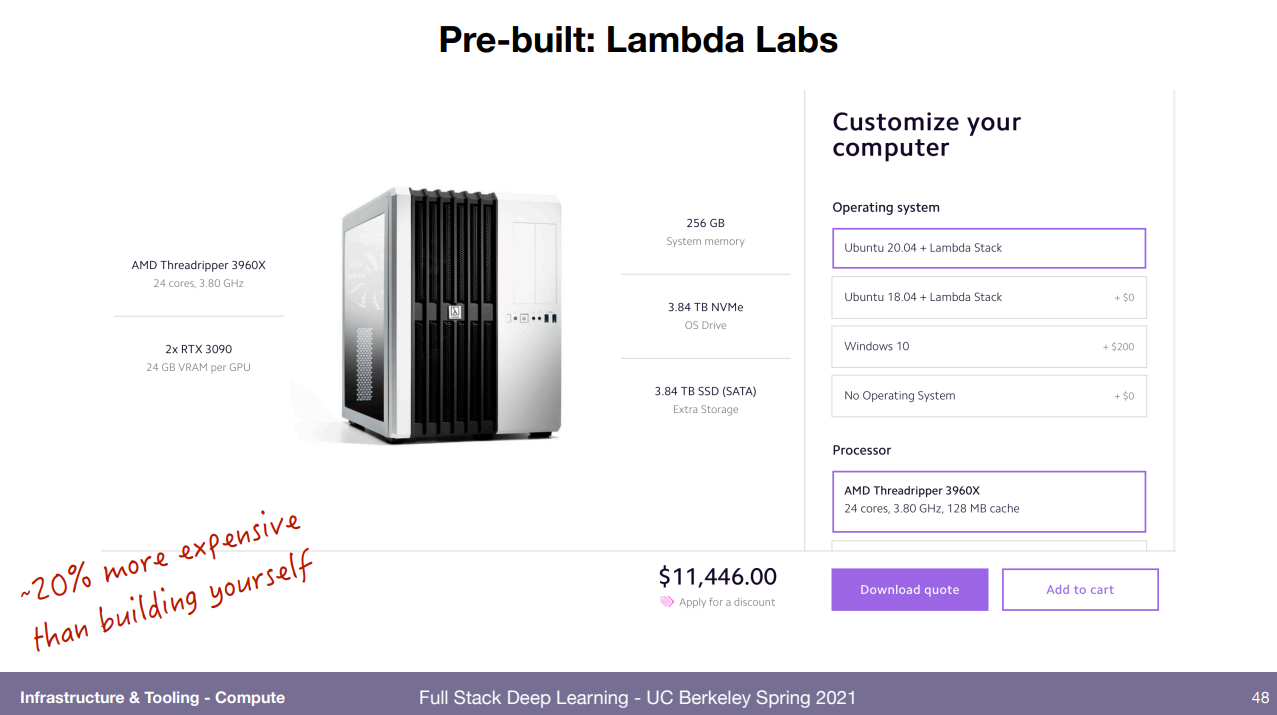
물론 직접 사서 로컬로 돌릴수도 있다! 하지만 천만원이나 하는데 그정도의 가치가 있을까?

클라우드를 돌리는 상황과 비교하면 어차피 클라우드는 1시간에 1.2만원 정도하니 그걸 24시간 5주동안 돌리면 어차피 천만원 나옴. 그럴바엔 로컬로 사는게 낫다는 결론. 그래서 고려대상임. 물론 채굴애들때매 구하기 어려운점도 고려해야 한다.
그래서 막 시작하는 기업이면 그냥 로컬로 사고, 대기업이라 돈이 넘쳐나거나 그냥 빨리 하고싶다하면 클라우드로 돌리고.. 그런 내용이다.

훈련은 훈련이고 어케 환경 관리 (통일 등)를 할거냐인데, 그냥 쌩으로 고려해서 작성하는거랑 SLURM라는 옛날 방식이 있고, 많이 들은 Docker과 쿠버네틱스가 있다.

