
https://fullstackdeeplearning.com/spring2021/lecture-10/
Full Stack Deep Learning
Hands-on program for software developers familiar with the basics of deep learning seeking to expand their skills.
fullstackdeeplearning.com
다음 강의는 배포 강의인데 배포하기전에 정말 최적화가 잘 되었는지, 정확도는 충분한지 알아보는게 이번 강의

우리가 모델을 잘 만들었다고 해도 소비자는 그걸 정말로 믿을 수 있을지 걱정됨. 우리가 훈련한 데이터 분포가 실전의 데이터 분포와 같을수록 믿을 수 있다고 할 수 있다. 또 극단적인 경우도 안될 수 있고, 우리가 하려는건 모델을 만드는게 아닌 모델 시스템을 만드는거라 모델 만들때 신경 안써도 되었던걸 하느라고 문제 생길 수 있음.

정말 정말 깊게 이해해야 한다고 하는데, 예상해야 되는 데이터, 예상해야 되는 결과, 예상하면 안되는 결과들까지 정말 깊게 다룬다고 함.
위에가 강의 아웃라인.

대표적인 테스트들인듯. unit test는 코드 한줄 한줄에 대해 제대로 동작하는지, integration test는 코드 한줄씩만 보고 하다가 좀 뭉탱이로 하면 에러뜰 수 있으니 하는거고, end-to-end는 진짜 처음부터 끝까지 실제의 입력과 출력을 보는 것. 이거 외에 다른것도 많긴 하지만 여기까지.

테스트 방법들.
테스트 자동화는 옛날엔 프로그램 만들고 사람이 테스트하게 했고 실제로 전문 테스터들도 있었는데 자동으로 돌린다. 하지만 조건이 있는데 정답 기준이 매우 명확해야 할것, 즉 ambigious하면 안됨. 결과가 true or false같이 매우 명확하면 자동으로 돌릴 수 있다. 또 정확한지도 확인할 것.
branch merge하는건 협업할 때 매우 중요한데, 깃허브의 CI같은걸 써서 모두 통일된 기준으로 검사하는 거. 그래서 버그가 생기면 잘 되던때로 다시 돌아갈 수 있게. 새로운 기능 생길때마다 테스트하고.
또 구글에서 만든 test pyramid가 있다.

test pyramid가 뭐냐면 unit test를 제일 많이, integration이 중간, end to end가 제일 적게 하는거다. end to end가 실제 사용자 입력, 출력 결과인데 왜 적냐 하지만 unit test는 빠르고, 뭐가 잘못되면 그 하나가 제일 잘못될 확률이 커서 각자 독립적이어서 디버그 후보를 줄일 수 있다는데 있음. 물론 end to end도 중요하긴 하지만 어쨋든 저렇다.

논란이 되는것 중 하나는 유닛테스트에서 Sociable Tests랑 Solitary Tests가 있음.
Sociable test는 내가 한 유닛을 실행하려면 이것과 연결되어 있는 다른 유닛이 작동되어야 작동될 수 있음. 예를 들면 내가 수행하는게 데이터베이스에서 파일을 불러오는 거라면 데이터베이스에서 불러오는 유닛이 되어야 자기 유닛 실행 가능.
solitary test는 내가 하기 위한 이전 단계들의 유닛은 완벽하게 작동한다고 가정함. 임시로 가정하고 값을 채워서 mocking test라고도 부름. 둘 중 어떤걸 쓸지는 자기 프로젝트와 팀에 따라 다르다.

또 test coverage가 있음. 코드 테스트를 할 때 어디 코드에서 많이 불러오는지 확인. 코드 의존성 같은걸 평가하는 개념인 듯.
하지만 강사는 이걸 별로 좋아하지 않는 것 같다. 한 파일에서 많이 불러온다고 그 파일이 좋은 코드라고 할 수 있을까? 정확히 뭘 평가하고자 하는 것일까?

제일 실전적인게 test-driven development (TDD) 라고 하는 듯.
코드를 짜기 전에 테스트 먼저 짜는 개념임. 이렇게 하면 내가 안의 세부내용을 짜기 전에 이 코드를 돌려서 다른것을 하려는 팀에게 먼저 테스트하게 할 수 있음. 이걸 하려면 특정 값에서 원하는 값을 출력하게 하는건 할 수 있으니 일단 이렇게 만든다음 안의 내용을 수정하는 거. 그럼 입력값과 출력값이 정해져 있으니 알고리즘 문제 풀듯이 맞추기만 하면 되는 듯. 입력, 출력을 계속 반복하면서 테스트케이스로 만든 모든 것들이 실제로 동작하도록 만든다.

