https://fullstackdeeplearning.com/spring2021/lecture-11/
Full Stack Deep Learning
Hands-on program for software developers familiar with the basics of deep learning seeking to expand their skills.
fullstackdeeplearning.com

대부분은 모델 만들줄만 알지, 어케 배포하는지는 모를거다.

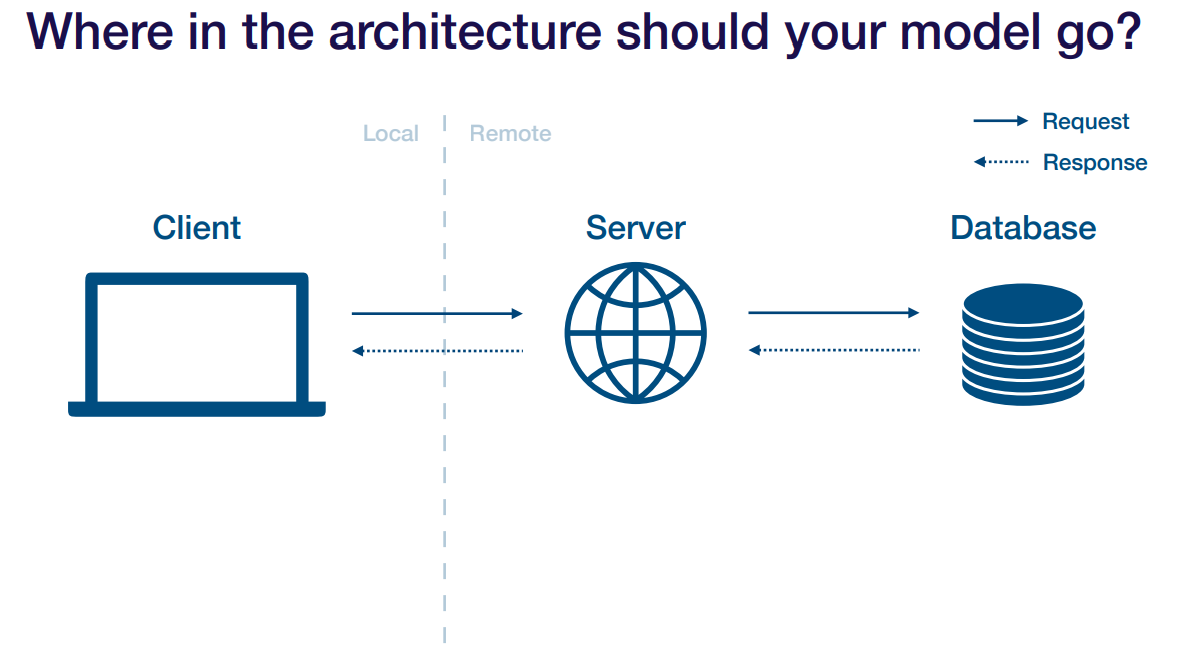
이런 환경에 있다고 치자. 모델을 어디다 둘 건가

데이터베이스에 두는거를 batch prediction 이라고 함.
모델을 돌려 결과를 데이터베이스에 cache로 저장하는 거다. 유저 하나당 예측해야 되는 양이 작을 때 쓸 수 있음. 추천시스템에서 쓰는 듯.

장점과 단점은 생각해 볼수 있는 것들이다. 장점은 모델 예측이 얼마나 걸리든 결과가 cache에 있기 때문에 빠르고 간편하다는 것. 단점은 복잡한 작업은 못하고, 과거에 저장된 결과를 불러오기 때문에 낡은 결과를 받는 다는 것.

그럼 서버에 두는게 어떻겠냐
웹서버에다가 모델을 넣고 요청이 있을 때마다 weight를 불러오든 해서 모델을 돌려 결과를 주는거임.