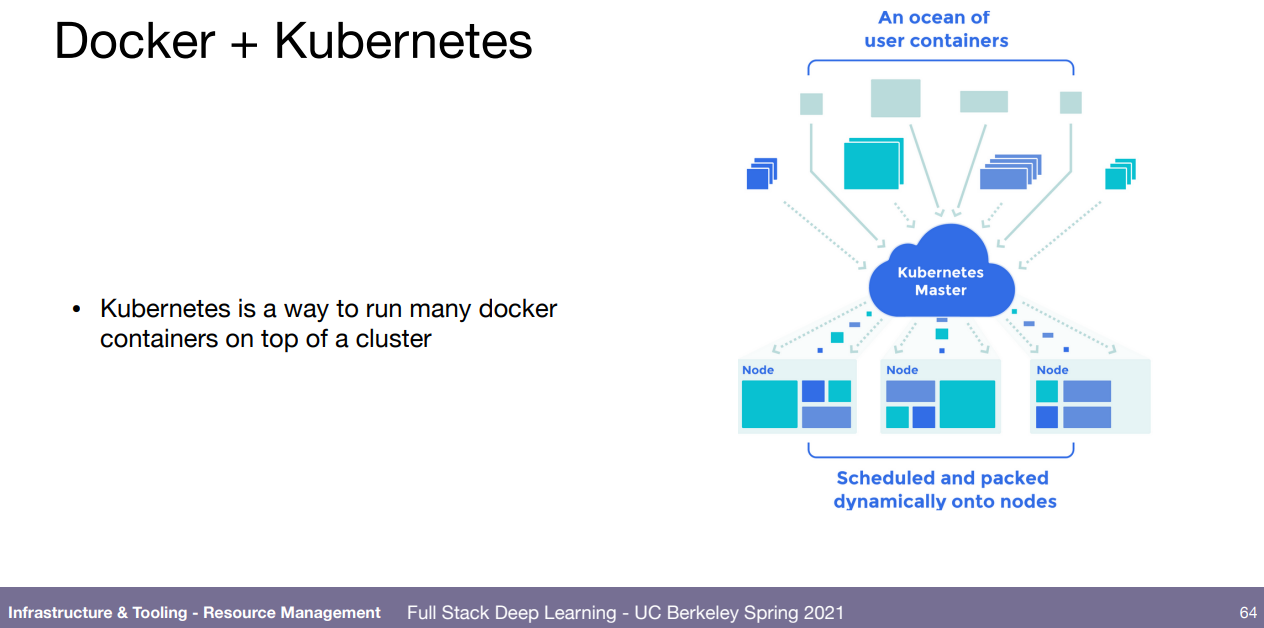
도커는 OS환경 빼고는 똑같이 관리하게 할 수 있아고 하고 쿠버네틱스는 그렇게 만든 도커 컨테이터들을 관리하는 거인듯.
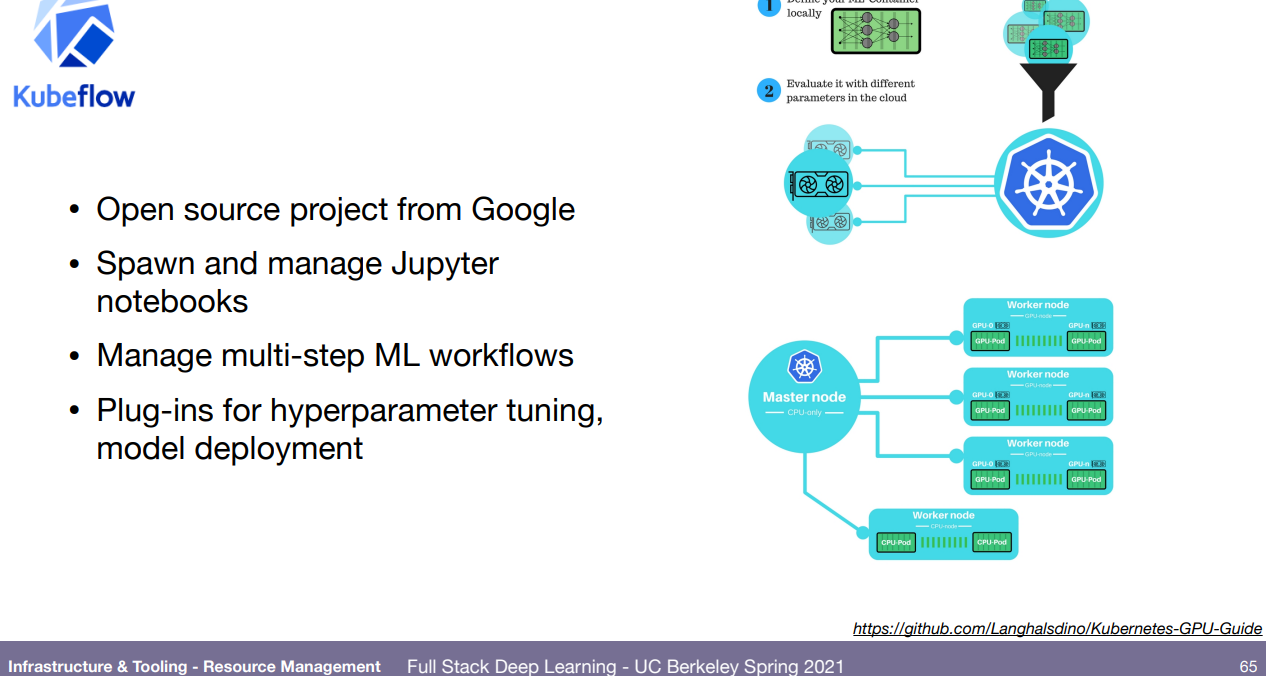
그 외에 kubeflow도 있고, 현재 진행중인(영상기준) Anyscale, Grid.ai 가 있다.

프레임워크들. fast.ai빼고 다 암.
그럼 프레임워크는 왜 쓰는가? 이론상으론 내가 직접 numpy를 이용해서 만들수도 있는데, backpropagation들도 직접 구현해서 만들어야 된다. 꼭 그럴 필요가 없다면 편하게 쓰자.