그 다음은 test in prod. 이쪽이 좀 더 머신러닝 쓸때 가깝다고 함.
고전적인 의미에서 test in prod는 버그를 못찾게 하지만 요샌 바뀐 것 같다.

버그는 어차피 못피하니까, 유저가 버그를 찾을 수 있게끔 도와주는 것. 업데이트 했는데 버그 뜨면 잘 되던 과거버전으로 바꾸고 핫픽스해서 다시 올린다던가.

카나리 개발이라고 베타버전보다 더 앞선 버전같은 건데, 일부의 유저들에게만 배포하고 관찰하는 것. 잘 되면 비율을 점점 늘리는 방식. AB 테스트는 잘 되었던 과거 버전과 업데이트한 현재 버전과 비교. 그리고 진짜 유저 모니터링 저게 뭐냐면 잘 작동하는 비율대 에러 비율로 자동화를 하면 비효율적이라고 해서 실제로 어떻게 사용하는지를 보는게 효율적이라고 한다. exploratory testing은 사용하는 사람을 더 자세히 보거나, metric을 더 자세히 보는거다.
이 test in prod는 처음에 들으면 뭐 이런게 다 있나 생각할 수 있지만 프로젝트가 커질수록 피할 수 없다고 함.

그 다음은 CI/CD. cicd가 뭐냐면 깃허브 같은데에 내 코드를 push 했을 때 빌드는 잘 되는지, 사전에 정해둔 테스트들이 문제 없이 잘 출력되는지 확인하는 역할. 수문장 같은거다.

추천하는게 jenkins랑 buildkite 인듯. 이것들은 한번 세팅하긴 쉽지 않지만 해놓으면 좋은듯.

우리가 알고있는 고전적인 소프트웨어 테스트와 머신러닝 테스트는 어떻게 다른가.
코드는 한번짜면 영원하고, 한 문제를 풀기위해 만들어졌고, 실패하면 에러떴다고 알려주고 상대적으로 변하지 않음. 반면 머신러닝은 데이터까지 봐야하고 문제를 푼다는 개념이 optimizer를 최적화하는 방향으로 문제가 풀리는 거고, 에러가 나도 그게 에러인지 안알려줌. 또 실제 사용시 입력 데이터가 꾸준하게 변함.

