https://fullstackdeeplearning.com/spring2021/lecture-8/
Full Stack Deep Learning
Hands-on program for software developers familiar with the basics of deep learning seeking to expand their skills.
fullstackdeeplearning.com
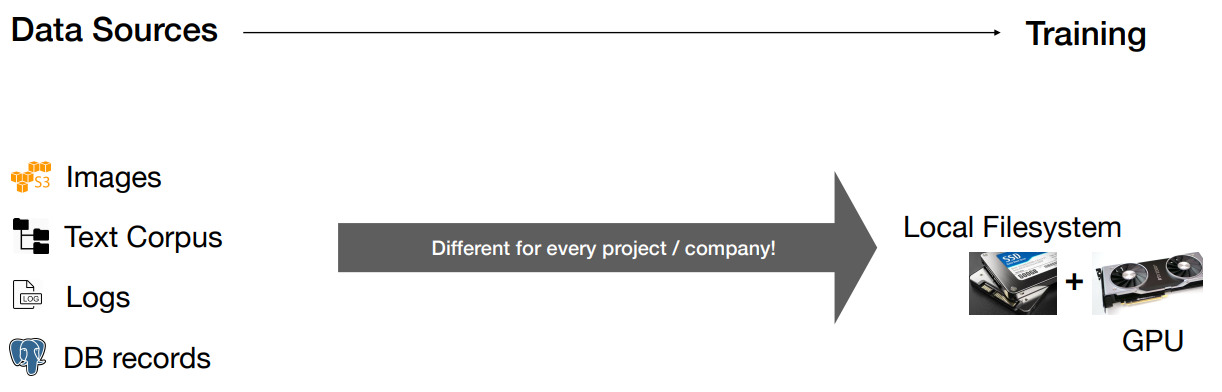
목적은 데이터 소스부터 local 파일로 변형해서 gpu로 넣어 학습시킬 수 있게끔 변화시키는 거다.
데이터가 처음부터 만들어져 있는거면 걍 넣던가, spark같은 걸로 사전작업하고 pandas로 좀 살펴보고 넣던가, 모아서 정리하던가 등의 작업을 거침.

데이터 관리 부분에서 데이터가 실제로 가치있게 변형되려면 10배의 시간을 쏟아야 되고, 우린 그걸 원하지 않는다고 한다. 그래서 효율적이면서도 가장 단순하게 작업하고 싶다.

여기서 왼쪽 데이터 부분임.
일단 소스부터 보자.

공통 데이터 가지고는 경쟁을 할 수 없기 때문에 각 회사들은 자기만의 자산 데이터를 보유해야 한다. 예외는 구글같이 돈으로 때려박아야 만들 수 있는 모델인듯.
물론 공용 데이터도 처음 시작점을 만들기엔 좋다. 없는거보단 낫다는 생각인듯.

그래서 데이터를 어떻게 모으냐. 여러 방법이 있는데 돈으로 사는 경우. 데이터 모으는데 시간쓰기 싫으니까 다른 사람의 노력과 시간을 돈 주고 사는 거다.
이거 말고 사용자에게 정보 제공받는거랑, data augment, unsupervised learning이 있음.