그 다음에 JAX를 좀 강조하던데 tensorflow나 pytorch에 있는 모든 레이어가 있는건 아니지만 auto-diff와 GPU/TPU를 편하게 다루는것을 목적으로, 실용성, 범용성에 목적을 두고 만들어짐. 그래서 꼭 딥러닝으로만 쓸려는게 아니다.
또 NLP 하시는 분은 huggingface도 잊지마세요.
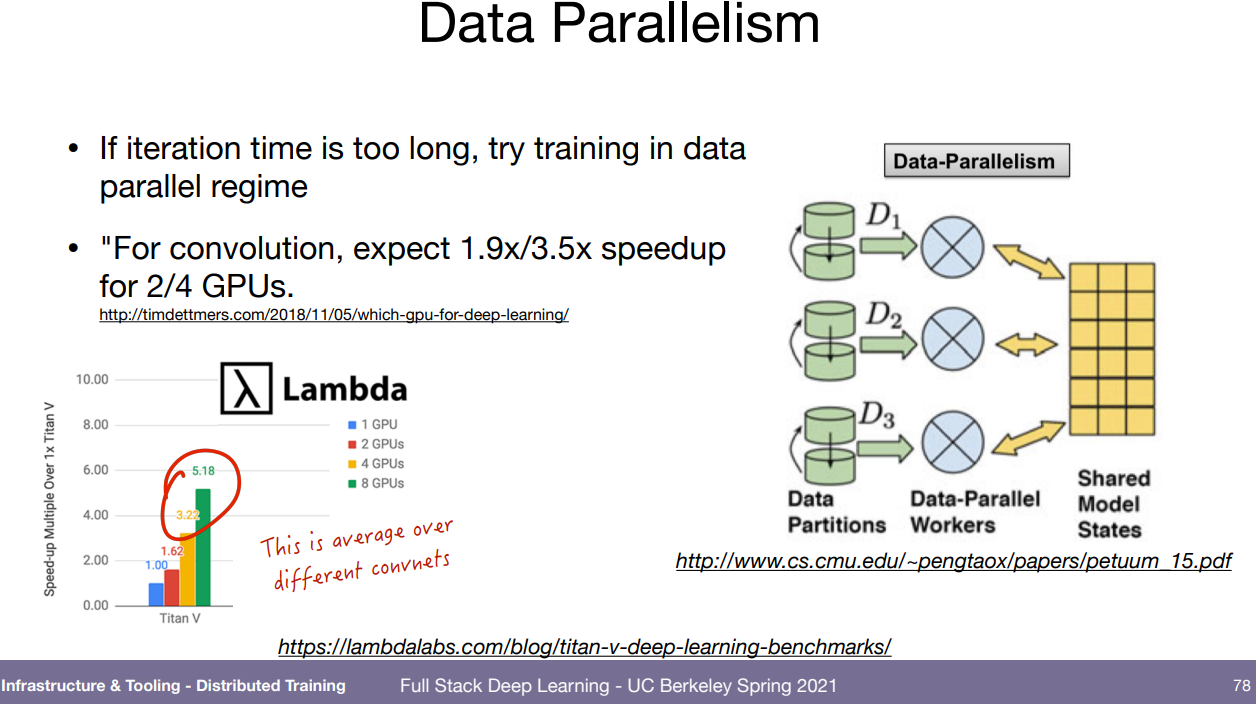
병렬처리. 데이터가 많아지고 모델도 커지면서 할줄 알아야 되도록 되었다. data-parallel이 어떻게 되냐면 각자의 GPU에서 연산을 하면 각 GPU에서의 미분값이 있을텐데 그것들을 평균해서 모델에 학습시키는거. 이건 gpu 병렬로 돌릴려고 검색하면 많이 나온다.

모델을 쪼개는 모델 병렬.. 의도는 모델이 하나의 GPU에 들어가기에 너무 크다면 나누는 거지만 너무 까다롭고 힘들기 때문에 걍 VRAM이 더 큰 GPU 하나 사던가 해서 피할 수 있으면 피하라고 추천함..