머신러닝 테스트할 때 실수들.
모델만을 하나의 독립변수로 생각해서 작업하는 경우가 있다. 하지만 머신러닝 모델은 그것 뿐만이 아닌 전체적인 요소들에 영향을 받음. 그래서 독립적으로 보지 말고 전체를 봐야 한다. 또 모델에 대한 이해가 충분히 되지 않은 상태에서 배포하기도 하고, 사전에 정의한 metric이 실제 상황에 맞는지 측정해봐야 함. 실제 상황에 맞지 않는데 정확도만 올리면 장땡이야! 하면 삽질하는 거다. 나머진 너무 자동화에 의지하지 말고 직접 보기..
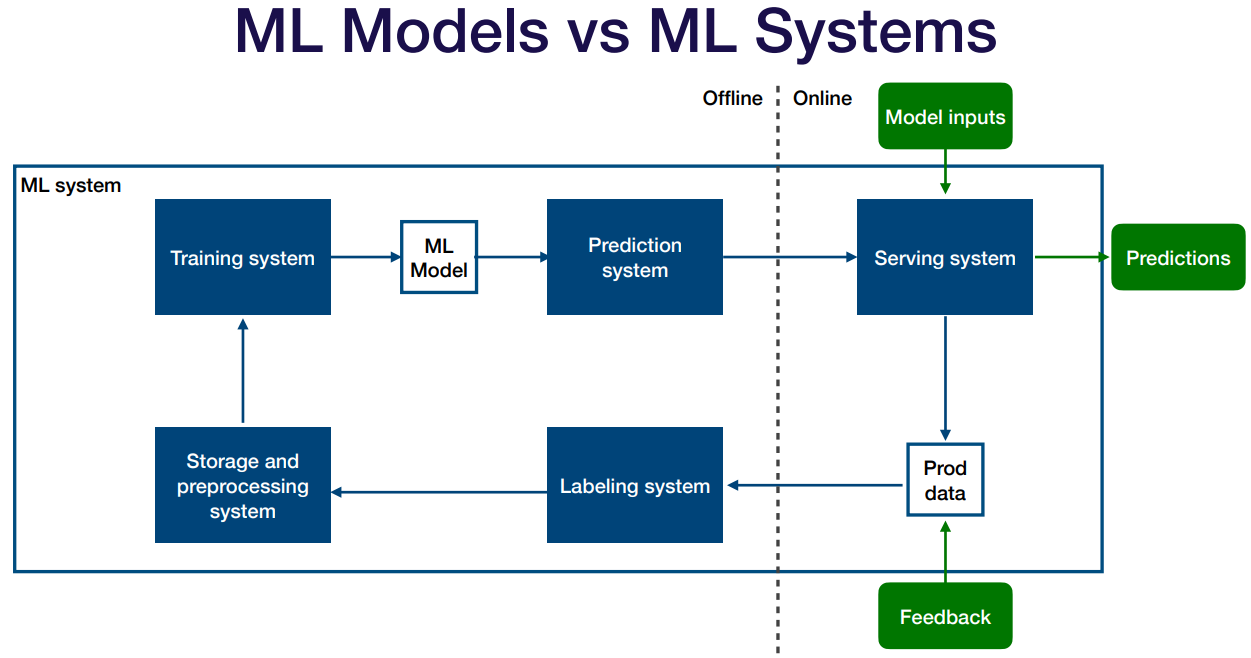
보면 정작 모델은 저렇게 작은 부분이고 데이터만 받고 예측만 내는 역할. 데이터를 받으면 사전정제 하고 내놓고 유저가 피드백 해주면 수정하고 등의 전체적인 과정.
저기서 자세히 나눠서 설명해주던데 training system은 유닛코드가 버그없이 잘 되는지 보고(임시 이미지 넣어 예측값까지 잘 나오는지 확인하고) Storage and ... 부분은 데이터가 정말 잘 되는지 주기적으로 확인하고 Prediction system은 모델에 이상이 없는지. 잘못된 학습을 계속 한 상태로 방치하다가 다음에 봤을 때 완전히 달라질 수 있으니.



하나의 metric만 사용하지 말고 여러 matric을 사용해라. 그럴러면 우선 각각의 뜻이 뭔지 알아야겠지.
NLP는 Behavioral tests 보기.

simulation tests는 비전족인듯. 자동운전을 예로 들었을 때 각각의 경우가 독립적인 여러 시나리오를 적용해봐야 한다. 물론 어려움.

기준점과 slice의 개념.

이상적인건 prod의 데이터 분포와 train의 데이터 분포가 일치할때. 라고 했지만 특이한 edge case를 맞춰야 할 때가 있음. 그런걸 비율에 맞게 추가해주거나 한다.

뭘 보고 모델이 좋아졌다 평가해야되나 threshold.


내가 모델 돌리는거랑 실제 서비스 할 때 결과 차이 줄이기.
목표는 product에서 버그 찾는거, 차이 줄이는거, 문제 찾는거.
어떻게 하냐면 계속 새로운 모델을 개선하지만 새로운 모델과 기존에 잘 되던 모델 두개를 병렬로 돌려서 잘 되던 모델 결과를 유저한테 주고 새 모델 결과를 보며 개선하는 거다. 또 오프라인으로도 돌려보고 하면서 모순점 찾아 해결하는 것.


아까 했던 shadow test는 오프라인 모델이 실제 온라인 모델로 바꿨을 때의 차이를 봤다면 AB 테스트는 유저 행동에 내가 만든 시스템이 어떻게 반응하는지 하는 테스트. 일부 유저로 하는 카나리 테스트 하거나 통계 쓰셈.


라벨링 테스트는 라벨링이 제대로 된 좋은 데이터로 학습을 하는가. 쓰레기 데이터로 학습하면 쓰레기 모델이 되는걸 방지하기 위함.
해결법은 라벨링을 일관적인 기준으로 평가하는지 보는거. 이걸 가이드라인 줘서 좀 줄일 수 있겠지. 또 3명 같은 홀수 라벨러 놓고 투표방식, 믿을 수 있는 사람으로 하기, 일일히 보기, 전의 잘 되던 모델과 크게 반하는지 보기.