semi-supervised가 요새 상당히 잘 나온 듯. SEER는 semi를 쓰고도 sota 정확도를 달성했다. imagenet이 1M개인데 그냥 랜덤 이미지 1B개로 돌린 결과인듯. 현재 VISSL로 열려있다.
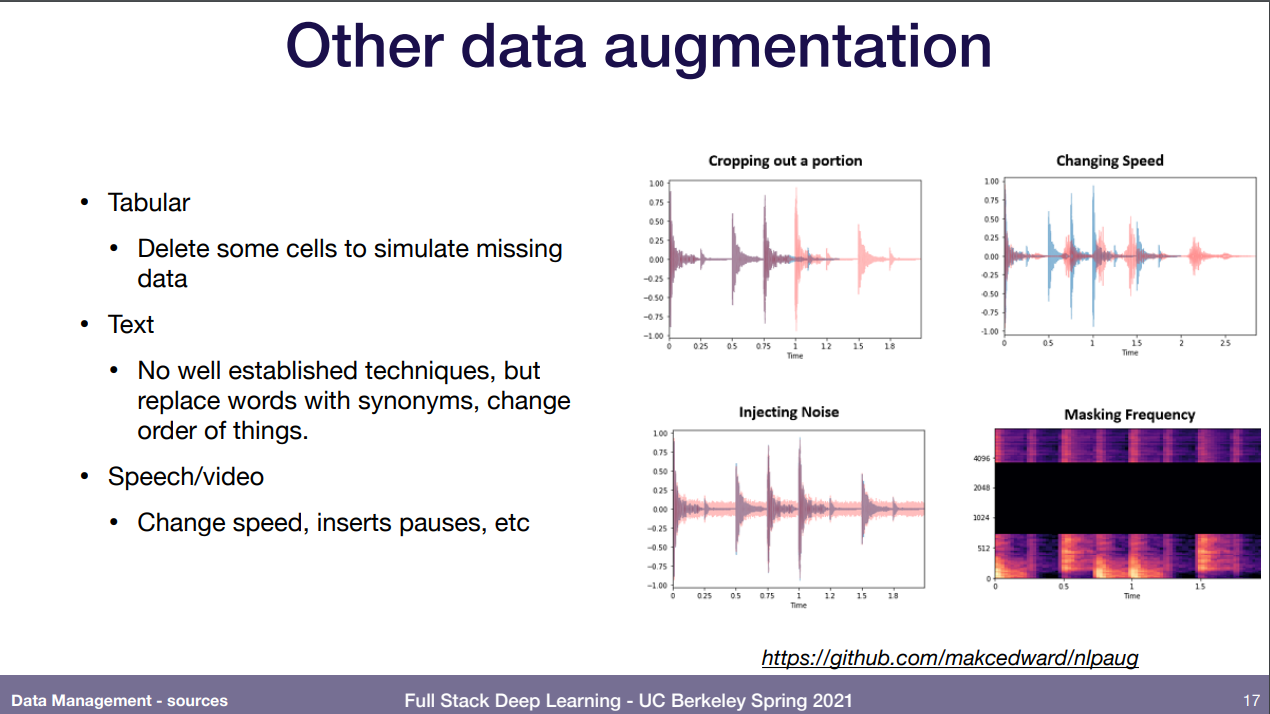
이미지는 반드시 해야하며 이리 여러곳에서 제공하고, 텍스트는 딱히 할 게 없으니 중간에 빼서 맞추라던가 어떤 종류인지 맞추기 그런거로 하는 듯. 소리는 잡음넣기 등.

얜 못알아들었는데 좋은것 같다고 해서 적어둠.


재미있는건 언리얼 엔진 같은걸로 만들기도 한다고 함. gta-5 dataset을 들어봤는데 비슷한거인듯.
게임엔진으로 만들면 각 광원효과 같은걸 직접 넣을 수도 있고 각 픽셀이 무엇을 의미하는지 이미 다 알고 있으니 너무 좋다고 강조한 것 같다.


파일 시스템은 그냥 우리가 아는 일반적인 파일 단위들(.jpg)을 의미함. 걍 여러 방식으로 쓰일 수 있다 정도 얘기하는 듯.

이건 저장 디스크에 따른 속도 차이. sata SSD는 걍 아는 ssd고 밑의 NVMe ssd는 최신 기술.
HDD는 그 뭐지 원형 철 뺑뺑이 돌리면서 작대기 하나로 여기저기 읽는 방식이라 물리적으로 느릴 수 밖에 없다. 그런 얘기 함. 그냥 SATA ssd도 괜찮다.

