https://fullstackdeeplearning.com/spring2021/lecture-7/
Full Stack Deep Learning
Hands-on program for software developers familiar with the basics of deep learning seeking to expand their skills.
fullstackdeeplearning.com

강의 위치는 여기. Training 과 debugging. 근데 왜 이거 설명하는데 1시간을 쓰냐? 실제 업무에서 제일 많은 시간을 들이는 곳이다. 이 강의를 들어도 변함은 없지만 더 효율적으로 시간을 쓰도록..

머신러닝에서 디버깅이라는건 걍 삽질이다..


왼쪽이 논문 원본. 오른쪽이 내가 한 결과라고 해보자. 왼쪽은 에러가 30% 조금 밑인데 내가 한건 40%를 넘는다.
왜 그럴까?

진짜 코드를 잘못 짰던지, 하이퍼 파라미터를 잘못했던지, 모델을 잘못 골랐던지, 데이터가 이상하던지로 크게 4가지로 나누는 듯.

코드 잘못짰을 때. glob로 가져오면 순서가 엉망이 되서 label을 제대로 매칭해줘야 하는데 그렇지 않은 경우.
얜 한번 당한 경험이 있어서 glob는 별로 신뢰하지 않음..


논문에서 썼던 거랑 다른 데이터를 썼을 경우. 물론 잘 나올 수 있겠지만 장담못한다.

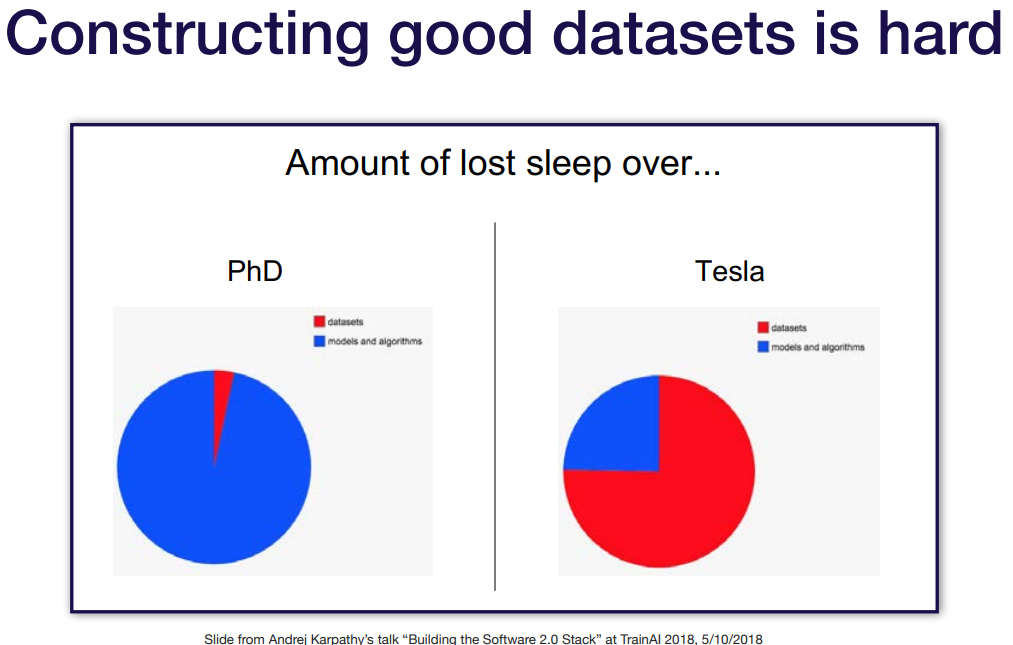
데이터를 잘못 썼을 경우. 시간을 데이터에 많이 쓴다. 그래도 어렵다..
결국은 뭐가 문제인지 모르고 걍 쉐도우복싱할 수 있음.


문제 잡기 전략. 괜히 처음부터 복잡하게 짜서 만들면 정말 많은 고려사항들이 생기기 때문에 최대한 간단하게 시작해놓고 점점 키우는 방식을 추천한다. 모델도 처음부터 resnet쓰고 이런게 아니라 걍 hidden layer 하나에 Fully Connected Layer만 연결시키든지 등. 일단 잘 학습이 되나 보고 키워나간다.

우리가 도로에서 보행자가 있는지 없는지 판단하는 모델을 만든다고 예시를 들어보자. 이 예시로 시작해볼 거임. 물론 자동주행에서 보행자 감지는 중요한거라 99%보다 더 높은걸 만들어야 하는듯.