그 다음은 데이터 pre-processing 자체가 제대로 되는지. 이걸 파이프라인에 넣어도 되는지 데이터의 질을 점검한다.
어떻게 하냐면 각 단계마다 threshold와 규칙을 정하고 매번 점검하는 거임. 여기선 각 배치마다 한다고 표현한 듯.
그럼 threshold와 rule이라고 했는데 이걸 어떻게 만드냐? 직접 만드는 법과 좋은 데이터의 프로파일을 만드는 것, 아님 이 두개를 동시에 사용하는 것. 이게 무슨 말이냐면 직접 만드는건 규칙 정해본 뒤 해보고 예외 있으면 추가하고 잘못됐으면 빼고를 반복. 프로파일은 이런 데이터의 column은 보통 0~1 사이더라. 그러니 이걸 벗어나면 경고를 울려주자. 같은거. 기준을 정하는 거인듯. 이 두개를 동시에 사용해도 물론 좋다.

적용하려면 생기는 문제들. 이건 ml 엔지니어 문제라 software enginner와 data scientist와는 다른 관점이라 마찰이 있을 수 있음. CI/CD도 gpu가 지원 안됨. jenkins 같은걸 쓰면 쉽겠지만.. 그 외 여러가지.

중요한거 같은데 못알아 들어서 뺌. 필요하면 링크 들어가서 읽자.

설명 가능하고 이해 가능한 인공지능. 근데 이 단어가 뭔 뜻이냐

여러 관점에서 봐야 할 듯. 도메인 예측 가능성. 사람이 인지하는 방식으로 계산하느냐, 이해할 수 있는 정도. 등..

모델을 이해 가능하고 설명 가능하게 하기.

이해 가능한 모델 집군들. 모델은 애초에 weight와 bias가 있고 이거에 따라 더하고 빼는거 밖에 없음. 그래서 저런 모델들은 이해 가능하고 설명 가능하지만 간단해서 엄청 좋지는 않음.

attention 모델은 이해는 가능하지만 설명 가능하지는 않음. 이해 가능하다는건 모델이 저기를 보고 있어서 저런 결과를 내놓는구나~ 라고 할 순 있지만 왜 저기를 보냐는 설명할 수 없음.

이 개를 예시로 들던데 개가 저기 있어서 모델이 저기를 보기 때문에 개라고 하는구나 이해는 할 수 있지만 왜 저게 개라는 건지는 알 수 없음. 개라고 해도 전체가 다 안보이는데 왜 개라고 하는가. 서있지 않은데 왜 standing이라고 하는가. 섬유 침대 밑에 있는데 더 특징같은데 왜 바닥 위에 있다고 했는가.

그래서 너무 의지 하지 말라는 논문도 나온 듯. 똑같은 이미지에 대해 허스키라고 했을 때 허스키를 보는건 이해가는데 다른 단어를 말해도 허스키를 바라봄.

대체 모델은 어려운 모델이 있으면 그걸 설명 가능할 만큼 쉬운 모델로 바꿔서 어려운 모델을 설명하는 거임. 쓰기엔 쉽지만 의문이 있을 수 있음. 이게 정말 어려운 모델을 대신해서 설명할 수 있나? 서로 작동방식이 같다고 할 수 있나? 만약 서로 틀리면?

그 다음은 데이터 자체를 이해하는 것. 데이터 시각화를 통해서든 기존의 지식을 통해서든.

차원이 별로 없다면 시각화를 통해 특징을 알아낼 수 있음. 하지만 차원이 너무 많아지면 쓰기 힘들고 서로간의 영향은 파악하기 힘듬.

SAHP라는게 있는데 고차원에서 분석하려고 나온 방법론인듯. 다양한 곳에서 쓸 수 있지만 어려움.