로컬 데이터 종류. 걍 파일임. HDF5는 예전에 본 적 있었는데 엄청 압축이 좋지만 좀 불안해서 요샌 안쓰는 추세고, Parquet를 쓰는 추세다. 이게 spark나 hadoop에서 빅데이터 다루는 파일 단위인데 spark나 hadoop에서 다룰려고 이게 정형화 된 것 같다. 또 얘기한건 Apache Arrow에서 사용하는 Feather인데 해가 지날수록 엄청 좋아지고 있다고 얘기 함. 물론 우린 tensorflow나 pytorch의 dataset class를 다뤄야 하는데, 여기서 뭘 안하면 시간을 느리게 잡아먹네 뭐네 했는데 못알아들음.

저장소? 를 얘기하는 것 같다. 종류는 이미지, 소리, 걍 바이트 파일 다 포함. 재미있는건 백엔드를 직접 관리하는 형태라 파일을 굳이 지울 필요 없이 v2 로 버전업시켜서 따로 보관하게 할 수 있는듯. 로컬보단 느리지만, 클라우드에서 충분히 빠르다. 특히 저 S3의 파일 안정성을 보아라. 같은 파일에 대해 지역별로 저장해서 데이터를 잃으면 서로 보완하는 방식이라 데이터가 안정적일 수 밖에 없음. 걍 돈의 상징임.

데이터베이스에는 단순히 한번 읽고 지나가는 로그같은 정보들이 아니라 규칙에 맞춰 (스키마에 맞춰) 저장한 뒤 지속적으로 접근하고 수정하는 걸 넣는거다. 파일 읽는게 사실 램에 올린 뒤 읽는거라 디스크에서 그 원통 돌려가며 읽지 않아도 되기에 훨씬 빠른건 당연하다. Postgres가 대부분에서 좋고, 모바일 같은 가벼운 프로젝트면 SQLite도 좋다. 단지 NoSQL은 정해진 스키마 없이 걍 내가 저장하고 싶은거 json으로 만들어서 지맘대로 저장해놓은 건데 정말 안좋다. 이런걸 쓸 바엔 Redis라는 좋은게 있으니 사용해봐라.

데이터 웨어하우스는 저장되어 있는 자료가 어떻든 간에 모아서 하나의 스키마 형식으로 데이터 웨어하우스에 올리는 역할이다. 이걸 OLAP라고 함. 다른 말로는 ETL 이라고 함. 프로그램은 구글 클라우드의 BigQuery, snowflake, 아마존의 redshift가 있음.

SQL과 pandas의 dataframe과의 관계. 일정한 스키마 형식으로 저장하는건 SQL이지만 파이썬을 쓰는 사람은 보통 데이터를 pandas의 dataframe으로 분석하길 기대한다. 다 sql문 쓸 수 있지만 sql이 그룹 형식으로 더 잘 볼수 있다고 했었나. 어쨋든 이건 데이터 분석가, 데이터 엔지니어, 머신러닝 엔지니어라면 당연히 유능하게 사용할 줄 알아야 하고 심지어 머신러닝 분석가도 어느정도는 알아야 함.

data lake는 앞에서 봤던 스키마로 정형화된 정보들 포함 걍 로그같이 한번 지나가는 것들도 일단 data lake에 다 쑤셔넣고 필요할 때마다 변형해서 사용하는 것이다. 현재 트렌드는 Lake House라는 오픈소스가 있다.

요약? 하자면 이미지, 사운드 파일같은건 s3등에 넣고, 라벨이나 지속적으로 바꿔야 하는 유저 정보같은건 sql에 넣고, 한번 지나가서 굳이 다시 접근 안하므로 sql에 없는 로그 같은 것들은 data lake에 일단 쑤셔넣어서 필요할 때 사용한다. 그래서 훈련할 때 여기서 가공된 데이터 가지고 학습한다.