강사가 추천하는 가장 간단한 모델. 이미지는 Le-Net 같은거 쓰다가 나중에 ResNet을 고려, 자연어 같은 순서가 있는건 LSTM 쓰다가(바로 transformer도 가능하긴 함) transformer로 바꾸던지, 다른것들은 hidden layer는 하나만 두고.

멀티모델에서 가장 간단하게 만드는 예시.

optimizer 및 parameter 설정. 자기 생각과 보편적으로 알려진걸 쓰자. optimizer는 adam이 제일 유명하지만 sgd도 써도 됨.
강사가 강조하는건 regularization과 data normalization인데 input을 넣을 때 정규화 시키는건 뒤에 나오고, 여기선 batch norm같은걸 얘내가 뭘 하는지 알기 전까진 쓰지 말라. 얘내가 버그의 흔한 원인이기 때문이다. 라고 함.

입력 데이터 정규화 하는거. 주의할 점은 라이브러리가 알아서 하는지 잘 볼것. 내가 만약 이미지 0~255인거 직접 0~1로 바꿔줬는데 라이브러리가 하게되면 또 255로 나눌 수 있어서 조심.

그 다음 고려사항은 그냥 하면 되는데 데이터 갯수를 늘일지 줄일지, label을 줄여볼지 같은거.

그래서 이렇게 정했다 치자.



모델을 실행해보고 디버그 해보기.
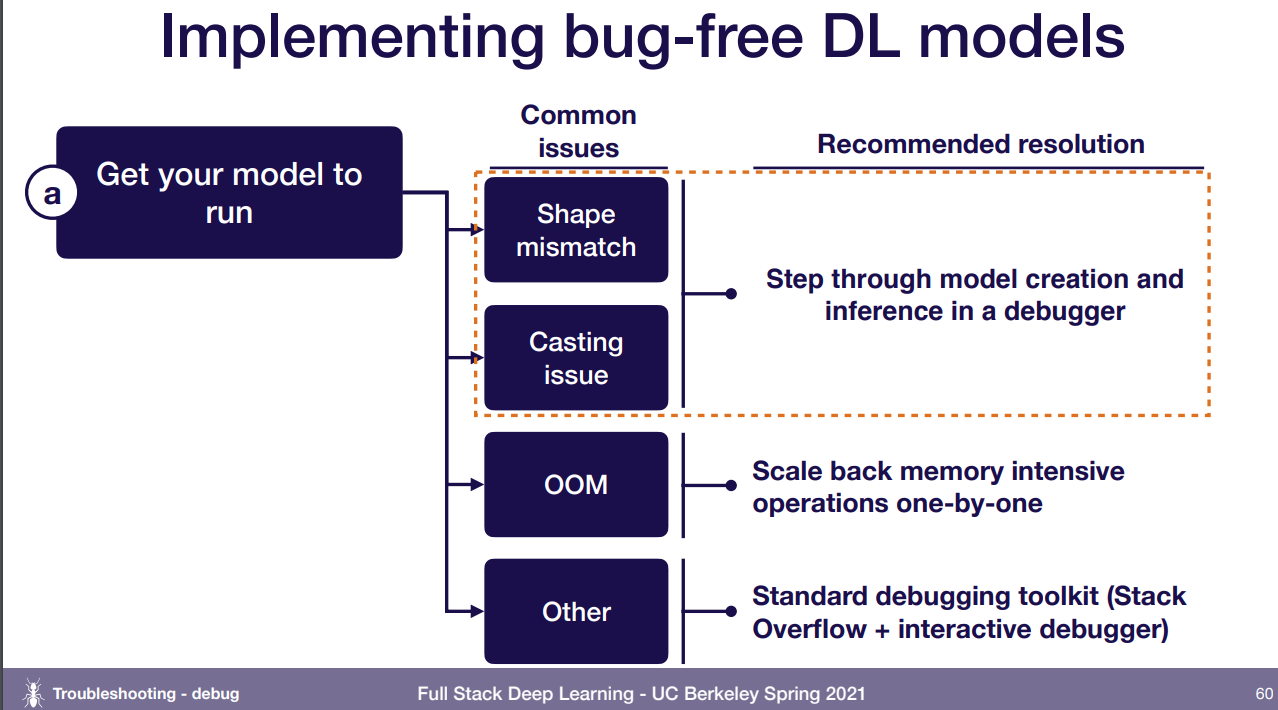
일단 돌려보기. 물론 말이야 쉽지.. 일반적으로 일어날 수 있는 버그들.
모델에서 레이어 수 같은거 잘못 쳤다던가, 잘못된 변수 타입(float 해야되는데 int 등)을 줬다던가, Out Of Memory, 그 외에 다른 것들..
shape mismatch와 casting issue는 모델 잘 들여다보고, OOM은 메모리를 많이 잡아 먹을만한 곳을 살펴보자. 모델이 너무 크던지(특히 Fully Connected layer 폭발하는거 조심), 데이터가 너무 크던지(batch size를 줄이던 아얘 다른 데이터 종류로 변환시키던).. 그 외의 것들은 디버그툴 추천하던데, pdb랑 ipdb 추천해줌. 다 디버깅 툴인듯.
pdb는 그냥 python 디버깅, ipdb는 ipython 디버깅용. 기회되면 써봐야 할듯.