이런 방식은 기존에 훈련하던 때와 비슷해서 바로 사용하기 쉬움. 하지만 엄청난 단점들이 있어서 흔하게 쓰는 것은 아니다(거의 안씀).
단점들은 일단 웹서버를 돌리는 언어랑 모델 돌리는 언어랑 다를 수 있음. 웹서버는 node로 돌리는데 모델은 python으로 돌린다던지. 그럼 번역해주는 과정이 필요함. 그리고 웹서버는 한번 만들어두면 잘 안바뀌는데 모델은 반나절, 하루에 한번 재훈련을 한다고 하면 그때마다 서버를 다시 재시작 해야되고, 유저가 많아져서 크기를 키울 때 웹서버랑 모델 둘 다 커지겠지만 모델이 너무 커져서 웹서버를 잡아먹기 쉬움. 성능 다 뺏어먹고 하는 듯. 또 웹서버를 돌리는 하드웨어에 gpu가 있을리 만무함.

그 다음은 서버랑 모델이랑 따로 둬서 서로 의사소통 하는 방식. 서버 2개를 두는 듯.
이 방식을 매우 흔하게 쓰는 듯 하다.

장점은 서로 독립적이라 어디에서 오류가 나도 다 터지지 않는다는 점, 각자 따로 두기 때문에 각자 최적화 할 수 있다는 점, 재사용이 쉽다고 한다. 단점은 여러번 소통해야 하니 지연시간이 좀 있고, 인프라 구성에 좀 복잡함. 모델 서비스도 만들어야 하고..
이 방식을 한다고 가정하고 설명할거임.
그래서 모델 서비스를 알아본다.


REST APIs는 평소에 주고받을 때 쓰던 GET POST 같은거. 구글에서 대체품으로 GRPC 라는게 있고 서버용 GraphQL이 엄청 뜨고 있지만 ml과는 크게 관련없는 듯.
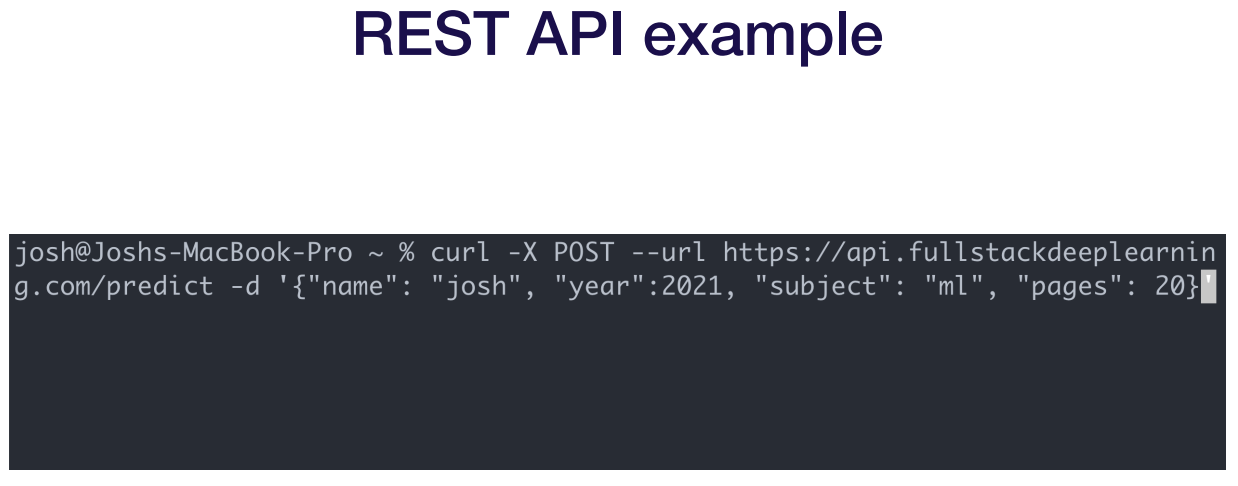

요청을 http로 보내면 결과를 json 형식으로 받는다던지 함. 문제는 정해진 형식이 없다는 거임. 그래서 저 위의 3개의 예시 중 하나로 하던가 본인이 이해 가능하게 정하면 됨.