나름 역사가 있는듯. 관심이 있다면 이 책을 볼것을 추천해줬다. 매우 매우 매우 매우 좋다고 한다.

이제 데이터 프로세싱 부분을 보자. 사진 인기 예측기를 만든다고 하자. 어쨋든 머신러닝 엔진을 돌려야 한다.

근데 각 일들 간의 dependency가 있다. 즉 이 일을 끝내기 전에 다른 일이 먼저 끝나야 내 일을 진행할 수 있다는 것. 뭘 하고자 하느냐에 따라서 다르고, 파일보다는 프로그램 상에서 생기는 문제고, 이 일들은 여러 분산된 컴퓨터에서 진행되야 하고, 우린 이런거 모르는 상태로 단순히 입력 -> 출력으로 하고 싶다.
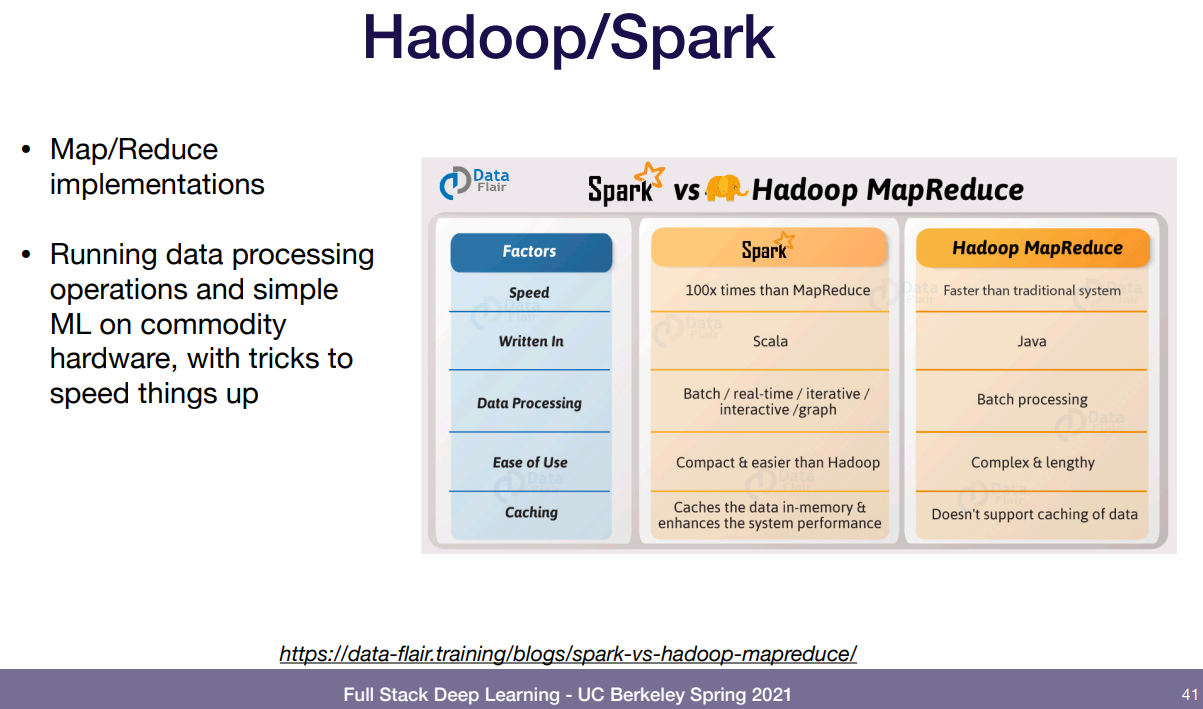
그래서 나오는게 spark나 hadoop의 reduce 같은거. reduce가 입력 여러개 주어지면 하나의 결과로 압축해서 출력하는 거니까 이걸 소개해 주느듯. 분산도 얘내가 알아서 다 해준다. 캐싱 처리도 알아서 해줘서 빠름.
하지만 요샌 이렇게 안한다. 이유가 뭐냐면 우린 pytorch같은걸로 모델 만드는데 spark로 이런 처리 과정을 진행했다면 pure python으로 모델을 만들던가 spark로만 만들어진 모델만 사용할 수 있기 때문.