그 다음엔 한 batch의 데이터에 대해서만 overfit이 될 때까지 학습을 해보자. single batch이기 때문에 보통 1분내로 금방 overfitting이 됨.
오히려 에러가 늘어나면 loss 에 -를 하진 않았는지, 진동하면 데이터랑 라벨이 달라서 학습 자첵라 안되는 것인지등.
근데 왜 이렇게까지 하나하나 점검하느냐? 만들다보면 무조건 버그가 뜰 껀데 이미 코드가 1000줄이 넘어가는데 원인을 찾는데 한 세월 걸리다가 걍 단순한거 하나 잘못됐던거일 수 있음. 이런건 처음에 single batch로 돌려봐도 알 수 있는건데 안해서 하루를 걍 날린 거임.

그 다음은 내가 알고있는 것과 비교. 논문에서 쓴 데이터랑 내 데이터가 비슷한지, MNIST로 모델 자체가 학습이 되는지도 실험해볼 수 있고.. 알고리즘 없이 그냥 랜덤으로 돌렸는데도 비슷하거나 덜 나오면 학습이 안되는걸 알 수 있음.
재밌는건 이 사람도 깃허브에서 공식인증된 코드 가져와서 돌려도 버그가 뜨기때문에 다른 코드들을 더더욱 믿지 않는다고 함.

evaluate 부분은 어.. 솔직히 뭘 말하는지 모르겠는데 일단 에러를 저렇게 정의할 수 있다. 더 이상 줄일 수 없는 error와 train error 차이는 아직 덜 학습된것, train과 val 사이는 overfitting, val과 test 사이는 val에 overfitting 된 정도.

그래서 test error는 저런식으로 정의가 가능한데 애초에 이런 생각은 train dataset, val dataset, test dataset이 모두 같은 분포를 하고 있다고 가정하고 온거다. 즉 여기 이 dataset들이 실제로 일어날 수 있는 모든 경우의 수를 다 가지고 있다고.
과연 그럴까?

당연히 실제론 안그렇다. 왼쪽이 우리의 dataset이고 오른쪽이 실제 세상이다.
그래서 우리가 실제 세상에 맞게 잘 학습하는지 확인하기 위에 train data에서 train용 val을 나누고 실제 test data에서 test용 val를 나눈다고 한다. 즉 val이 2개임.


이렇게 하면 우리의 train dataset과 test dataset 사이의 분포 차이가 얼마인지를 측정할 수 있다.
데이터 숫자가 아무리 적어도 이건 정말 중요하다고 계속 강조한다. 지금까지 test로 나누는것도 귀찮아서 안했는데 반성..

그래서 나눠서 봤다. train error 가 목적에서 아직 한참 벗어났다. 즉 한참 under fitting이라는 소리. 이제 어떻게 해야 할 것인가? improve model/data



under-fitting은 단순히 더 성능 좋게 하는 방법을 찾는거임. 모델에서 레이어 몇개 추가해보던지, 아얘 다른 모델로 교체하던지, 하이퍼 파라미터 조절 하든지..
알아야 할건 sota모델을 사용하는 우선순위가 꽤 밀려있는데, 다른 모델로 바꿀 시 우리가 앞에서 했던 single batch 같은 것을 다시 해서 모델을 만들어야 하기 때문이다. 또 add features가 원래 일반 알고리즘에서는 최우선순위인데 여기선 밀려난 것. 하지만 딥러닝에서 add features가 우선순위가 제일 밀리지만 확실히 효과적일 때가 많다.