다음은 dependency management. 코드랑 모델 weight는 커도 저장된걸 불러오고 하면 되기 때문에 큰 문제는 안됨. 제일 문제는 dependencies 문제임. 코드 돌릴 때 library 버전 잘못되서 실행 안되고 있는게 그거 말하고 있음.
이게 진짜 문제인데, 모델을 업데이트 했는데 특정 library가 새로운 버전으로 바꿔달라 해서 바꿨더니 다른곳에서 에러나고 우후죽순... 심지어 tensorflow나 pytorch인데도 버전 업데이트 했더니 오류 생기고 하는 문제가 있음. 작전은 내가 유지시키기... 랑 컨테이너 쓰기.

내가 유지시키는건 ONNX라는 포맷이 있음. 이 프로젝트 목적이 다른 프레임워크로 쓰여진 수 많은 모델들을 하나의 정형화 된 모델로 바꾸는 거기 때문에 언어 상관없이 변환시킬 수 있음. 문제는 예를들어 tensorflow만의 특정 layer가 onnx로 변환이 안될 수도 있고 얘내 변화가 너무 빠르다 보니 버그가 있을 수 있음.
또다른 dependency 해결책인 container를 알아보자.

container에 대표적인게 docker랑 virtual machine이 있음. 근데 뒤에 설명하는게 docker만 설명하는거 보면 걍 docker쓰는거인듯.
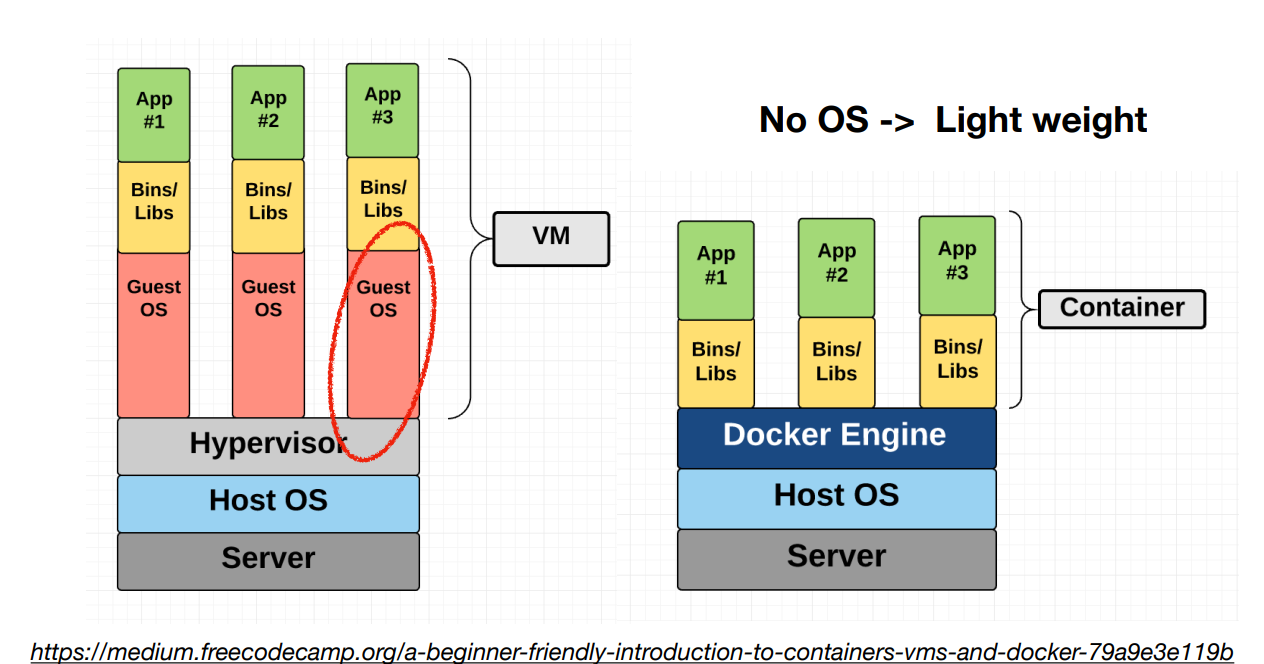
docker 개념. virtual machine과 다른점은 OS는 복사 안한다는거. docker 내부 구조들만 복사해서 가져옴. 이게 docker container.

docker container는 가볍고 각자가 독립적이기 때문에 상호작용도 쉽다고 함. 그래서 웹서버용 container, ml모델용 conainter, 어쨋든 모두 container로 만들고 서로 독립적으로 실행하고 서로 정보 주고받을 수 있다.

docker container 만들 때 사용하는 dockerfile. 왼쪽은 python 2.7. 어디서 실행할지 어떻게 실행할지 pip같은거 설치해주고 만들면 됨. 주고받는건 Docker Registery가 있는데 이걸 통해 container끼리 주고받으면 된다. 이렇게 container끼리 독립적으로 있어서 어느 특정 container에서 dependency를 업데이트 해도 다른 독립적인 container를 망가뜨리지 않는다.