그래서 요샌 분산처리 매니저를 사용한다. 사전 작업등은 sql로 해도 화살표만 잘 이어주면 된다. 그럼 매니저가 모든 분산 업무 처리에 대해 알아서 처리하고 관리한다. 위에 airflow라고 적은 이유가 apache airflow도 이런 매니저 중 하나라서 그런 듯.
tensorflow는 apache beam이라고 해서 정말 다양한 데이터셋을 처리할 수 있게 연계해서 만든 것 같고(예시로 든건 크롤링 한건데, 사이트 크롤링 한 사이즈가 7TB인데 얘내를 사전가공 해서 훈련으로 쓸수 있게끔 만들었다.), 이런 airflow와 똑같은 생각을 한 prefect도 파이썬에서 돌릴 수 있고 사전을 sql로 하든 해서 prefect로 보내면 하드웨어한테 뭘 해야 하는지, 어떤걸 처리하는지를 분산처리나 한번에 해야하는 다른 작업들 같은거 다 해서 걱정할 필요가 없다. 이런 처리기를 orchestrator 라고 부르는 듯.
또 dbt도 있는데 sql만 써서 사용 가능하게끔 만들어져서 분석가들한데 너무 좋을 것 같고, 요새 뜨는건 Dagster. 많은 orchestrator 툴 지원에 로컬 어느곳에서든 테스트 가능하단다.

잠깐 배포쪽을 보자. Feature Store 쪽.

feature store가 처음 제안된 곳은 강사가 기억하기론 uber의 Michelangelo 모델에서다. 온라인이랑 오프라인으로 나뉘고 전처리는 오프라인에서 하는 듯. 모든 데이터가 쑤셔박아져 있는 data lake에서 데이터 가져와 spark든 sql이든 사전 작업을 해서 Hive 기반 Feature Store에 업로드 한다. 여기서 나온 데이터로 모델이 훈련을 한다. 그래서 모델이 만들어지면 배포용 예측을 하는데(온라인 말하는 듯) 얘는 훈련할 때와 같은 흐름으로 가지 않는다. 여기 같은 경우 여러 분산된 flow를 지나서 Kafka streaming engine으로 가서 cassandra 기반 Feature Store로 가서 이미 훈련된 모델로 간다. 굳이 이렇게 복잡하게 하는 이유는 우리가 작업을 온라인과 오프라인으로 나눠서 작업 하는데 똑같은 것을 두 개로 나누는건 많은 버그를 일으킬 수 있으므로 만약 이것을 통일된 Feature Store로 합칠 수 있다면 두개로 나누는 코드나 버그들 생각할 필요 없이 훨씬 낫다.

여기 회사에서 만들어준 또달 예시 사진인데 뭘 하든 feature store를 통해서 예측할 때와 훈련할 때 데이터를 동일하게 만들어준다.
이거랑 같은 컨셉의 오픈소스 FEAST가 있으니 관심있으면 한번 보자.

하지만 일단 생각해보자. 앞에서 카프카니 카산드라니 너무 많은 얘기를 했다. 우리의 목적은 간단하게 엔지니어링 하는 것. 실제로 오버엔지니어링을 하는 경우도 많다.
간단하게 가자며 일반 UNIX 계열이 얼마나 빠른지 소개해줬다. hadoop으로 26분 걸리는걸 unix에서 70초만에 끝냈고, 아얘 unix에서 병렬처리 최적화로 만들어진걸 쓰면 18초가 걸린다. 왜 이럴까? 우리가 unix에서 단순하게 | 을 쓰는것, 얘를 들어 a | b 로 실행했으면 a를 한 결과를 b로 넘기는 파이프라인 방식으로 작동되는게 아니라 a와 b가 처음부터 동시에 병렬적으로 실행된다. 그래서 저렇게 빠른 것. 거기더 unix에서 병렬처리용으로 만들어진 명령을 사용하면 더 빠르고, 만약 1000개의 프로세서 코어로 돌리고 싶으면 -p 1000 만 넣으면 된다. 정말 간단하다.
앞에서 카프카니 카산드라니 했던걸 다운받아 이해하는게 보통 가장 좋은 전략은 아니다. 내가 이미 가지고 있는 툴을 사용해서 더 간단하게 해보자.