pytorch와 lightning은 매우매우 쉽게 할 수 있다, 즉 합칠때 평균값 어쩌구를 내부에서 알아서 해줌.
그 외에도 multi-node 훈련에 쉬운 Horovod와 딥러닝 말고도 별 노력 없이 병렬쓰게 하려는 목적인 Ray가 있다.
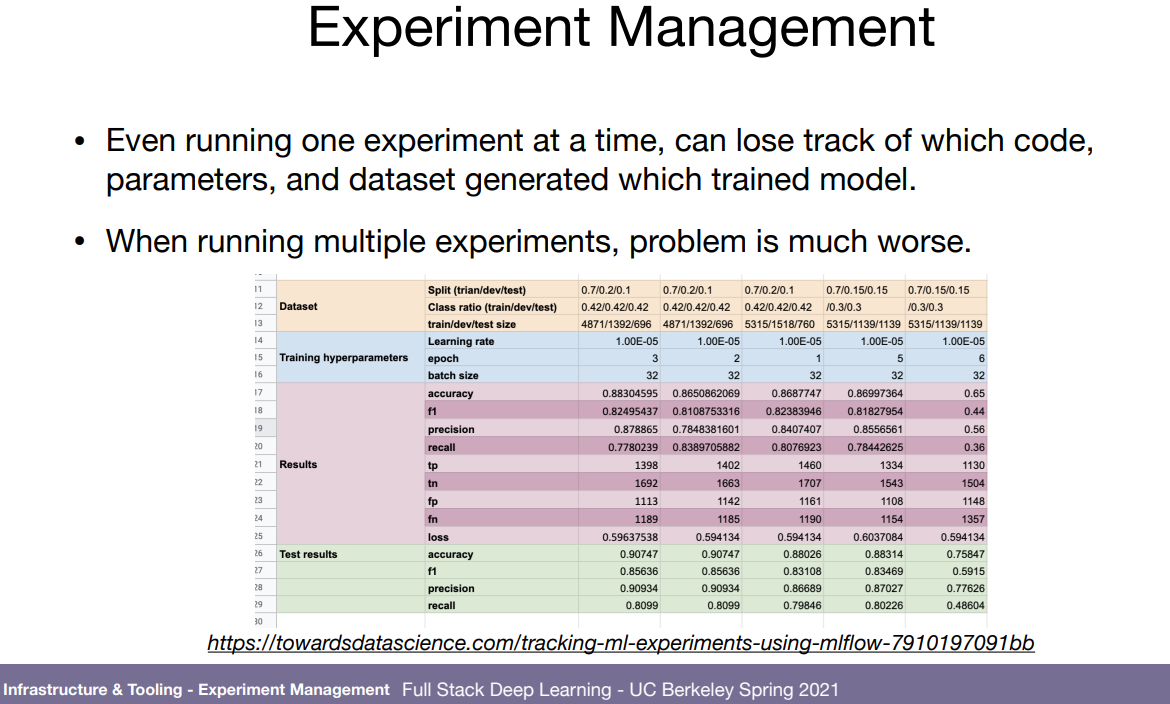
실험 관리는 어떻게 하냐. 저렇게 안적어놓으면 실제로 많이 까먹어서 난감할 때가 많다. tensorboard로 결과 하나하나 볼 수야 있겠지만.. mlflow, comet.ml, weights & biases(wandb) 등을 활용해서 모든 실험에 대해 전체적으로 볼 수 있도록 하자.