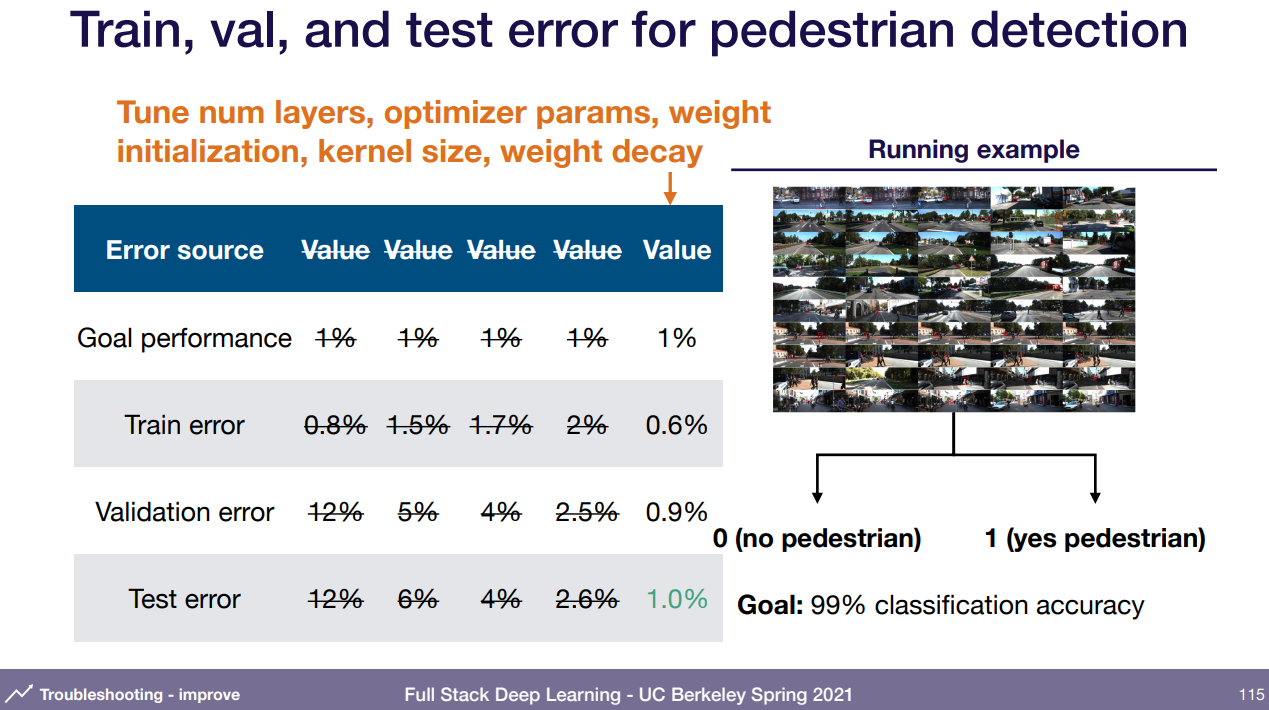
그 다음엔 overfitting 조정. 일반화 시키는 과정이라 data 추가, argumentation 추가와 regularization 증가(dropout, L2, weight decay) 등. 강사가 얘기하는건 밑의 early stopping, feature 제거, 모델 크기 감소는 추천하지 않는다고 하는데 경험상 이득일 때가 거의 없었다고 함. 특히 early stopping은 마치 정석처럼 여기저기 알려지고 유명하지만 실제론 매우 별로다.
그래서 이것까지 해서 test error를 목표에 맞췄다고 하자.

이제 할 수 있는건 에러 데이터에 대해 하나하나 직접 보면서 분석하는 거다. train에서는 적은데 test error에는 이 부분이 많네? 하는걸 가져와서 distribution을 맞추는 것. train용 val dataset과 test용 val dataset의 차이를 줄이는 거.
데이터를 모으기 어렵다면 합성을 하면 된다. 그 외엔 도메인 특화된 데이터 조정.