그 다음에 얘기한건 분석인데 pandas는 이미 다 알테니 넘어가고 혹시 모를수도 있을 DASK와 RAPIDS를 설명해줬음.
DASK는 pandas로는 데이터가 너무 커서 메모리에 안들어가고 속도도 느린걸 대체하고자 만들어짐. RAPIDS는 pandas의 기능을 GPU로 작업하여 더 빠르게 하려는 프로젝트. 관심있으면 봐라.

다음은 데이터 라벨링.
핵심은 난 배포같은 다른쪽에 집중하고 데이터는 외부의 노력을 회사에 맡기거나 그럴 수 없다면 소프트웨어를 사용하라고 함.

노동자 사용하는 것도 종류가 있는 듯. 전문 라벨링 하는 사람은 확실하지만 비싸고 그냥 단체로 하는게 있나본데 얘는 부정확하고 안전하지 않지만 싸고.. 아님 회사를 쓰던가.
회사쓰는건 별거 없음. 정답 샘플 몇개 잘 알려줘서 부탁하고 중간 샘플 받아서 잘 되나 확인하고.. 이 이후엔 어떤 회사들이 있는지 설명해줬음.

만약 그럴 여건이 안된다. 그러면 소프트웨어를 써라.

label studio는 자신이 정하고 만들 수 있는 오픈소스 프로젝트고, Progidy는 자연어쪽. Aquarium은 랜덤으로 집어서 잘못된거 있으면 수정하고 모델은 계속 돌리고 이런 방식임.
재밌는게 하나 있는데

Weak supervision 이라는 거임. 데이터를 수집하면 일단 heuristic 방식으로 라벨링 해서 자동화한다.
영화 평가 데이터를 예로 설명해줬는데, 영화 리뷰에 긍정적인 단어 awesome같은 단어의 유무를 regex같은걸로 찾을 수 있고 이런 긍정적인 단어가 많으면 좋은 평가, 부정적인 단어가 많으면 나쁜 평가 정도는 알 수 있음. 그래서 regex로 라벨링을 해서 데이터를 만드는거임.


데이터 버전은 뭐냐. 우리가 버전업한 코드 모델로 돌리는데 데이터는 버전없이 그대로 계속 더하기만 한다면 나중엔 되돌릴 수 없다. 그래선 버전이라고 할 수 있겠느냐.
버전 0은 걍 막 하는거고 버전 1은 아카이브로 저장해놓기. 버전 2는 json 파일을 git-lfs 등으로 저장하기고, json 파일만 해도 테라바이트 단위일 테니 특정 툴을 사용하는게 레벨 3인듯.