모델의 weight를 통해 파악하는거. gradcam 같은거인듯. 픽셀별로 gradient 변화를 파악한다. 쉽긴한데 이렇게 해서 설명하는게 모델이 작동하는 방식을 설명하는거랑 같은걸까?랑 너무 의지하지 말자인듯.
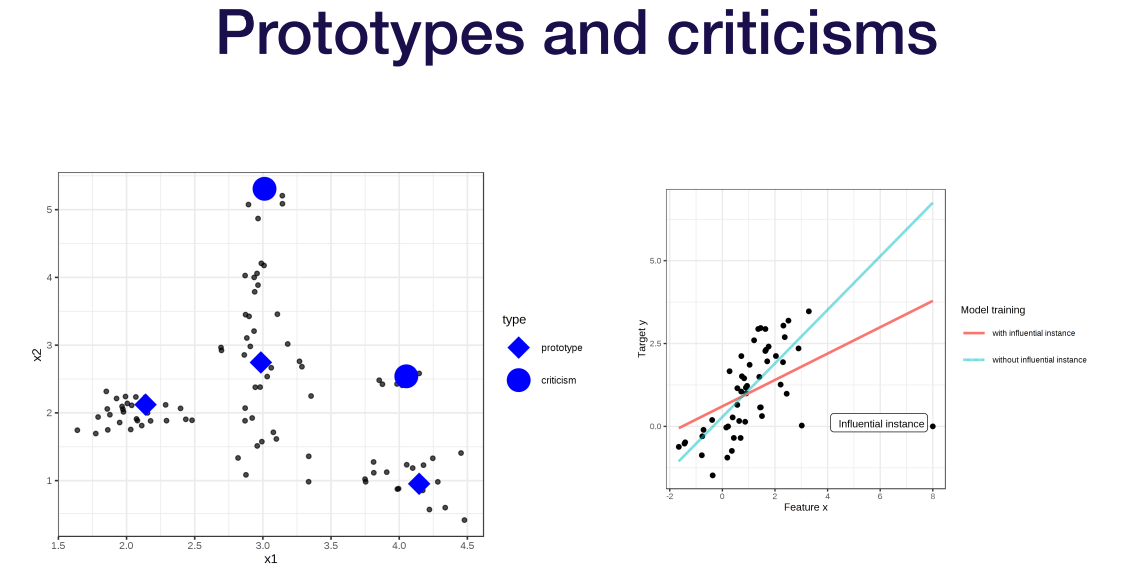
또 데이터 각자를 이해하는 것보다는 데이터 분포를 전체적으로 이해하는 게 있음. 저기 분류된 데이터 종류 중 하나가 통채로 날아가면 큰 영향을 줄것임. 위에서 본 다른 것들이 유용하지 않게 되면 고려할 필요가 있다.

근데 다시 돌아가서.. 왜 설명가능해야 할까?
일단 우리가 위에분들한테 '이 모델은 설명 가능합니다!' 라고 했을 때 '그게 뭔 뜻인데?'라고 물어본다. 그럼 설명할 수 있어야 함.
또 사용자가 원할 때도 있음. 예를 들면 AI가 재판을 한다던가 하는 중요한 판결을 내릴 때 그 판단이 정확하더라도 왜 정확한지를 알고자 하는 욕구가 강할 수 있음. 걍 내고 끝나면 납득할 수 있는 사람이 얼마나 될까. 그래서 유저가 원할 때가 있음.
또 내가 안심이 됨. 결과가 잘 안나올 때 데이터가 잘못된건지 모델이 잘못된건지 확신할 수 없을거임. 또 시각화 할 때나 디버깅 할 때도 도움이 됨.

근데 애초에 모델을 설명한다는게 가능한가? 전문가들은 별로라고 함. 위에서 설명했던 방법들이 실제 모델과 연관이 없을 수도 있고, 불안하고, 모두 설명을 못해준다. 이렇게 줄줄히 설명했는데도 걍 참고용으로만 써야 하는 듯 하다.

결론은 내가 만약 모델을 정말 이해하고 설명 가능하게 만들어야 한다. 이게 너무 중요하다. 싶으면 그 집군의 모델로 만들어라. 위에서 설명했던 linear나 regression 같은거.
또 설명 가능한게 흥미있는 결과가 나와도 그게 정말인지 믿을 순 없다. 최근엔 모델이 설명 가능하게 하는 것 자체가 목적인 모델을 만들어 훈련하던데, 이렇게 목적이 설명하게끔 만든 모델은 원래 원했던 진짜 성능까지는 장담하지 못하게 될 수 있음.
SHAP, LIME 같은거 사용하면 좋고, 설명 가능하게 하면 디버깅 하는데도 좋다.
'강의 > fullstackdeeplearning_spring' 카테고리의 다른 글
| Lecture 11: Deployment & Monitoring / Monitoring (0) | 2022.05.08 |
|---|---|
| Lecture 11: Deployment & Monitoring / Deployment (0) | 2022.05.01 |
| Lecture 9: AI Ethics (0) | 2022.03.21 |
| Lecture 8: Data Management (0) | 2022.03.20 |
| Lecture 7: Troubleshooting Deep Neural Networks (0) | 2022.03.12 |