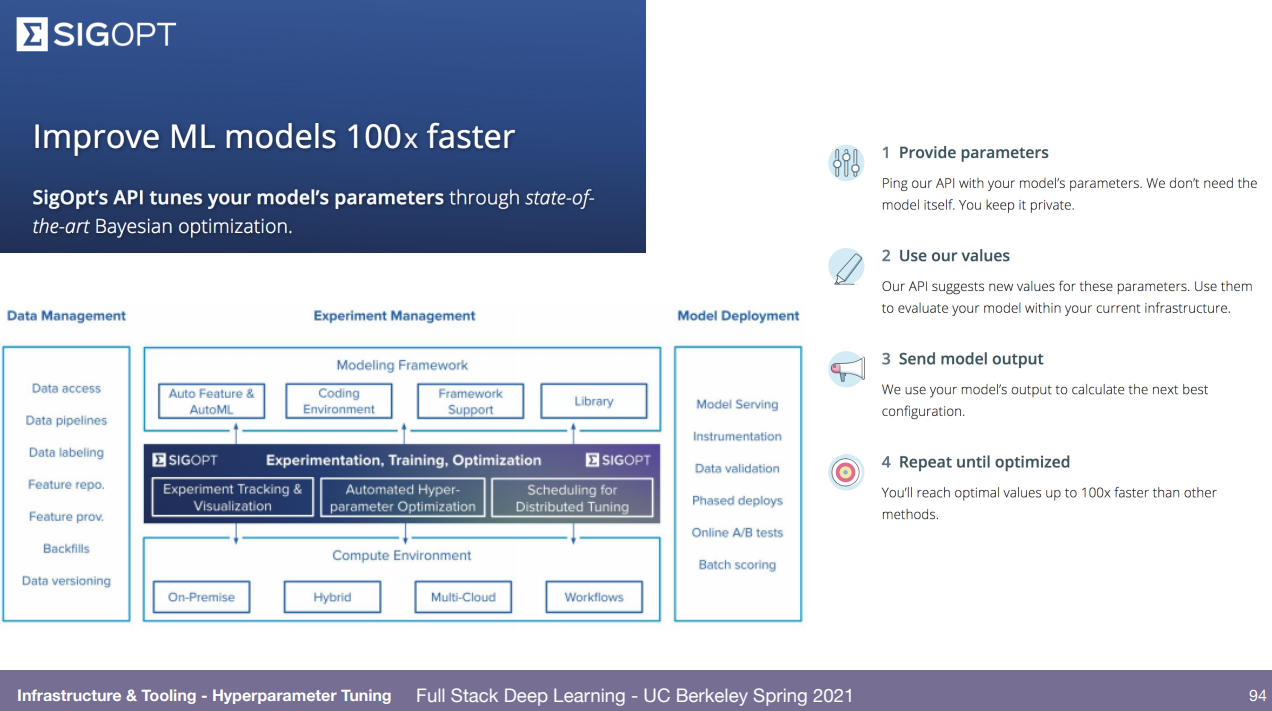
하이퍼파라미터 최적화는 걍 아무거나 쓰나? sigopt, ray tune, wandb 알려줌. 내가 찾고자 하는 파라미터 알려주면 bayesian optimization (알아서 최적 찾는 알고리즘) 등으로 실험해보고 추천 값 알려주는 거. wandb는 sweep.