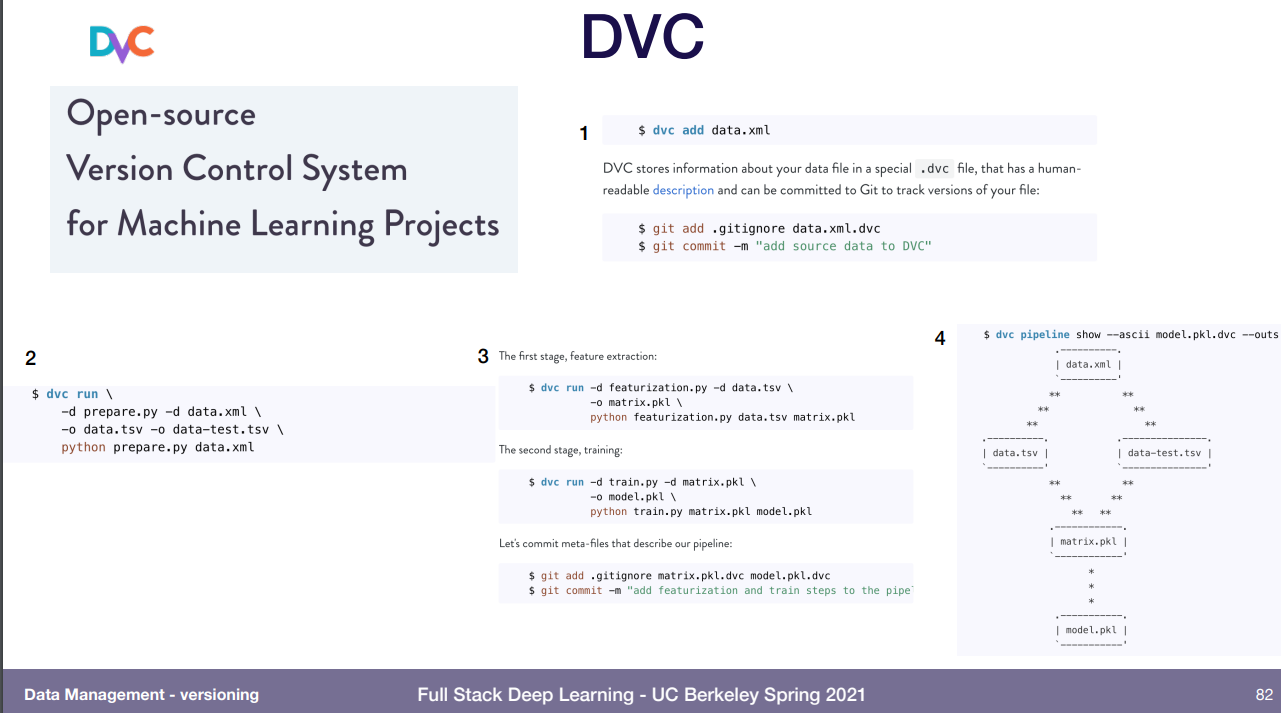
DVC는 머신러닝만을 위해 만들어진 오픈소스고, 잘 못알아 들었는데 코드 치면 별 걱정할 필요없이 알아서 다 해준다, 좋으니 필요하면 확인해보라 해서 적어놓음.

Dolt는 sql용 git이라고 생각하면 됨. git은 한 작업을 여러명이 병렬적으로 진행해서 합칠 때 충돌을 매우 쉽게 처리해주는건데, sql에는 dolt가 있다. 이런 내용인듯.

사생활은.. 데이터에 접근할 필요 없이 학습한다. 이건 우리가 필요한건 weight들이 변화된 모델 뿐이지 데이터가 아니다. 그래서 각 기관마다 서로 다른 기준의 데이터로 학습하고 weight만 가져오는 듯. 이렇게 하면 다른 기관의 데이터도 학습할 수 있는 효과가 있음. 또 다른건 암호화된 데이터로 학습하는 것. 그걸 가지고 있는 사람은 복호화 할 수 없음.
'강의 > fullstackdeeplearning_spring' 카테고리의 다른 글
| Lecture 10: Testing & Explainability (0) | 2022.04.30 |
|---|---|
| Lecture 9: AI Ethics (0) | 2022.03.21 |
| Lecture 7: Troubleshooting Deep Neural Networks (0) | 2022.03.12 |
| Lecture 6: MLOps Infrastructure & Tooling (0) | 2022.03.04 |
| Lecture 5: ML Projects (0) | 2022.03.01 |