강력한 ecosystem이라 했는데 특정 환경을 구축하기 정말 쉬운 듯. github처럼 container 모아둔 장소가 있고 내가 원하는 것만 pull해서 사용하면 됨. 개조하는 것도 dockerfile에서 버전을 다른걸로 쓴다던지 프레임워크를 다른걸 쓴다던지 하게 변형한 다음 container로 저장해서 나도 만들어 쓸 수 있고. private도 쉽다고 함.

상호작용 얘기했는데 컨테이너끼리 상호작용은 container orchestra 라고 부름. 웹 서버용 container 따로 있고 모델용 container 따로 있고 서로 독립적인데 얘내들끼리 서로 정보 주고받으며 시스템을 만들 수 있게 도와주는 것들이고 그 중 하나가 구글의 kubernetes임. 아직 배우는 단계라면 docker 자체에서 지원하는 docker compose도 있지만 현재 쿠버네틱스가 좋기 때문에 뒤에서 설명해줄거임.

그 다음은 Performance optimization. 서버 빠르게 실행하기. 위 질문들은 시작하기 좋은 것들.

gpu냐 cpu냐. gpu는 기존에 gpu용으로 작성했을 테니 쉬울거고 batch size가 클 때 대처가 쉬울거다. 단점은 설정이 복잡할거고 무엇보다 비쌈. 현재는 gpu보단 cpu로 하는게 보통이라 cpu를 쓴다고 가정하고 설명할거임.

동시성은 gpu의 장점이 동시성인데 이를 안사용하고 cpu로 했을 시 동시성을 어케 사용할 수 있을까? 바로 모델의 복사본을 여러개 가지고 돌리는 거임? 어떻게냐면 멀티쓰레드. 저 블로그 글이 모델을 잘 돌리기 위한 최소한의 쓰레드를 가져가자는 내용임. 즉 너무 무리하게 쪼개면 독립적으로 작용해야 할 게 서로 영향을 미쳐서 성능이 낮아지는 듯.

얘는 걍 아는거니까 넘어감. 링크에 어떻게 하면 정확도를 덜 낮주면서 작게할까 고민한 글인듯.

얘도 넘어가는데 개념은 사이즈를 줄여서 속도를 높이겠다. 이미 양자화를 안다는 상태에서 학습시켜서 정확도를 높히자는 글.

캐싱은 평소보다 자주 사용되는 입력에 대해서는 결과를 미리 저장해놨다가 같은게 들어오면 모델을 돌리는 대신 저장된 결과를 꺼내는 방식. 캐시메모리와 같은 방식으로 작동하는 듯. 파이썬에는 내장함수로 @cache를 지원하기도 하니 더 간편

gpu는 병렬처리에 강점이 있고 batch는 이 병렬처리를 작용시키는데 중요한 역할을 함. 그래서 어차피 모델이 batch size로 받으니까 입력이 batch size만큼 모이길 기다렸다가 한번에 넣어서 몰델에 넣고 결과가 나오면 각각 알맞은 유저에게 결과를 주는거임. 이러면 맨 처음에 입력한 유저는 오래 기달려야 해서 다른 shortcut이 필요하다는거. 이건 직접 코드 짜기엔 힘들고 지원해주는 라이브러리를 쓰는게 좋겠다.