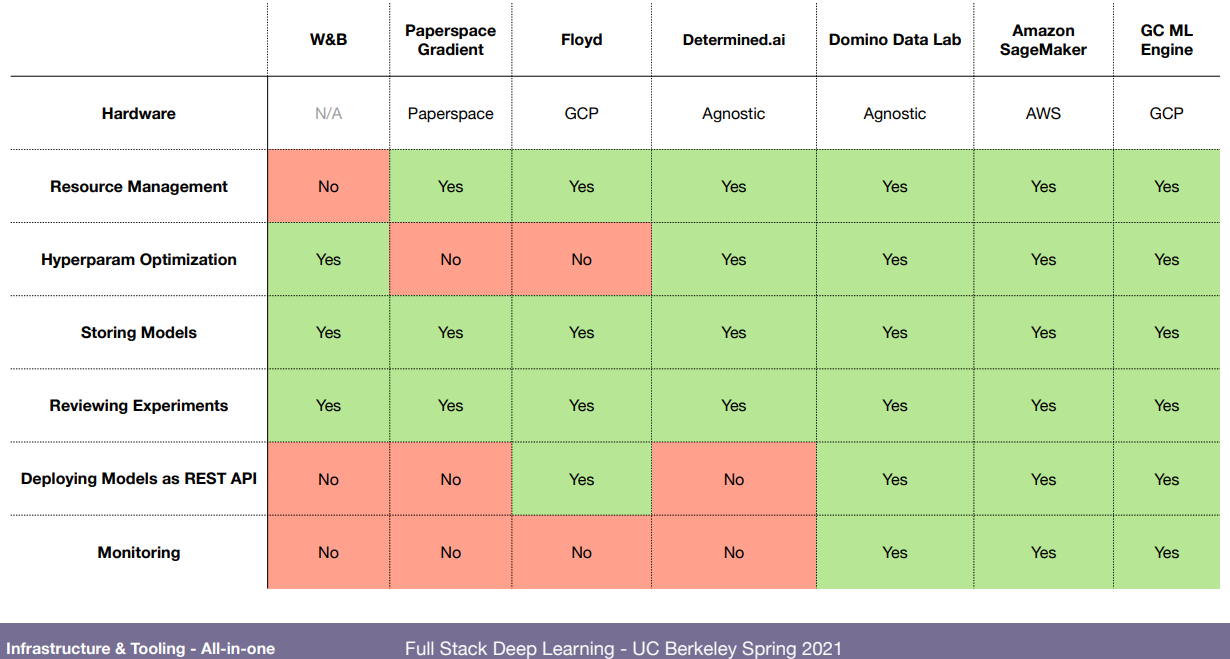
이 모든 데이터 입수부터 실제 배포까지 한번에 하려는건 많음. 강의 ppt에 그림 많아서 다 붙여놓고 끝내겠음.