에러 종류를 하나하나 보면 이렇게 될 것. 사람이 보기에도 거의 안보이는 것과, 유리창에 비치는 것은 공통인데, test-val datset에만 있는 에러가 있다. 이런게 distribution이 다른거임.
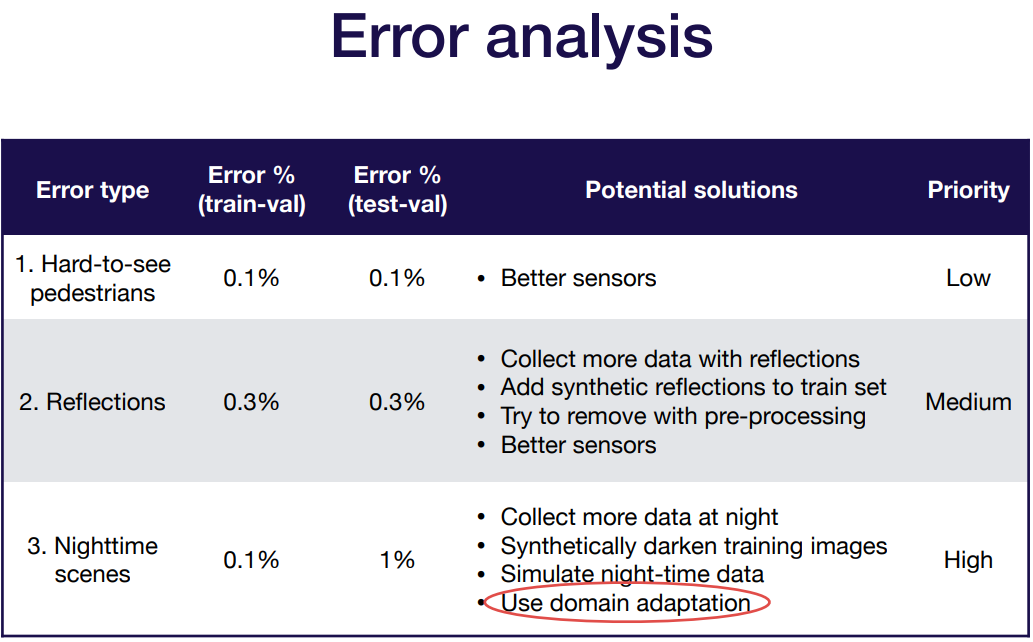
사람이 거의 안보이는건 그냥 더 좋은 센서를 붙이면 되고, 유리 반사는 고전적인 알고리즘 처리나, 반사되는 train data를 더 찾거나, 반사를 합성하거나, 아니면 단순히 더 좋은 센서를 달거나. 지금 하기에는 복잡하거나 힘든 부분이 있기 때문에 우선순위를 좀 뒤로 두자.
문제는 야간시야때. 데이터를 더 찾거나, 합성하거나 만들어내는거는 같은데 domain adaptation을 쓴다. domain adaptation이 뭐냐?

domain adaption은 현재 우리가 닥쳐있는 문제인 test distribution은 잘 해결하기 위해, 그러나 test distribution에 해당하는 label 데이터는 없지만 매우 비슷한 unlabel 데이터는 넘쳐날 때 쓰는 방법. 즉 test distribution에 대한 데이터를 매우 적은 label의 데이터나 unlabel로 학습하는 거.

domain adaption 종류. supervised에서 fine-tune은 매우 유명하고, 데이터 추가 부분은 이미 label data가 넘쳐나는 걸로 먼저 pretrain을 한 다음 label이 별로 없는 걸 학습하는 거.
un-supervised는 세상에 unlabel 데이터가 매우 많기 때문에 제일 실용적이고 연구적인 부분. 많이 연구하고 있어서 1~2년이면 사라질 수도 있겠지만.. 걍 unlabel로 학습하는 거다. 내가 알고있는건 Contrastive Predictive Coding(CPC), simsiam임. 물론 더 있고 보면 진짜 라벨 없이 학습한다.

test-val이 test보다 매우 좋을 경우, 이젠 test-val에 overfitting 된거다. val data가 적거나 하이퍼 파라미터를 너무 조정한 경우. 걍 val을 더 추가하거나, 바꾸거나, 실제 test를 꾸준히 제출하는 등으로 막을 수 있음.

하이퍼 파라미터 최적화. 뭘 어떻게 쓰는게 좋을까.

모든 하이퍼 파라미터들이 자기들끼리와 모델과도 연관성이 있기 때문에 정하기 어렵지만 다행인건 이미 정형화 된 수치들이 좀 있다. default 어쩌구는 무슨 말인지 모르겠음.
오른쪽이 추천해주는 거.