이건 뭐냐면 강사가 개인적으로 널리 상용화 되었으면 하는 바람인 방법으로, 여러개의 모델이 하나의 gpu를 사용하는 거임. 이게 뭐냐면 gpu 성능을 100% 안쓰는걸 쓰게 하려고 하는 방법론으로 위에서 batch size가 모이길 기다리는 동안은 gpu를 안쓰고 유저 입력 지연을 감소시키려고 gpu를 100% 쓰도록 batch size를 모으지 않았는데도 출력시킨다. 그러면 gpu를 100% 못쓰니까 성능이 아깝다. 그래서 모으는 동안 다른 모델의 연산을 실행하거나 하는 방식으로 최대한 활용하자. 직접짜진 말고 최근엔 이런걸 지원하는 라이브러리도 생기는 추세라고 함.

위에서 말한 지원해주는 라이브러리들. tensorflow랑 pytorch도 자기만의 serving 지원하는게 있음. ray는 독자적으로 나온거고. nvidia도 지원하려고 하는데, nvidia는 특히 gpu끼리 상호작용 하는거를 지원하는거 같음.

그 다음은 horizontal scaling. 이건 하나의 컴퓨터에서 처리를 하려고 하는데 traffic이 너무 많아서 못돌리는 경우. 여러개로 나눠서 돌릴 순 없을까? 가장 간단한 방법은 모델 복사본 가지고 여러개 돌려서 traffic 균형을 맞추는 거. 가장 실전적인건 걍 aws 지원해주는걸 쓰던가 쿠버네틱스, 서버 없이 사용하는게 있다.

3번째에 Container Deployment에서 확대된게 하나의 container인데, 저 각각에 대한걸 쿠버네틱스가 알아서 모아서 처리해준다.

얘를 또 해주는 KFServing이나 selden 같은게 있다는게 뭐라는지 모르겠음. 써봐야 알듯.

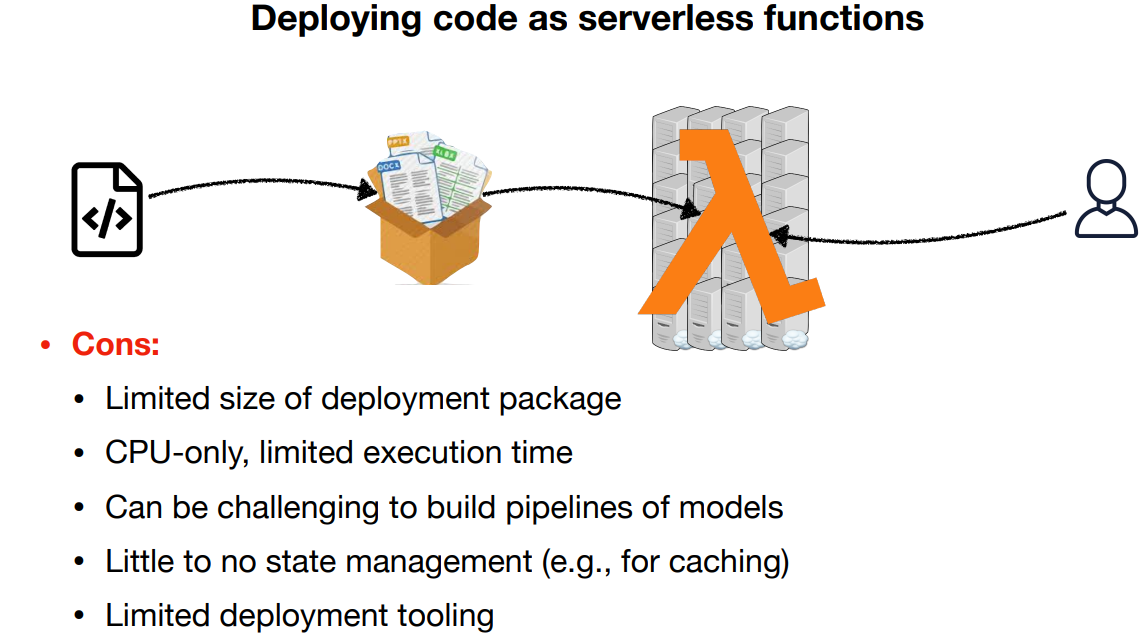
다음 서버가 없는 aws의 lambda. 서버가 없다면 서버가 다운 될 일이 없다는 기막힌 발상이다. 입력 양이 얼마든 간에 수요를 늘리면 aws lambda가 알아서 처리함. 원래는 .zip으로 해야 했지만 최근 docker container도 지원. 돈을 처리시간 만큼만 쓰기 때문에 자원적인 면에서도 유리. 단점이라면 크기는 알아서 조절 되긴 하지만 gpt3 같은 개무식하게 큰건 안되고 cpu만 사용 가능. 그래서 모델 inference할 때는 문제 없겠지만 그 외에는 못씀. 파이프라인 구축하는데 좀 힘들거고 다른 방법들은 못씀.