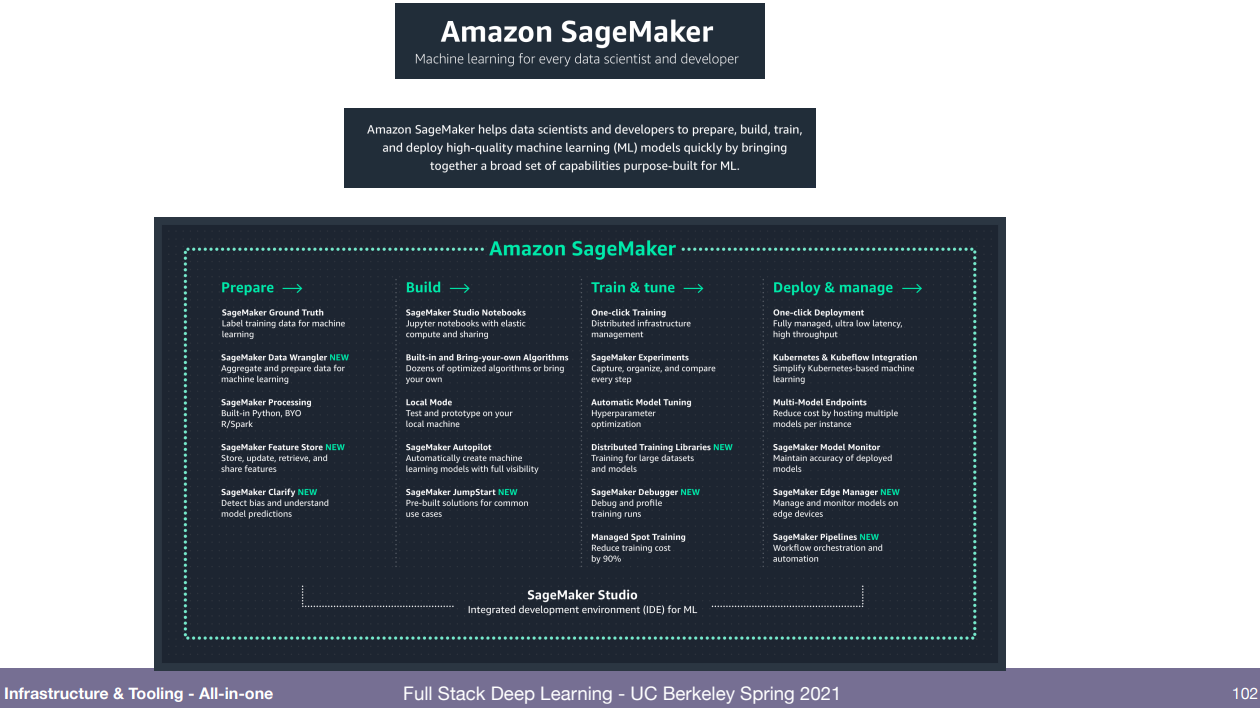



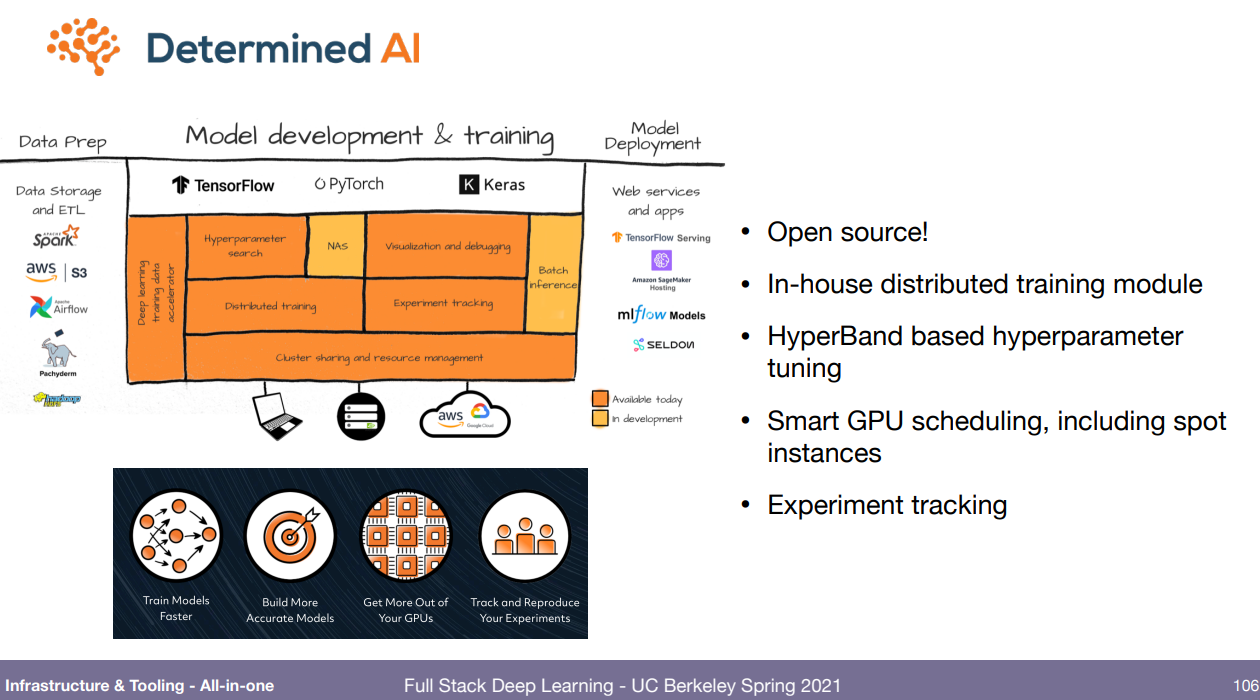


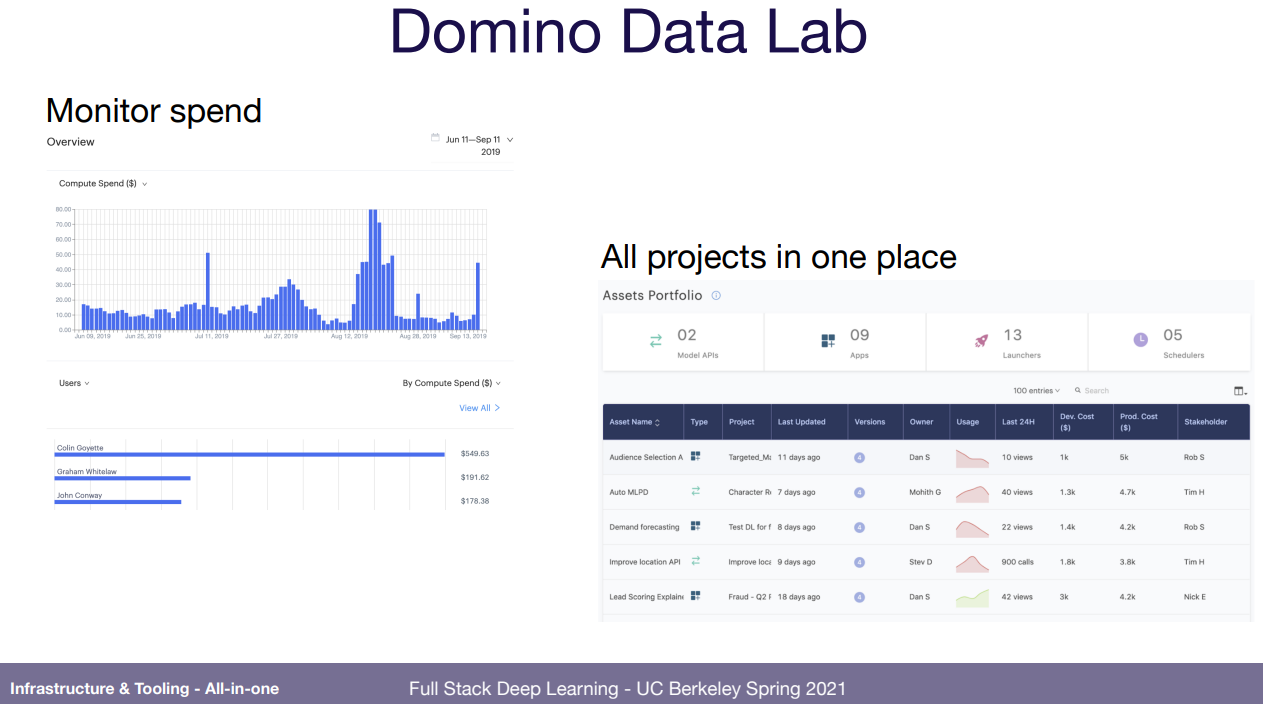

'강의 > fullstackdeeplearning_spring' 카테고리의 다른 글
| Lecture 9: AI Ethics (0) | 2022.03.21 |
|---|---|
| Lecture 8: Data Management (0) | 2022.03.20 |
| Lecture 7: Troubleshooting Deep Neural Networks (0) | 2022.03.12 |
| Lecture 5: ML Projects (0) | 2022.03.01 |
| Lecture 4: Transformers (0) | 2022.02.25 |