하이퍼 파라미터 조정하는 방법들. 직접 지식을 활용하여 직감으로 맞추기(때려 맞추기). 이미 전문가라면 제일 빠를 수 있지만 잘 알아야 하고 시간 소비가 많이 됨.
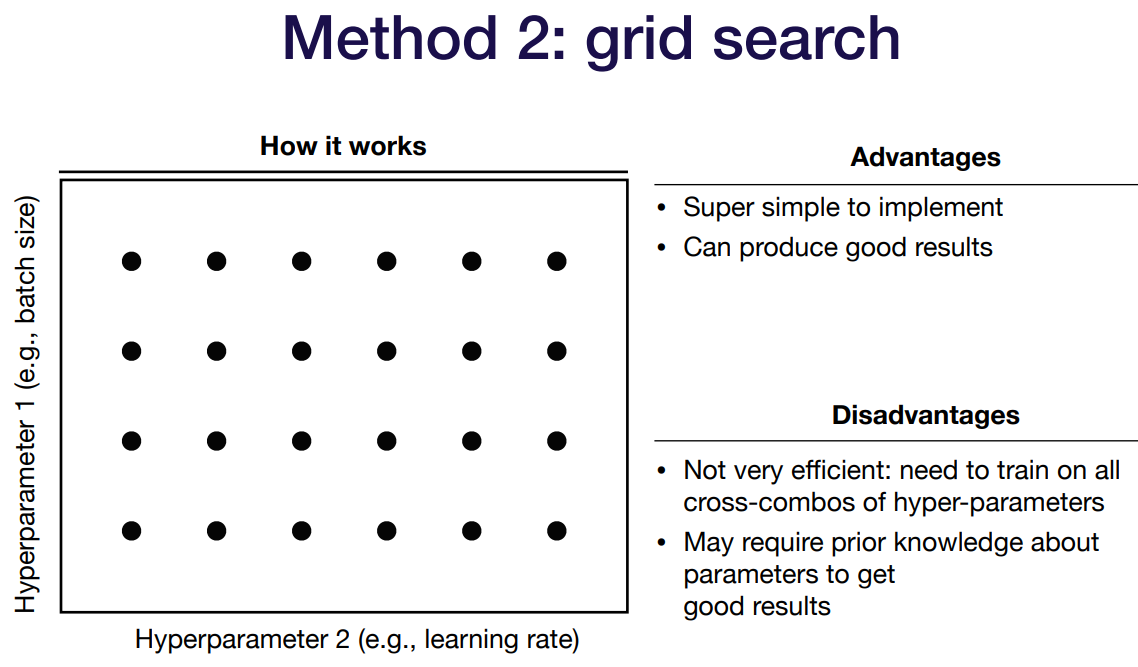
두번째 grid serach. 정직하게 매 간격마다. 엄청 간단하지만 모두 다 해야 해서 너무 비효율적임.

random search. 아주 쉽고 grid search보다 좋을 순 있지만 해석이 잘 안됨. 예를들어 lr을 1e-3으로 했다고 하면 알아듣지만 0.015878215 으로 했다고 하면 ???. 해석하려면 사전지식이 있어야 된다는 듯.

coarse-to-fine은 random search에서 좀 더 잘나오는 곳 같으면 거기서 다시 해보고, 다시 해보고.. 를 함. 관점을 만들고 실용적인 듯. 다만 직접 짜야하는게 있는듯. 강사도 이걸 추천했음.

Bayesian. 분포도와 가능성을 통해 알아서 잘 찾도록 만들어진 알고리즘. 보통 좋지만 직접 만드는게 어려운 듯. 그래서 라이브러리를 사용하면 좀 줄일 수 있음.

제일 추천하는건 처음에 논문쓰거나 할 땐 Coarse-to-fine을 쓰고 모델이 커져서 상용화 하려고 하면 Bayesian을 써봐라.

결론은 ML이 디버깅이 어려운 이유가 정말 많은 요소들을 한번에 사용하기 때문이다. 그래서 이러한 테크닉들이 등장한 것이고, 여기서 제시한 건 할 수 있는한 최대한 간단한 것 부터 시작한 다음 천천히 복잡도를 키워나가서 생기는 문제들을 쉽게 발견하고 분리시키도록 한다.
'강의 > fullstackdeeplearning_spring' 카테고리의 다른 글
| Lecture 9: AI Ethics (0) | 2022.03.21 |
|---|---|
| Lecture 8: Data Management (0) | 2022.03.20 |
| Lecture 6: MLOps Infrastructure & Tooling (0) | 2022.03.04 |
| Lecture 5: ML Projects (0) | 2022.03.01 |
| Lecture 4: Transformers (0) | 2022.02.25 |