model deployment는 지금까지 얘기한건 serving인데 serving은 모델한테 입력주고 결과가 나오게 하는걸 어떻게 만드는지 알려주는 거였다면 deployment는 그렇게 만들어진 시스템을 관리하고 업데이트 하는거. 새로운 모델이 나왔다면 교체하는 방식. 이것도 새로운 모델과 기존 모델을 병렬적으로 돌리는걸로 시작해 점차 비율을 새로운 쪽으로 늘리는 듯. 이런 코드 작성도 바닥부터 할 필요는 없고 라이브러리에서 지원해준단다.

다음은 managed options. 위에서 말했던 container고 serverless 고 뭐고 다 모르겠다! 걍 쓰고싶다고! 하면 다행히도 대기업들과 스타트업에서 지원해주는게 있음. 비싸도 뭐..

최종 정리. cpu 쓸꺼면 serverless가 좋고 gpu쓸거면 서빙 툴 쓰는게 좋고, gpu를 지원해주는 스타트업도 고려대상임.

그 다음은 클라이언트에 모델을 직접 넣는거. 잘 안쓰고 추천하진 않지만 수업이니까 알아두기는 하자인듯. 컴퓨터든 모바일이든 기계든 해당 컴퓨터에 넣고 돌린다.

장점은 지연시간은 당연히 없고 인터넷 없어도 되고 유저 사생활 보호에 좋다. 너무 큰 단점들은 지원할 수 있는 하드웨어가 제한적이고 이런 embeded 제품에서 tensorflow와 pytorch 만큼 지원하는건 적을거고, 업데이트는 어떻게 할것이며 디버그 또한 힘듬.

얘내를 지원하려는 TensorRT, apache TVM, TFLite, PyTorch Mobile, Tensorflow.js, 다른 툴들까지 있음. 모바일이나 웹에 돌리고 싶으면 저런거 쓰라고~. 아님 지원해주는 툴들.

이런 애들을 모바일에 돌리고 싶다면 모델 자체를 더 효율적으로 만들던가 모바일 친화적인 모델을 쓰자. MobileNet 같은거. nlp에선 distillBERT 등.

강사가 모바일이나 자율주행 같은 edge prediction에 종사하는사람에게 물어보고 얻은 말들. 최적화를 너무 많이 하려면 머리아프다고 하고, 처음에 모델을 선정할 때부터 고려한다고 함. 성능이 1순위이긴 하지만 베이스라인을 맞출 때 지연시간을 둠. 그래서 새로운 모델 선정은 지연시간 같은걸로 판단. 자율주행 같은 경우 까딱 잘못하면 사고나니까 위험성이 더 크고. fallback은 반응시간이 너무 느릴 경우 대비책같은 거인듯.

edge deployment의 결론. web deployment가 쉬우니 특정 목적이 있는거 아니면 쓰지 말자. 쓴다면 처음부터 이건 모바일 같은 하드웨어에 쓴다는걸 염두하고 프로젝트를 시작해야 되고, apache TVM 쓰는걸 추천.
'강의 > fullstackdeeplearning_spring' 카테고리의 다른 글
| Lecture 11: Deployment & Monitoring / Monitoring (0) | 2022.05.08 |
|---|---|
| Lecture 10: Testing & Explainability (0) | 2022.04.30 |
| Lecture 9: AI Ethics (0) | 2022.03.21 |
| Lecture 8: Data Management (0) | 2022.03.20 |
| Lecture 7: Troubleshooting Deep Neural Networks (0) | 2022.03.12 |